

データサイエンス100本ノック関連記事リスト
📄![]() 【001 全項目を指定行数抽出する】 Python in Excelで始めるデータサイエンス100本ノック!
【001 全項目を指定行数抽出する】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【002 特定の列を抽出する】 Python in Excelで始めるデータサイエンス100本ノック!
【002 特定の列を抽出する】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【003 指定列の列名を変更する】 Python in Excelで始めるデータサイエンス100本ノック!
【003 指定列の列名を変更する】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【004 特定条件に合致する行を抽出(=、>、<)】 Python in Excelで始めるデータサイエンス100本ノック!
【004 特定条件に合致する行を抽出(=、>、<)】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【005 複数条件に合致する行を抽出する①】 Python in Excelで始めるデータサイエンス100本ノック!
【005 複数条件に合致する行を抽出する①】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【006 複数条件に合致する行を抽出する②】 Python in Excelで始めるデータサイエンス100本ノック!
【006 複数条件に合致する行を抽出する②】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【007 複数条件に合致する行を抽出する③】 Python in Excelで始めるデータサイエンス100本ノック!
【007 複数条件に合致する行を抽出する③】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【008 特定条件に合致しない行を抽出する(!=)】 Python in Excelで始めるデータサイエンス100本ノック!
【008 特定条件に合致しない行を抽出する(!=)】 Python in Excelで始めるデータサイエンス100本ノック!
1️⃣ はじめに
- この連載企画では、データサイエンス100本ノックをDockerとPython in Excelで実行する方法を比較しながらご紹介しています。 📖Python in Excelとは?

Python in Excelは、Excel上で直接Pythonのコードを実行できる話題の新機能です。
- 2023年8月に、パブリックプレビュー版が発表されました。
- 現在は、Microsoftの一定のバージョン以降でMicrosoft 365 insidersプログラムに参加し「Beta Channel」を選択することで利用が可能です。
- Python in Excelでは、ExcelにPython実行環境である「Anaconda」が組み込まれています。
- 新しい関数である「PY」関数を使って、セルにPythonプログラムを書き込むと、クラウドでPythonプログラムを実行することができます。
- Python向けの各種ライブラリとして、Pandas や Matplotlib、seaborn を使えば、データの整形やグラフ化ができたり、scikit-learn を使用すれば機械学習やデータからの予測などの機能を利用できます。
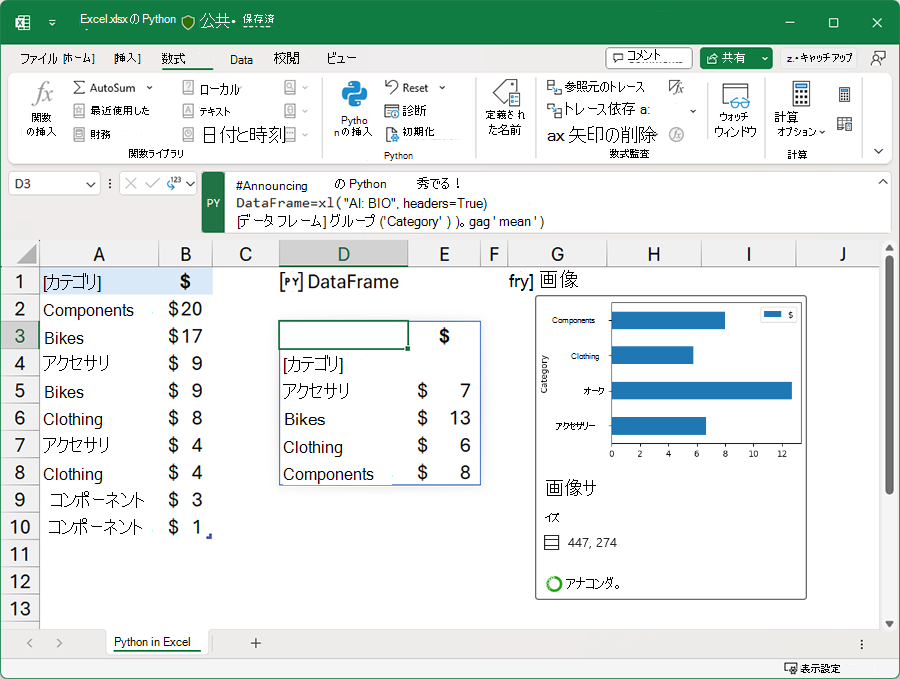
- それでは早速、演習問題002 特定の列を抽出するにチャレンジしてみましょう!
2️⃣ データサイエンス100本ノックの紹介
- データサイエンス100本ノックは、実践的でワクワクするような課題に取り組みながら、プログラミング、データ分析のスキルを楽しく習得することを目指した、データサイエンス初学者のための問題集です。 📖「データサイエンス100本ノック(構造化データ加工編)」とは具体的に?
データサイエンス初学者を対象に、データの加工・集計、統計学や機械学習を駆使したモデリングの前処理等を学べるように、データと実行環境構築スクリプト、演習問題がワンセットになったコンテンツのことです。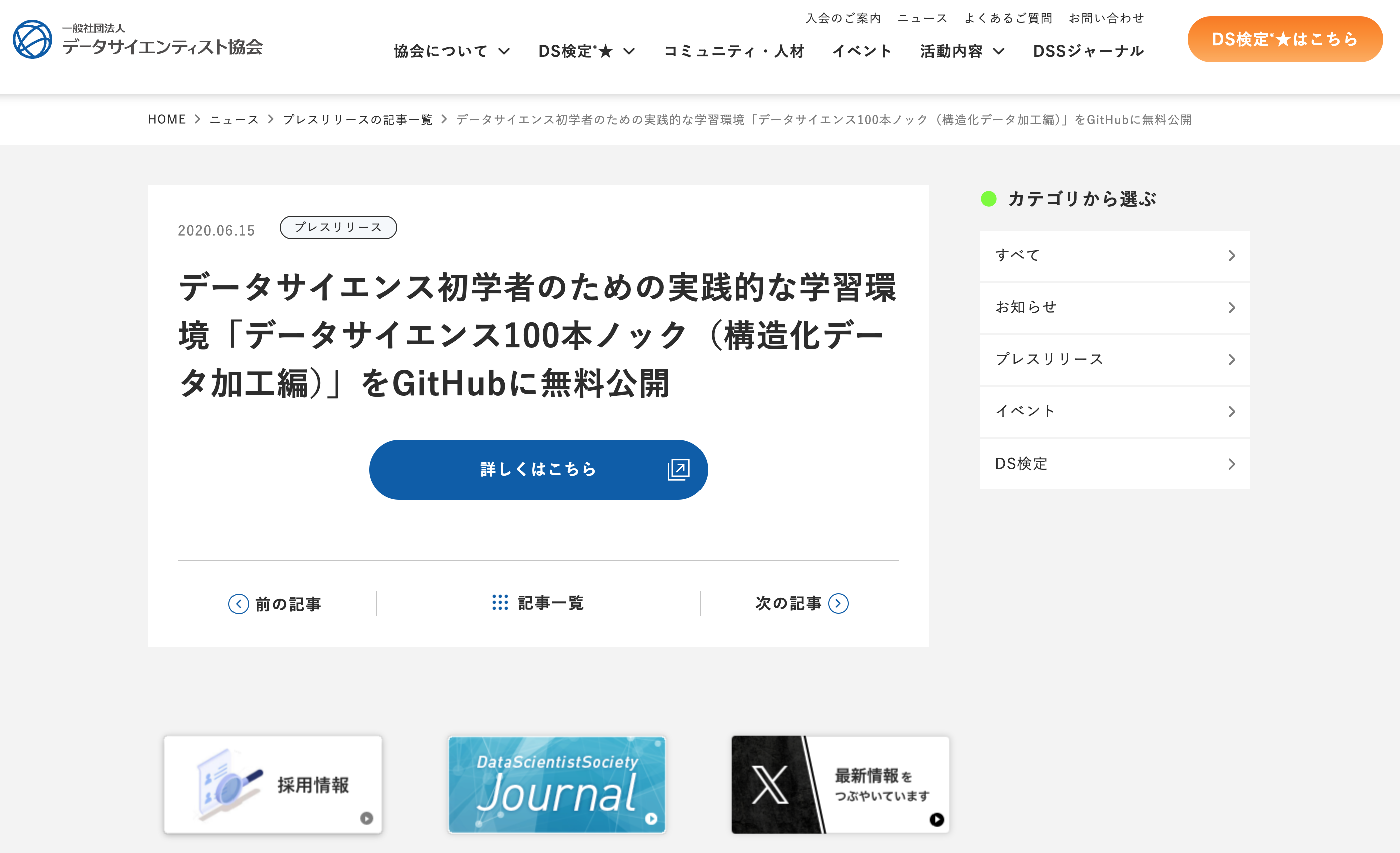
「データサイエンス100本ノック(構造化データ加工編)」 概要
- アクセス:GitHub(無料公開)
- 実行環境のサポート言語:SQL、Python、R
- 演習問題:各言語の設問100問
- 解答例:各設問に対する解答例のファイルを用意
3️⃣ Docker上で実行
- まず、Dockerコンテナ上で立ち上げたJupyter環境で実行していきます。
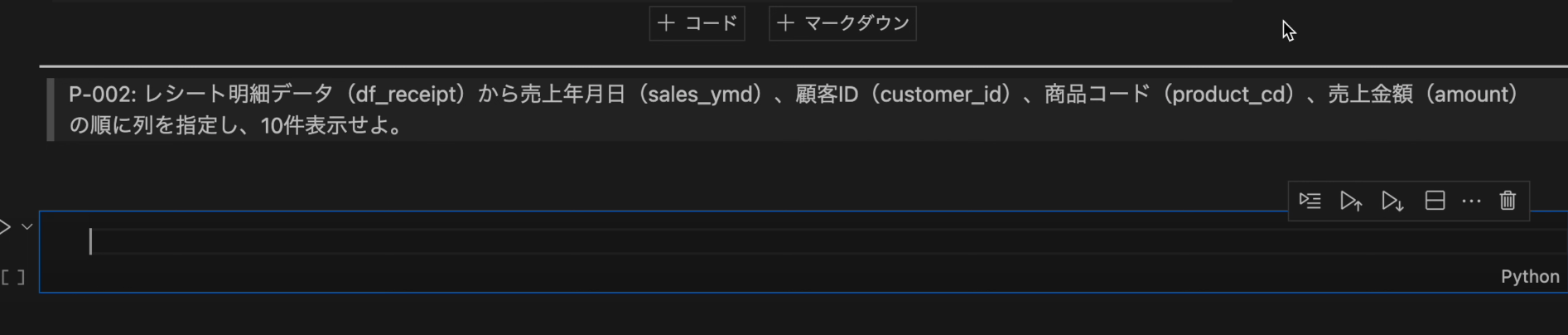
- レシート明細データ(
df_receipt)から売上年月日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示せよ。
- 一番初めのセルでレシート明細データのCSVファイルを
df_receiptという変数に読み込む処理をしています。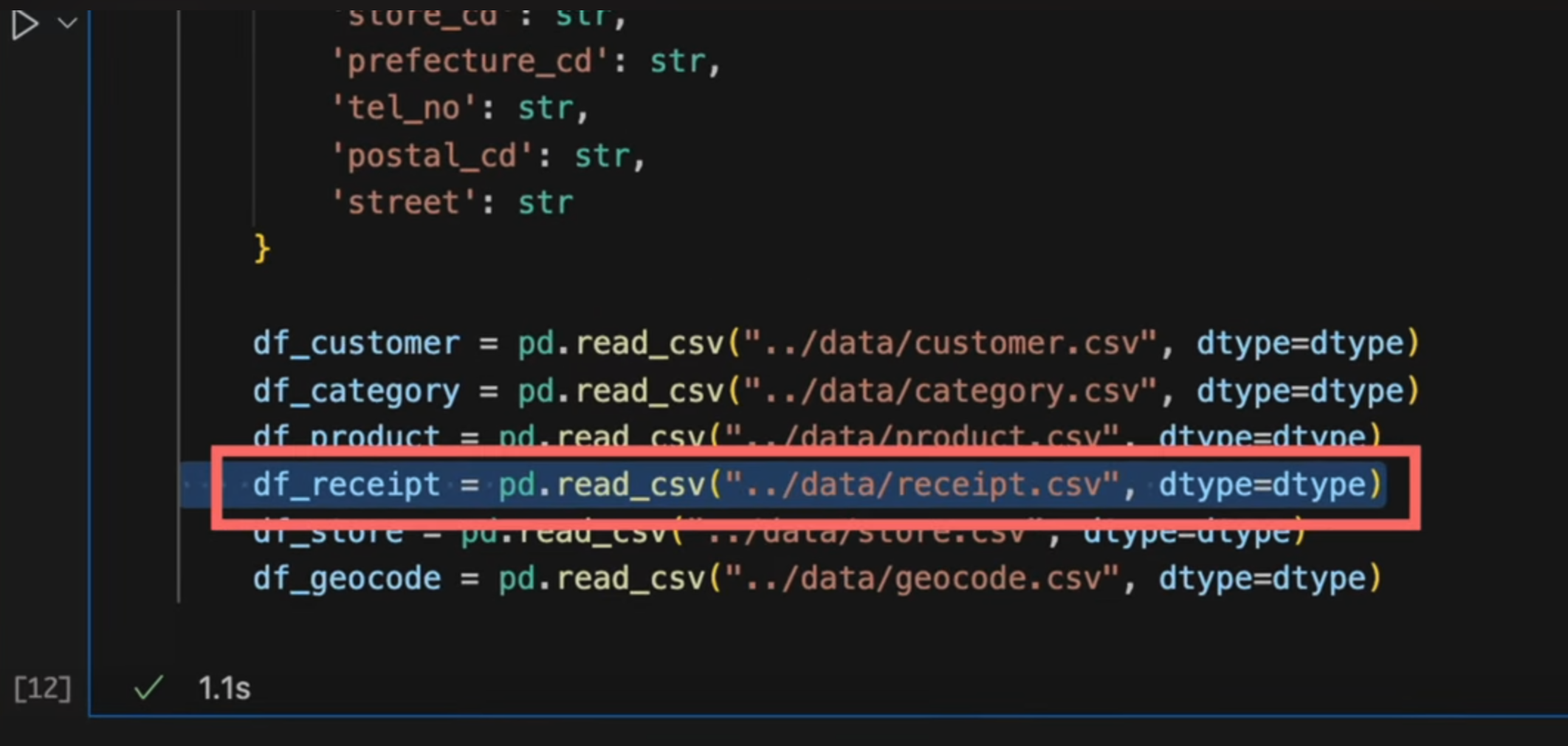
- 読み込んだ
df_receiptから表示する列を指定して、headメソッドを使うことで、先頭のデータを表示できます。 -
pandasのDataFrameで特定の列を選択する場合、角括弧[]を使用して列の名前を指定します。
- まず、例として一つの列を指定してみます。
df_receiptに続けて角括弧を入力し、sales_ymdという文字列をシングルクォーテーションまたはダブルクォーテーションで挟んで入力します。df_receipt['sales_ymd'] -
Ctrl + Enterで実行します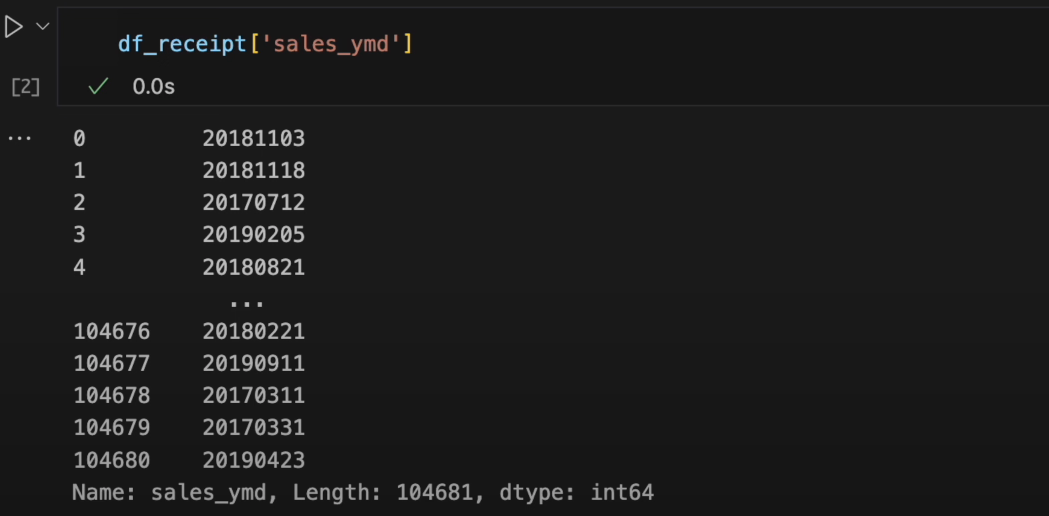
sales_ymdの列が表示されました。 - 続いて、複数の列を指定する場合は、列名のリストを角括弧
[]内に入れます。角括弧
[]の中に要素を格納することでリスト型のデータを作成できます。 -
columnsという変数にリストを代入し、df_receiptの角括弧[]の中に指定します。columns = ['sales_ymd', 'customer_id', 'product_cd', 'amount'] df_receipt[columns]
-
Ctrl + Enterで実行します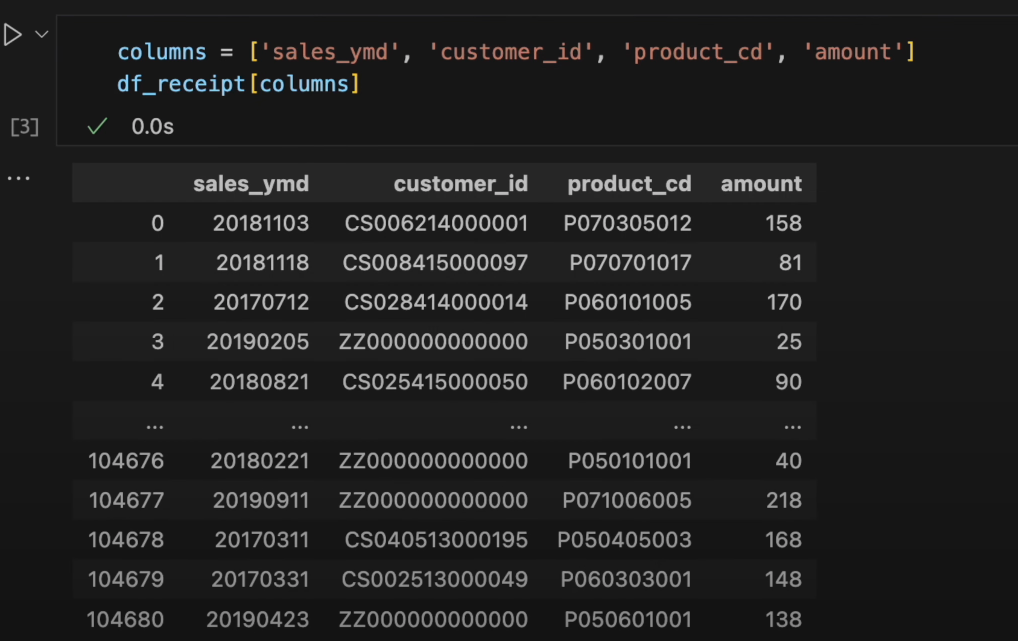
複数の列を指定してデータを出力できました。
- 最後に取得したい行数をhead()メソッドで入力します。
columns = ['sales_ymd', 'customer_id', 'product_cd', 'amount'] df_receipt[columns].head(10) -
Ctrl + Enterで実行します。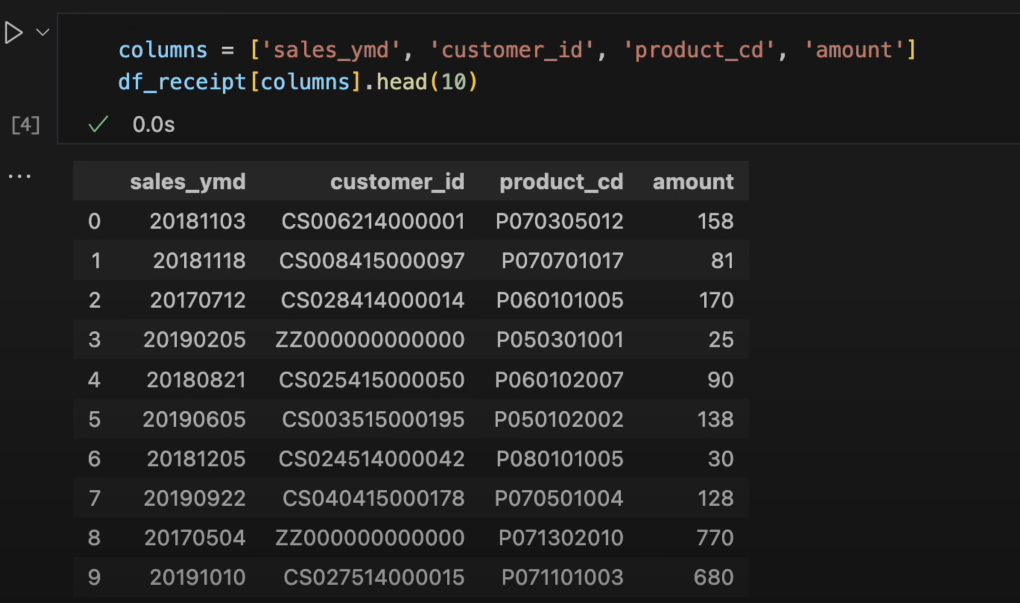
データを10件表示することができました。
SeriesオブジェクトとDataFrameオブジェクトの違いについて-
DataFrameから列を選択するとき、単一の列を選択すると一次元のデータ構造であるSeriesオブジェクトが返され、複数の列をリストで選択すると二次元のデータ構造であるDataFrameオブジェクトが返されます。 - 今後の演習課題にも出てくるメソッドや関数の中には、
Seriesでのみ利用可能なmapやDataFrameでのみ利用可能なgroupby、merge、joinなどがあるため、SeriesとDataFrameの違いを何となくでも理解しておくと、エラーに躓きにくくなると思います。
-
-
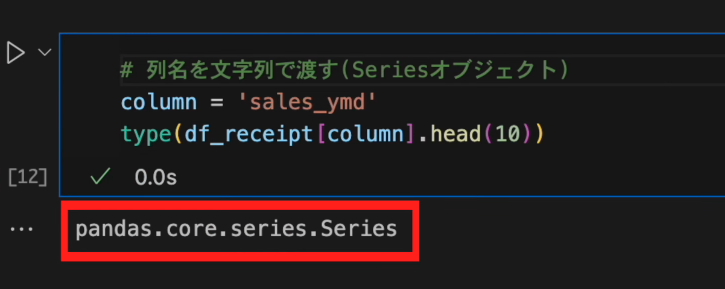
DataFrameから単一の列を指定する際に文字列で渡すとSeriesオブジェクトになります。# 列名を文字列で渡す(Seriesオブジェクト) column = 'sales_ymd' df_receipt[column].head(10)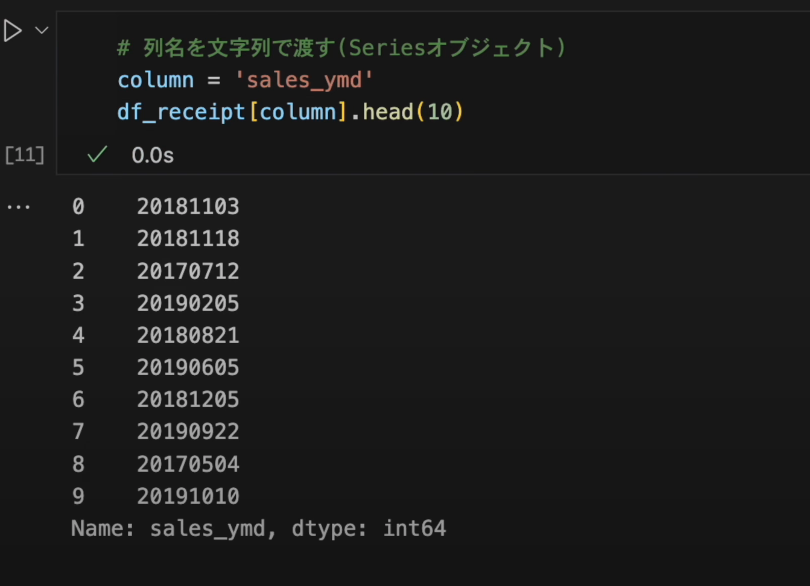
- 角括弧
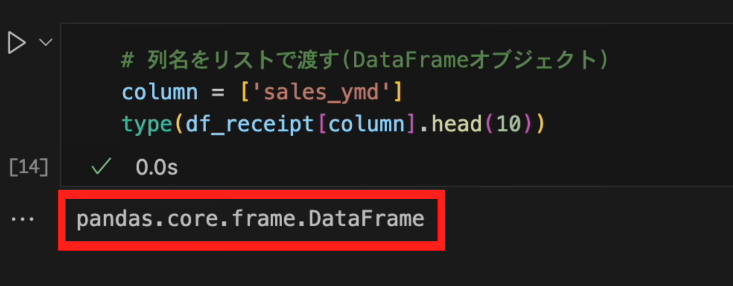
[]をつけてリストにして渡すとDataFrameオブジェクトになります。# 列名をリストで渡す(DataFrameオブジェクト) column = ['sales_ymd'] df_receipt[column].head(10)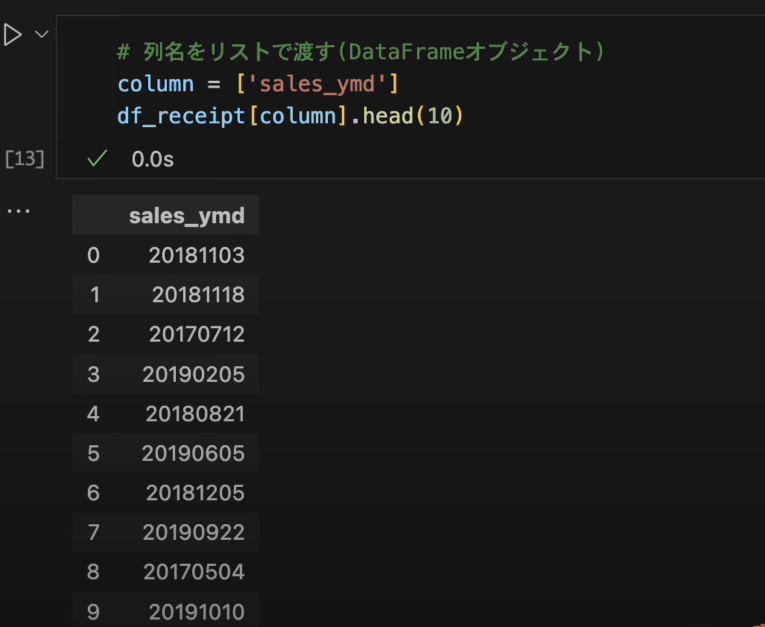
次はPython in Excelで確認します。
4️⃣ Python in Excelで実行
- レシート明細のCSVデータをExcelで開いています。
- データのダウンロードの方法はこちらの動画をご覧ください。
- 数式バーからPythonの挿入を選択します。
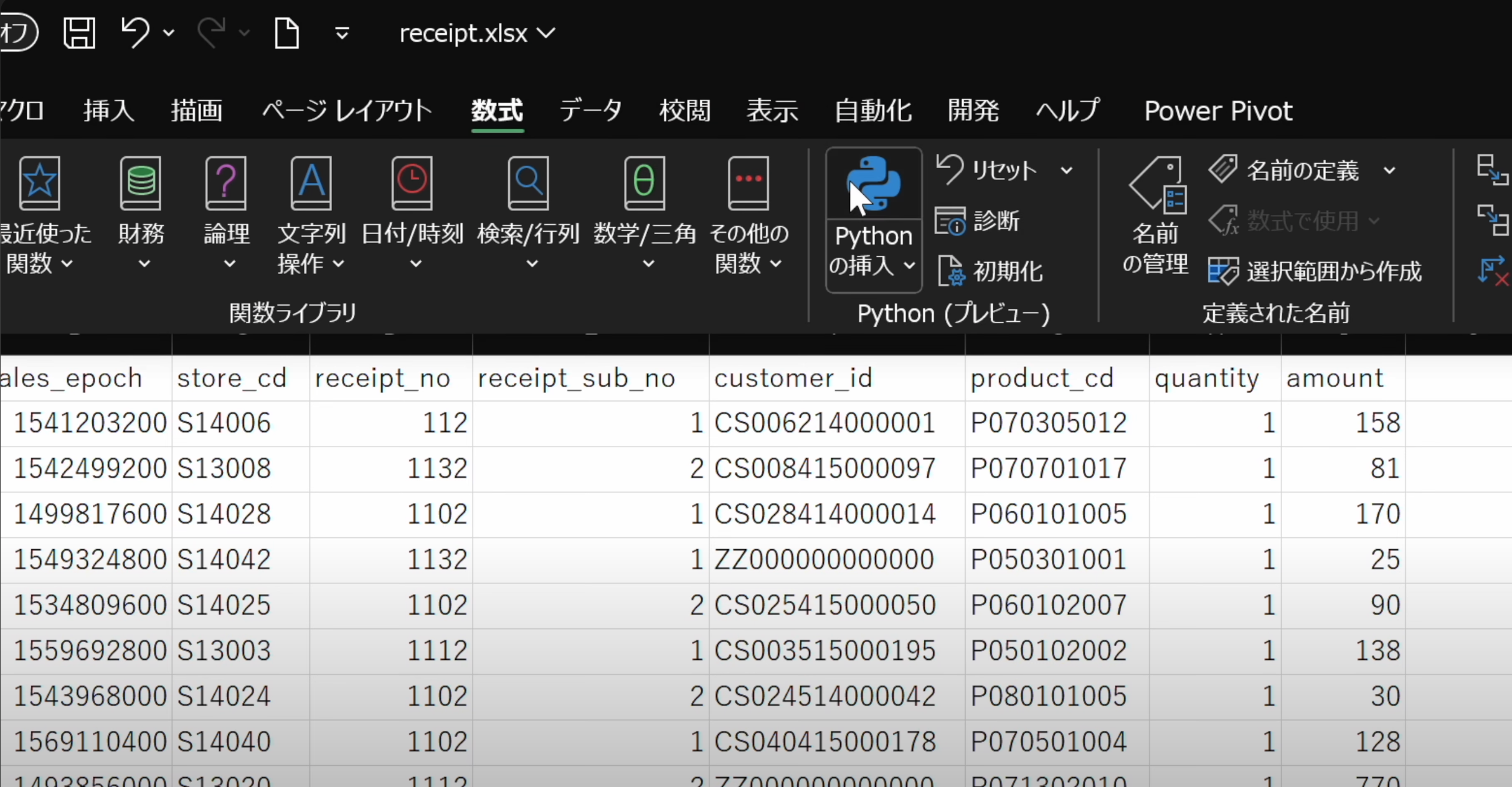
- Python in Excelを使って
DataFrameにデータを格納するにはセル範囲を選択します。列を指定するか、または表のセル範囲を指定します。
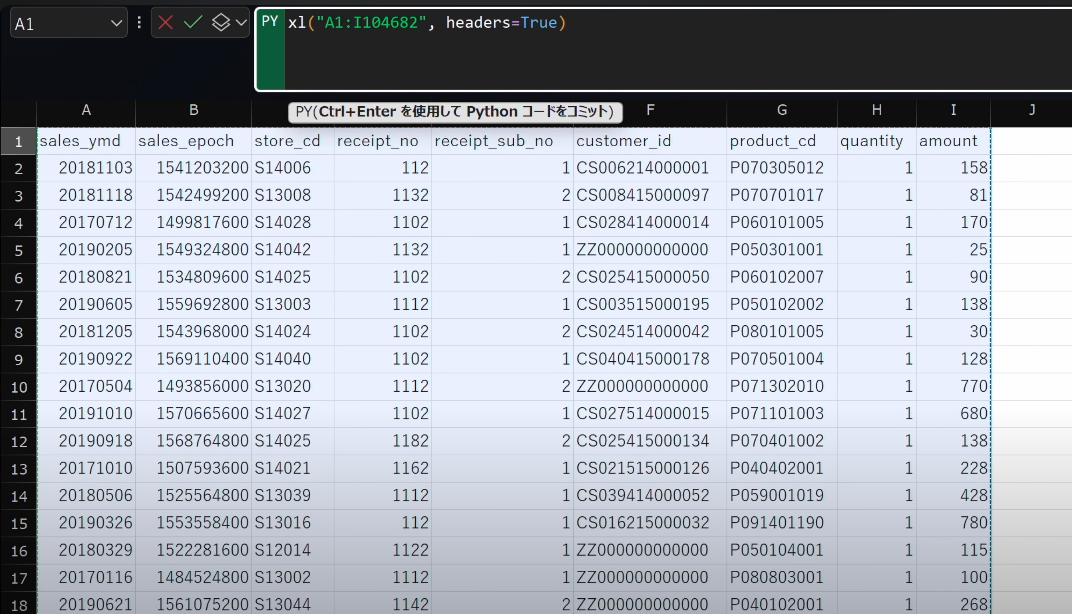
- 指定した範囲を
df_receiptという変数に格納します。df_receipt = xl("A1:I104682", headers=True)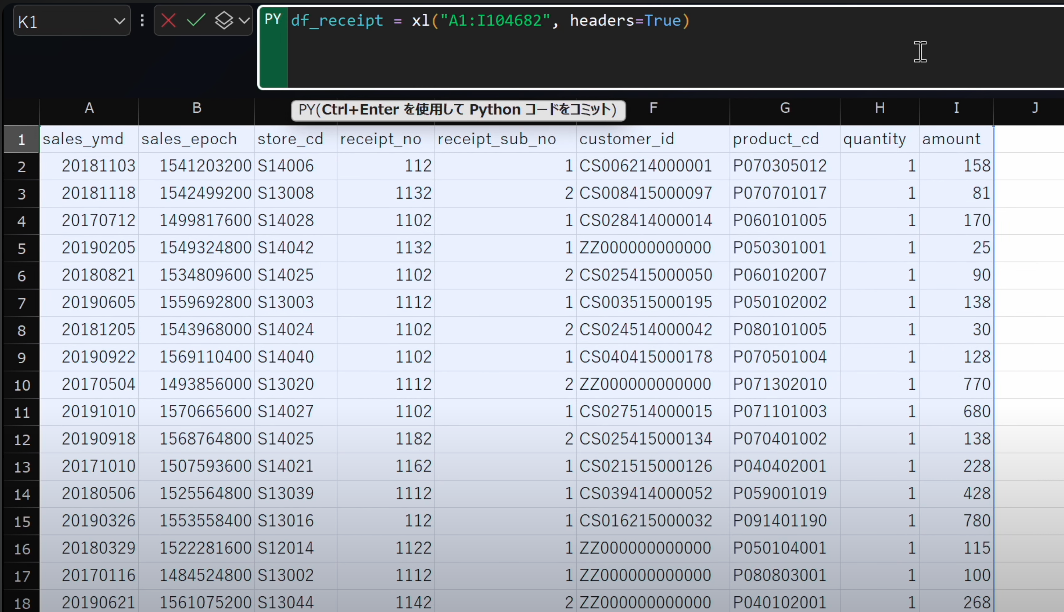
- 先ほどと同様に列名のリストを作成します。
df_receipt = xl("A1:I104682", headers=True) columns = ['sales_ymd', 'customer_id', 'product_cd', 'amount']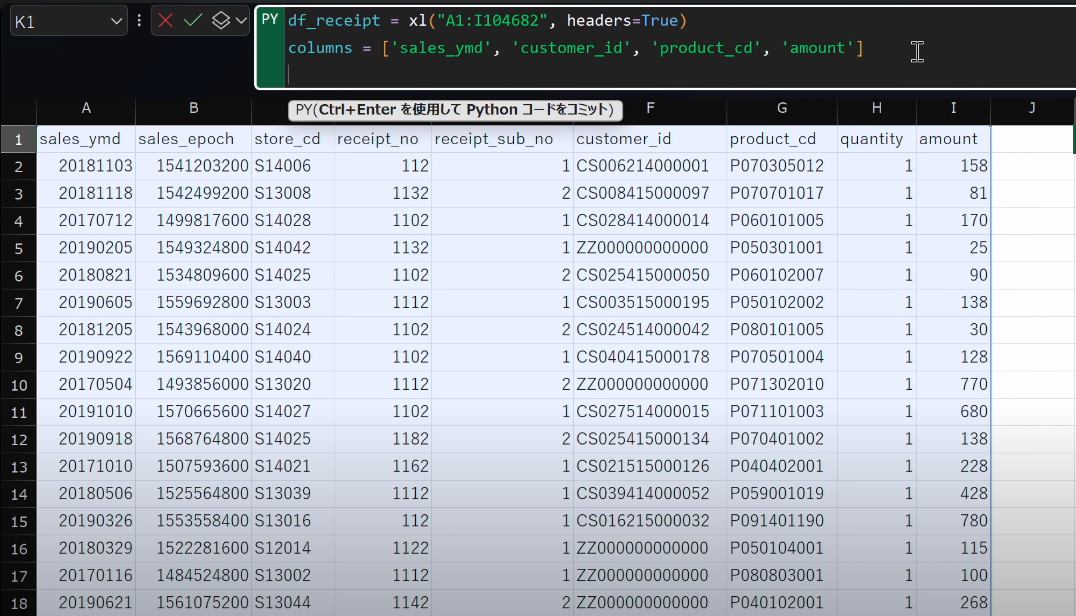
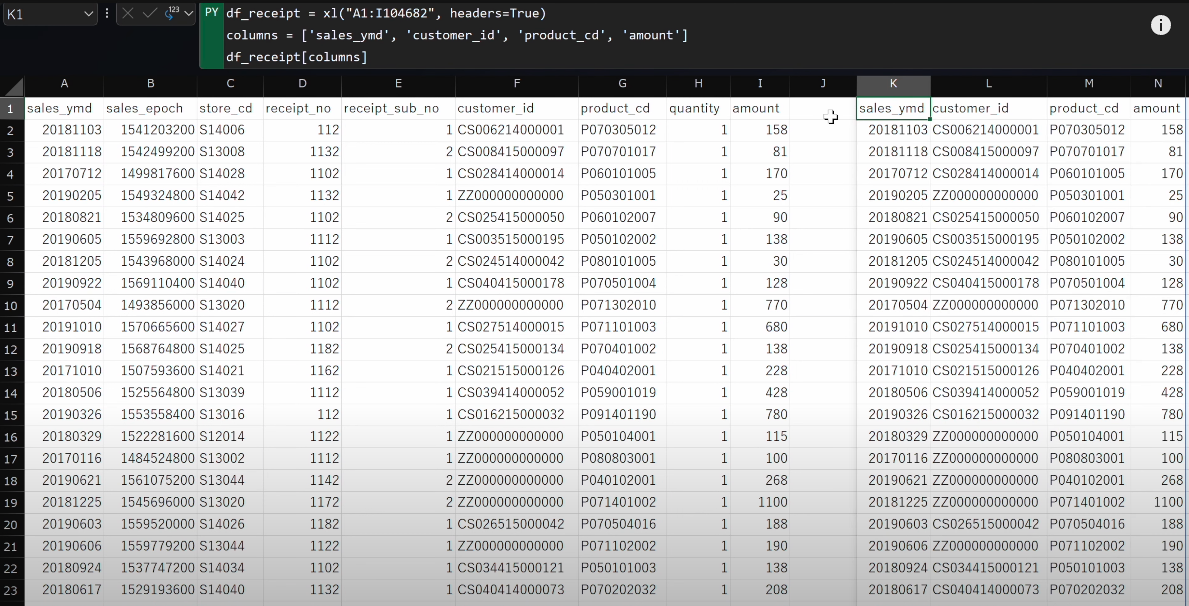
-
columnsという変数にリストを代入し、df_receiptの角括弧[]の中に指定します。df_receipt = xl("A1:I104682", headers=True) columns = ['sales_ymd', 'customer_id', 'product_cd', 'amount'] df_receipt[columns] -
Ctrl + Enterで実行。表示がDataFrameに変わりましたら、数式バー隣のプルダウンメニューをクリック、PythonオブジェクトからExcelの値に変更します。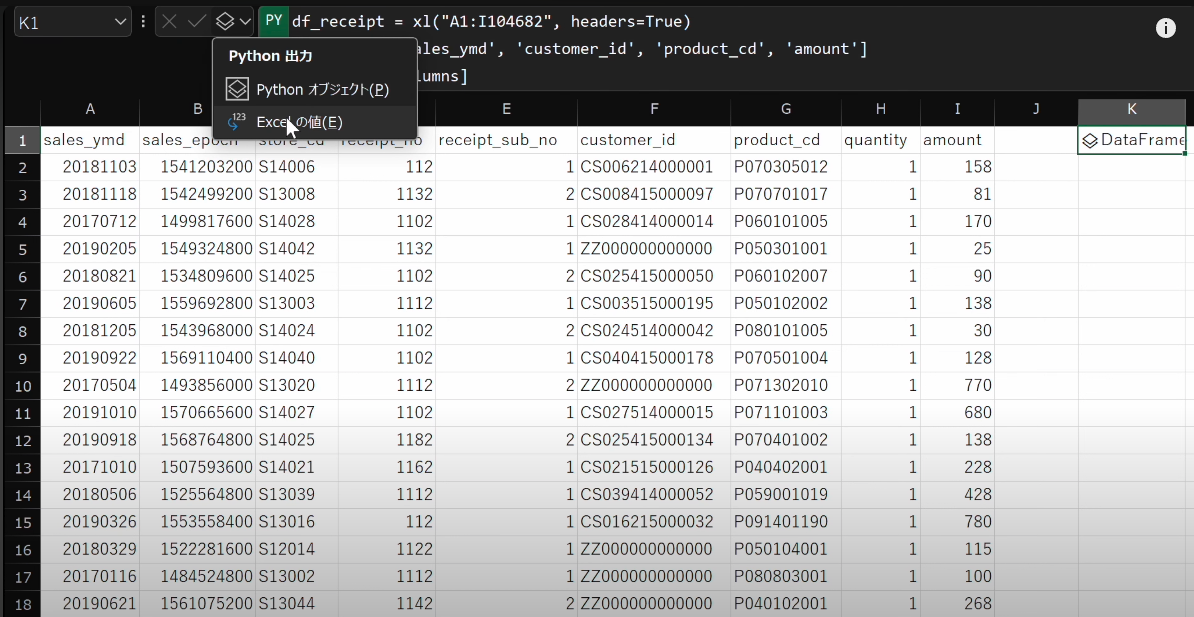
- 値が出力されました。
- 続いて
headメソッドを使用し、引数に10と入力します。df_receipt = xl("A1:I104682", headers=True) columns = ['sales_ymd', 'customer_id', 'product_cd', 'amount'] df_receipt[columns].head(10)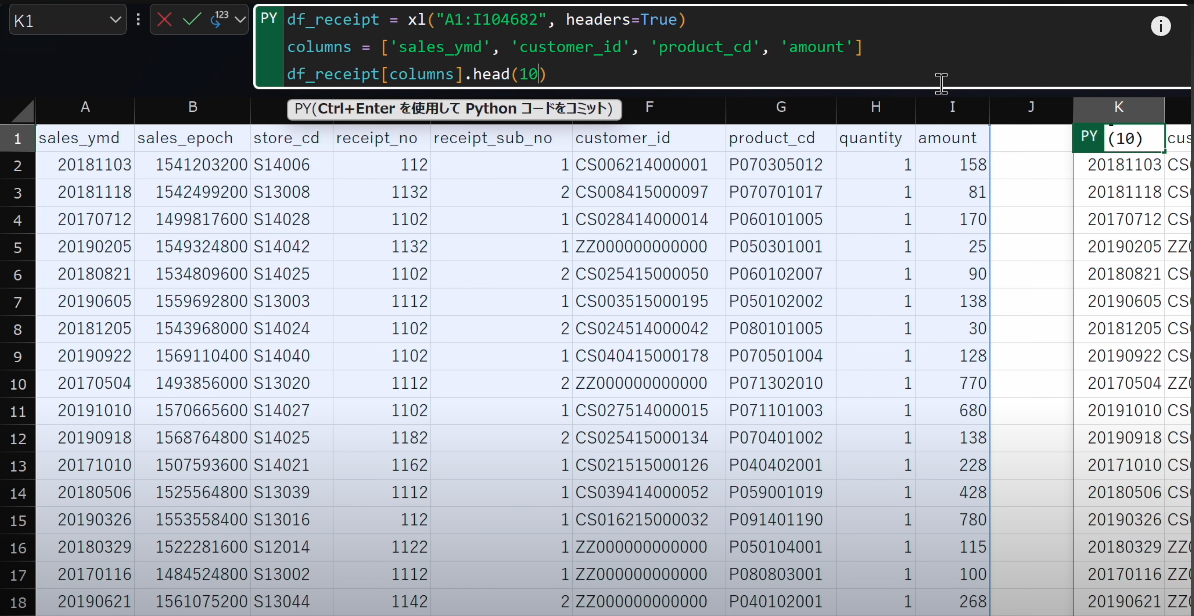
-
Ctrl + Enterで実行します。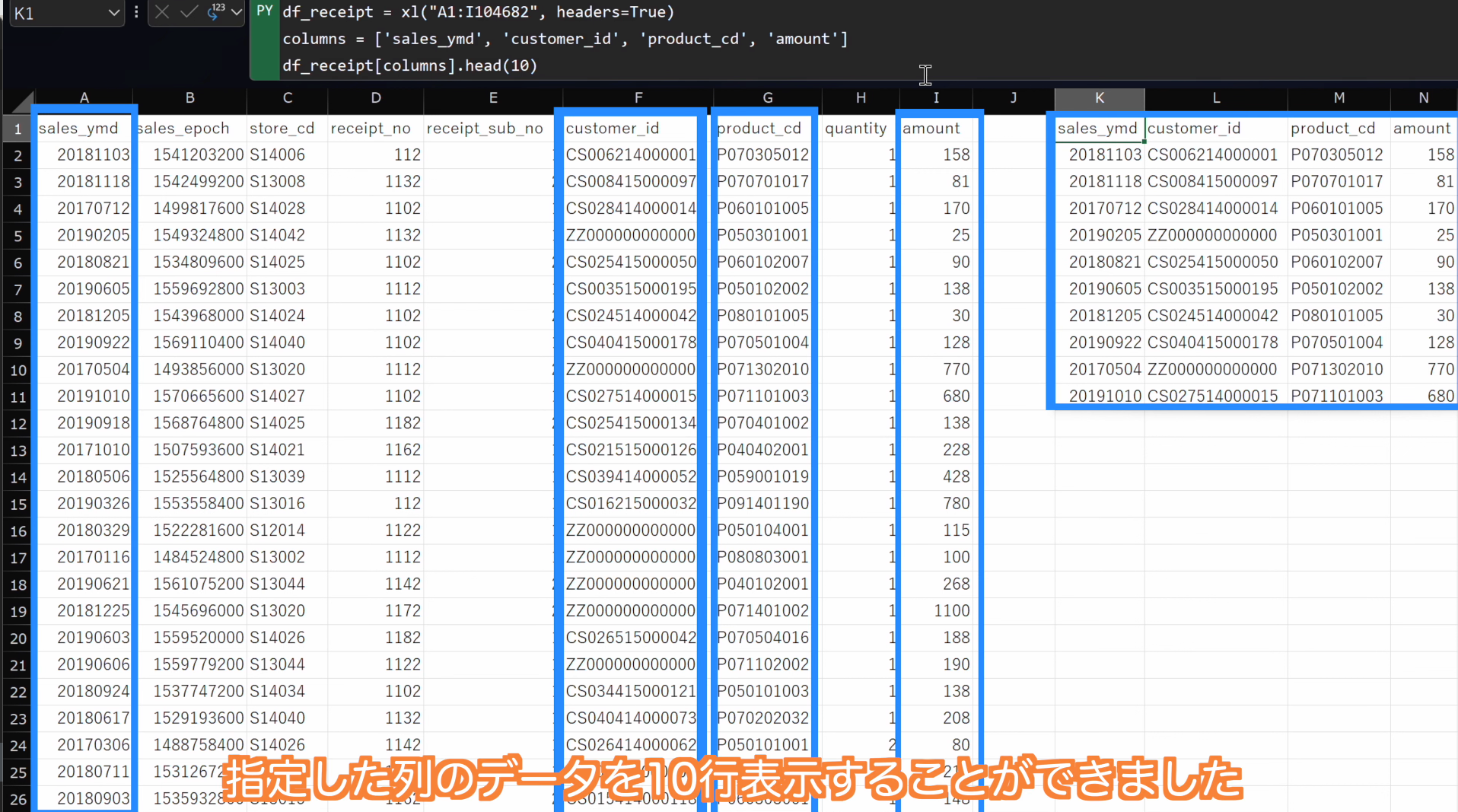
指定した列のデータを10行表示することが出来ました。
以上で、データサイエンス100本ノック演習問題002 特定の列を抽出するをクリアしました。
5️⃣ おわりに
- 最後までお読みいただきありがとうございます!
- この記事へのご質問やアドバイスがありましたら、ぜひコメントもお待ちしております。
- またXでもVBA、Pythonに関するアウトプットをしていますので、🔽フォローいただけますと幸いです😆