

データサイエンス100本ノック関連記事リスト
📄![]() 【001 全項目を指定行数抽出する】 Python in Excelで始めるデータサイエンス100本ノック!
【001 全項目を指定行数抽出する】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【002 特定の列を抽出する】 Python in Excelで始めるデータサイエンス100本ノック!
【002 特定の列を抽出する】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【003 指定列の列名を変更する】 Python in Excelで始めるデータサイエンス100本ノック!
【003 指定列の列名を変更する】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【004 特定条件に合致する行を抽出(=、>、<)】 Python in Excelで始めるデータサイエンス100本ノック!
【004 特定条件に合致する行を抽出(=、>、<)】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【005 複数条件に合致する行を抽出する①】 Python in Excelで始めるデータサイエンス100本ノック!
【005 複数条件に合致する行を抽出する①】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【006 複数条件に合致する行を抽出する②】 Python in Excelで始めるデータサイエンス100本ノック!
【006 複数条件に合致する行を抽出する②】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【007 複数条件に合致する行を抽出する③】 Python in Excelで始めるデータサイエンス100本ノック!
【007 複数条件に合致する行を抽出する③】 Python in Excelで始めるデータサイエンス100本ノック!
📄![]() 【008 特定条件に合致しない行を抽出する(!=)】 Python in Excelで始めるデータサイエンス100本ノック!
【008 特定条件に合致しない行を抽出する(!=)】 Python in Excelで始めるデータサイエンス100本ノック!
1️⃣ はじめに
- 今回から新シリーズとして、データサイエンティスト協会さんが提供されているデータサイエンス100本ノックをDockerとPython in Excelで実行する方法をご紹介していきます。 📖Python in Excelとは?

Python in Excelは、Excel上で直接Pythonのコードを実行できる話題の新機能です。
- 2023年8月に、パブリックプレビュー版が発表されました。
- 現在は、Microsoftの一定のバージョン以降でMicrosoft 365 insidersプログラムに参加し「Beta Channel」を選択することで利用が可能です。
- Python in Excelでは、ExcelにPython実行環境である「Anaconda」が組み込まれています。
- 新しい関数である「PY」関数を使って、セルにPythonプログラムを書き込むと、クラウドでPythonプログラムを実行することができます。
- Python向けの各種ライブラリとして、Pandas や Matplotlib、seaborn を使えば、データの整形やグラフ化ができたり、scikit-learn を使用すれば機械学習やデータからの予測などの機能を利用できます。
2️⃣ データサイエンス100本ノックの紹介
- データサイエンス100本ノックは、実践的でワクワクするような課題に取り組みながら、プログラミング、データ分析のスキルを楽しく習得することを目指した、データサイエンス初学者のための問題集です。 📖「データサイエンス100本ノック(構造化データ加工編)」とは具体的に?
データサイエンス初学者を対象に、データの加工・集計、統計学や機械学習を駆使したモデリングの前処理等を学べるように、データと実行環境構築スクリプト、演習問題がワンセットになったコンテンツのことです。
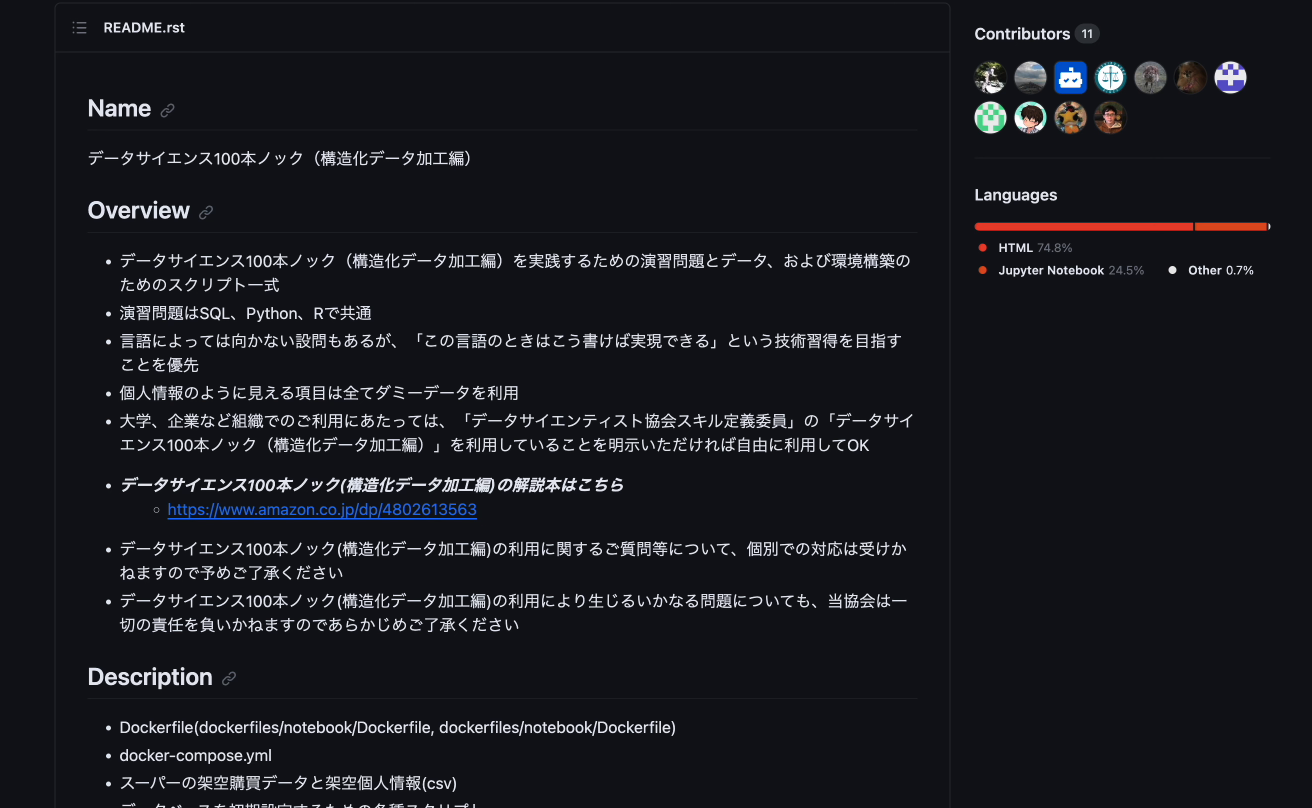
「データサイエンス100本ノック(構造化データ加工編)」 概要
- アクセス:GitHub(無料公開)
- 実行環境のサポート言語:SQL、Python、R
- 演習問題:各言語の設問100問
- 解答例:各設問に対する解答例のファイルを用意
- SQL、Python、Rの三言語を対象に実務でよく使うと思われるデータ加工や集計について段階的に学べる内容となっております。
一般的な実行環境としては、データサイエンティスト協会さんのGitHubリポジトリからgit cloneでプログラムをコピーし、docker compose up buildコマンドでプログラムを起動し、必要な準備を行い、Dockerコンテナ上でコードを実行していきます。
慣れている方ですと、READMEの手順に従って進めることで時間もかからずに環境構築が可能かと思います。
しかしながら、Pythonを学び始めた方やGitやDockerを学んだことがない方ですと、Pythonのコードを学ぶ以前に、最初の環境構築でつまづいてしまう可能性もあるかもしれません。
そこで、この連載企画では環境構築が不要で、リアルタイムにデータの確認が可能なPython in Excelを使ってデータ分析を行う方法をご紹介していきたいと思います。
せっかくですので、Dockerコンテナで実行する方法と比較しながらご紹介いたします。
- それでは早速、実行方法を確認演習問題001 全項目を指定行数抽出するにチャレンジしてみましょう!
3️⃣ Docker上で実行
- それでは、まずはDocker上でipynbを開いてみます。
こちらはDockerコンテナ上で立ち上げたJupyter環境をVSCodeから利用しています。

Dockerを使った環境構築の方法はリクエストがございましたら、改めて動画にしてみたいと思います。
- workディレクトリの配下にPython、R、SQLのnotebookがそれぞれ用意されていますのでPythonのnotebookを開きます。
- はじめにコードの中で利用する各種ライブラリをインポートするために最初のセルを
Ctrl + Enterで実行します。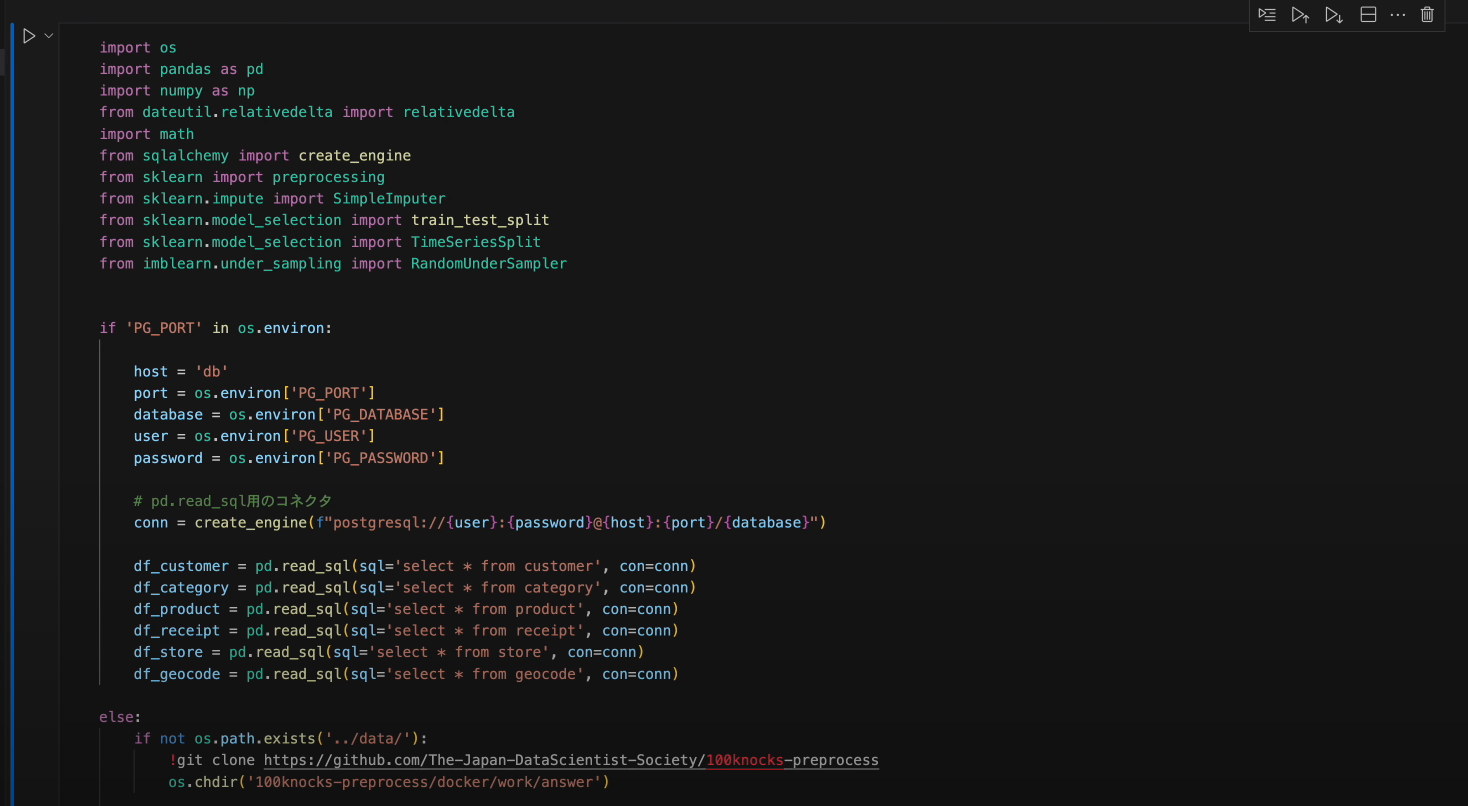
- レシート明細データ(
df_receipt)から全項目の先頭10行を表示し、どのようなデータを保有しているか目視で確認せよ。 データを扱う際にはまず、データの中身がどのようになっているかを確認する必要があります。
データを扱う際にはまず、データの中身がどのようになっているかを確認する必要があります。
- 先ほど実行した、一番初めのセルでCSVファイルを読み込む処理をしています。
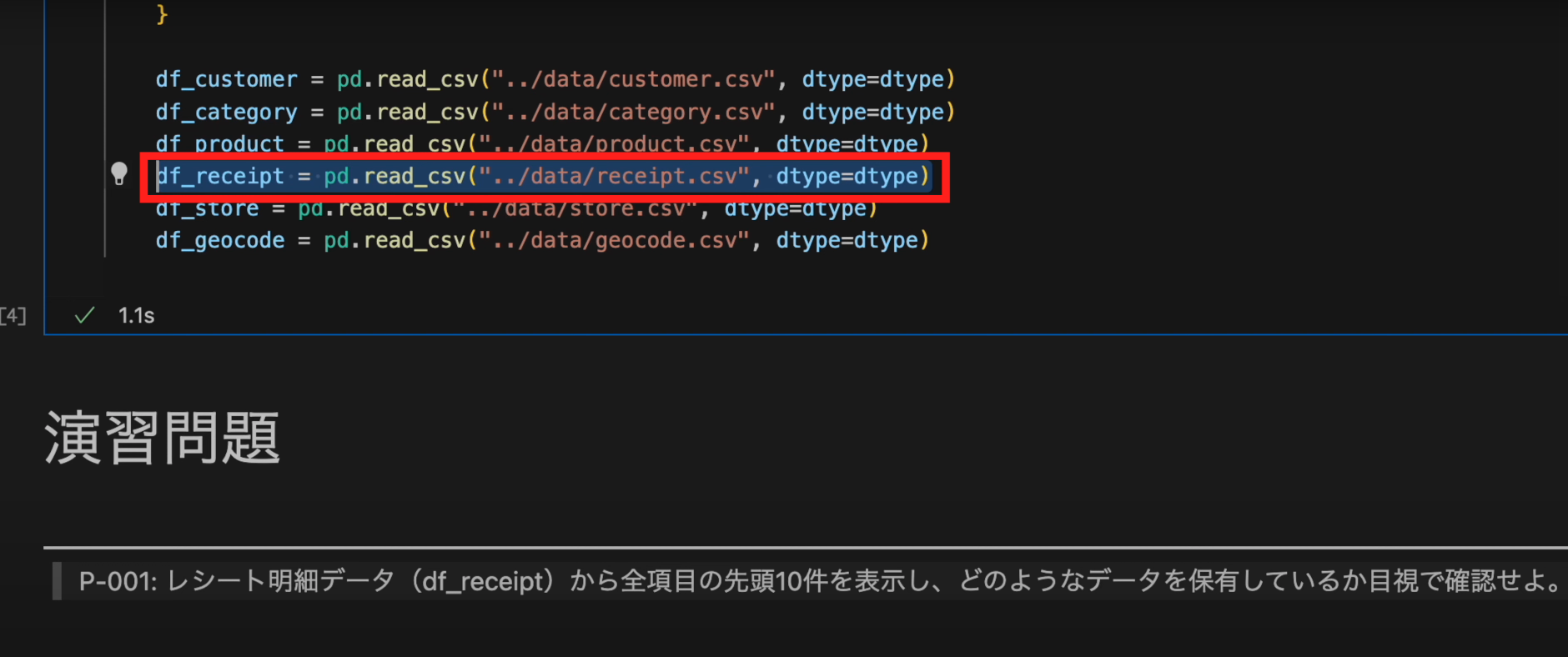
- 読み込んだ CSVファイルからPandasの
headメソッドを使うことで、先頭のデータを表示できます。取得したい行数を引数に与えます。
df_receipt.head(10)
-
Ctrl + Enterで実行します。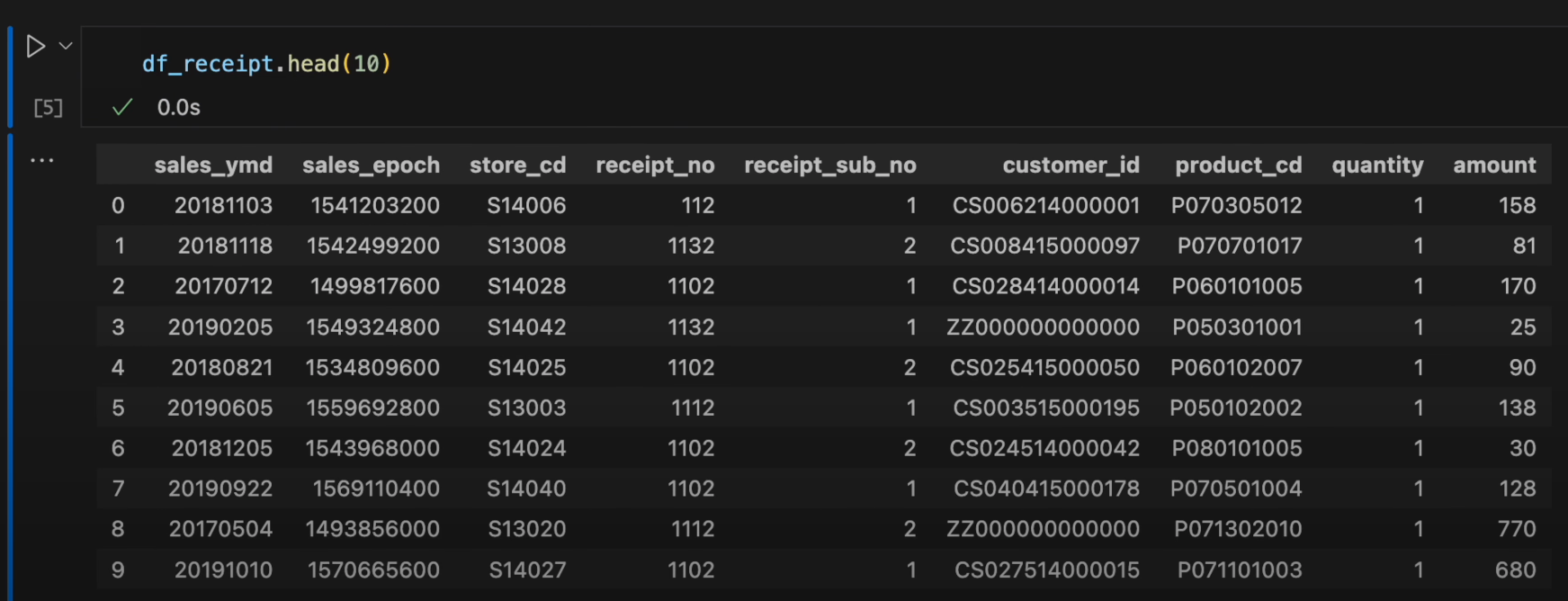
先頭の10行が出力されました。
- ちなみに、引数に何も与えないとデフォルトで5行表示されます。
df_receipt.head()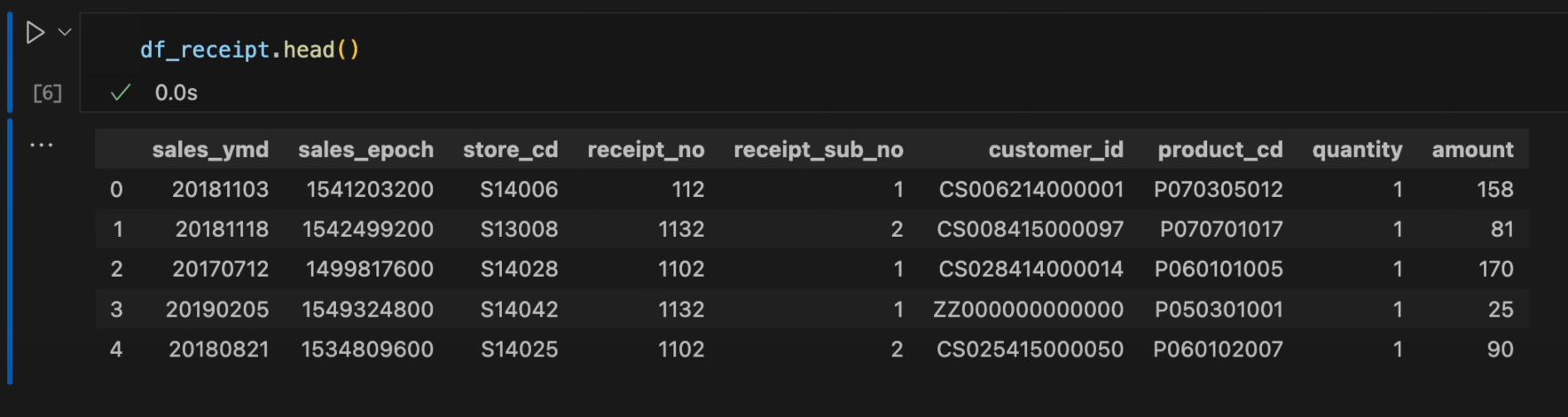
- また、末尾のデータを表示する場合は
tailメソッドを使用します。df_receipt.tail()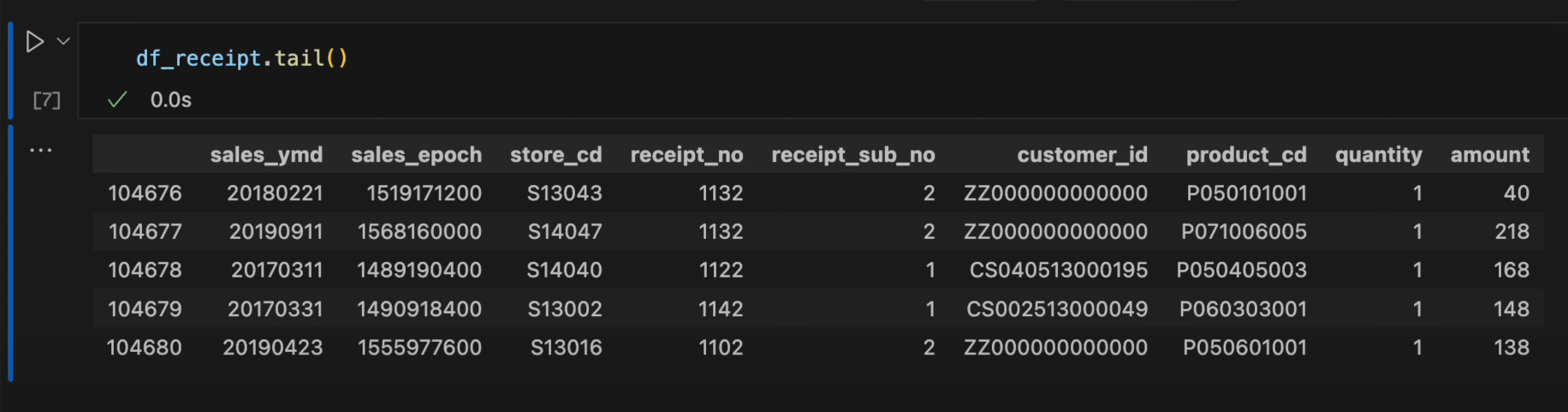
次はPython in Excelで確認します。
4️⃣ Python in Excelで実行
- まずはGitHubからデータをzipでダウンロードします。
- CodeのプルダウンメニューからDownload Zipを選択。
- zipファイルを展開し、レシート明細のCSVデータ(
receipt.csv)をExcelで開きます。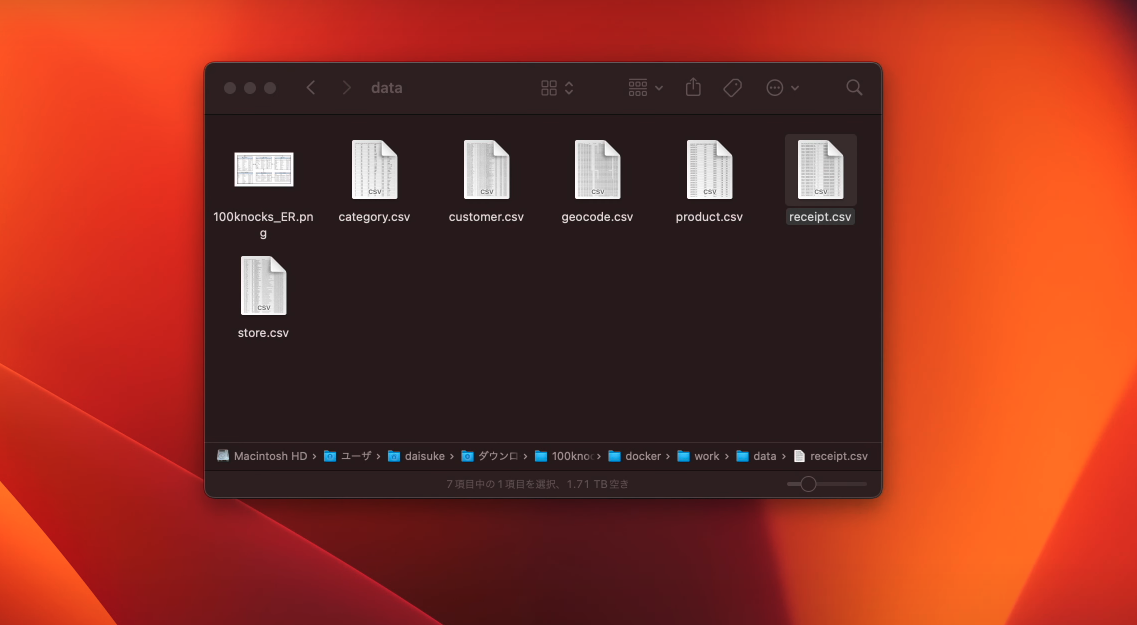
- 数式タブからPythonの挿入を選択
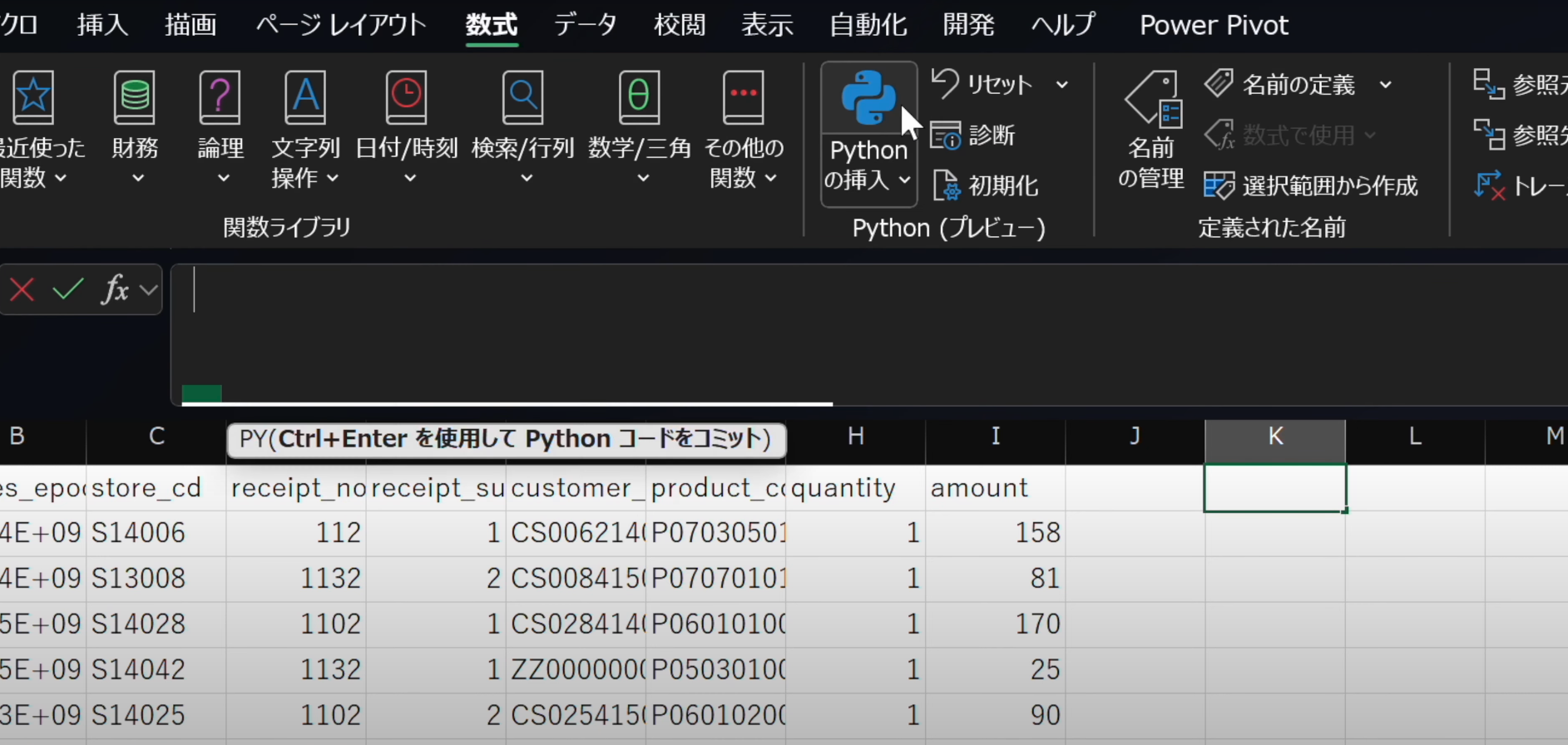
- Python in Excelを使ってDataFrameにデータを格納するにはセル範囲を選択します。
列を指定するか、または表のセル範囲を指定します。
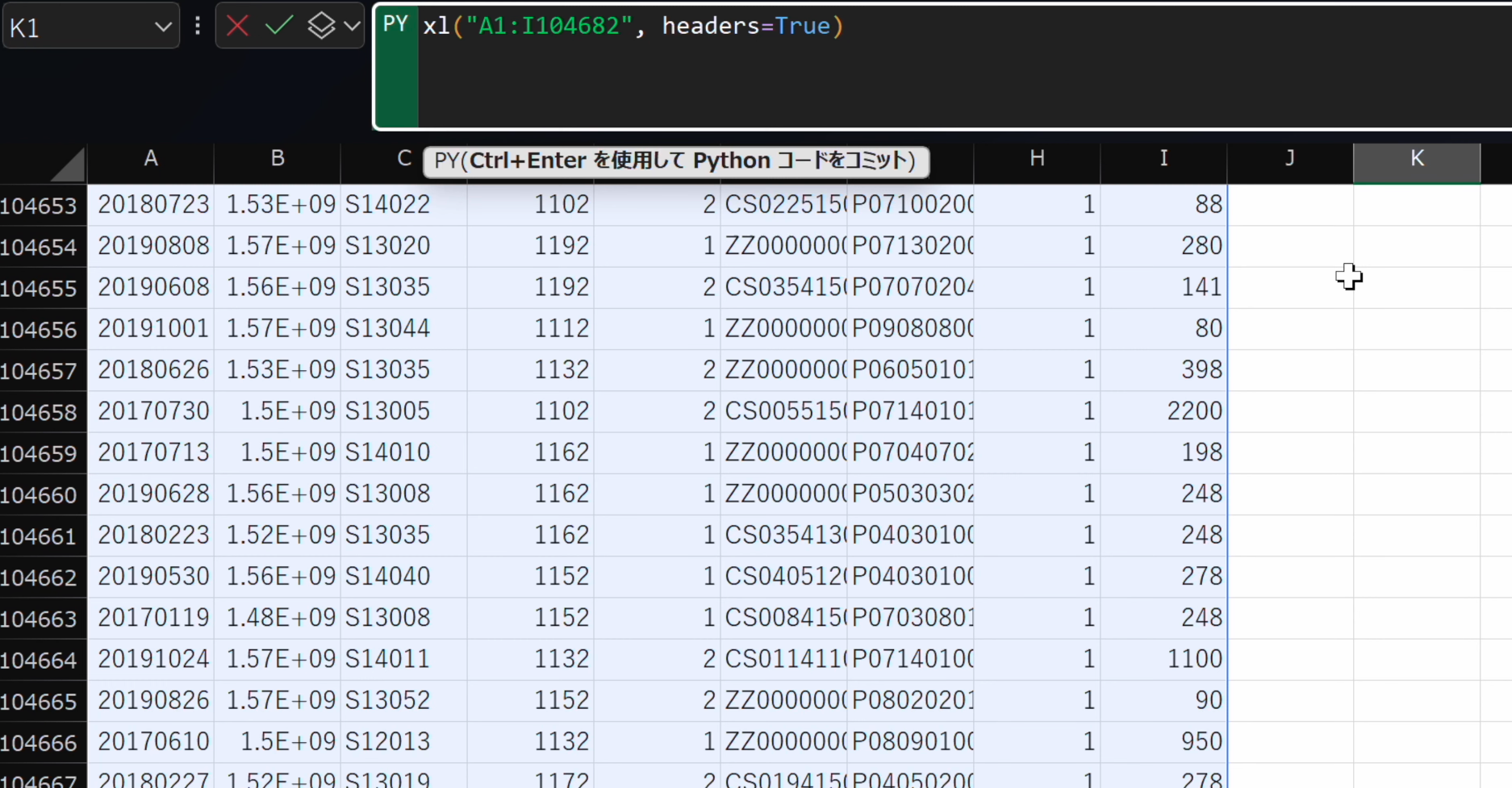
- 指定した範囲をdf_receiptという変数に格納します。
df_receipt = xl("A1:I104682", headers=True) df_receipt.head(10)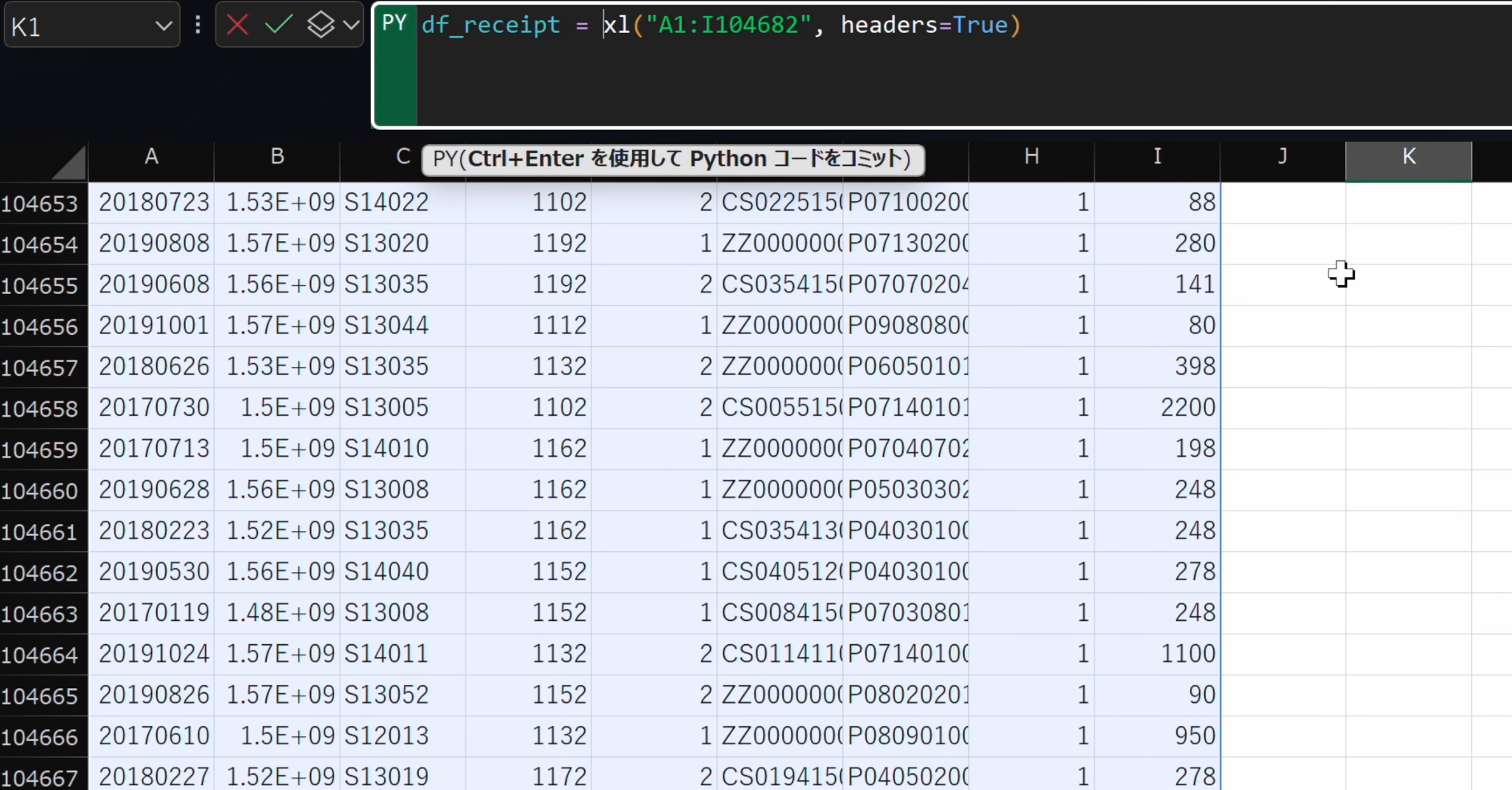
- 先ほどと同様にdf_receiptに対して
headメソッドを使用します。引数には10と入力します。
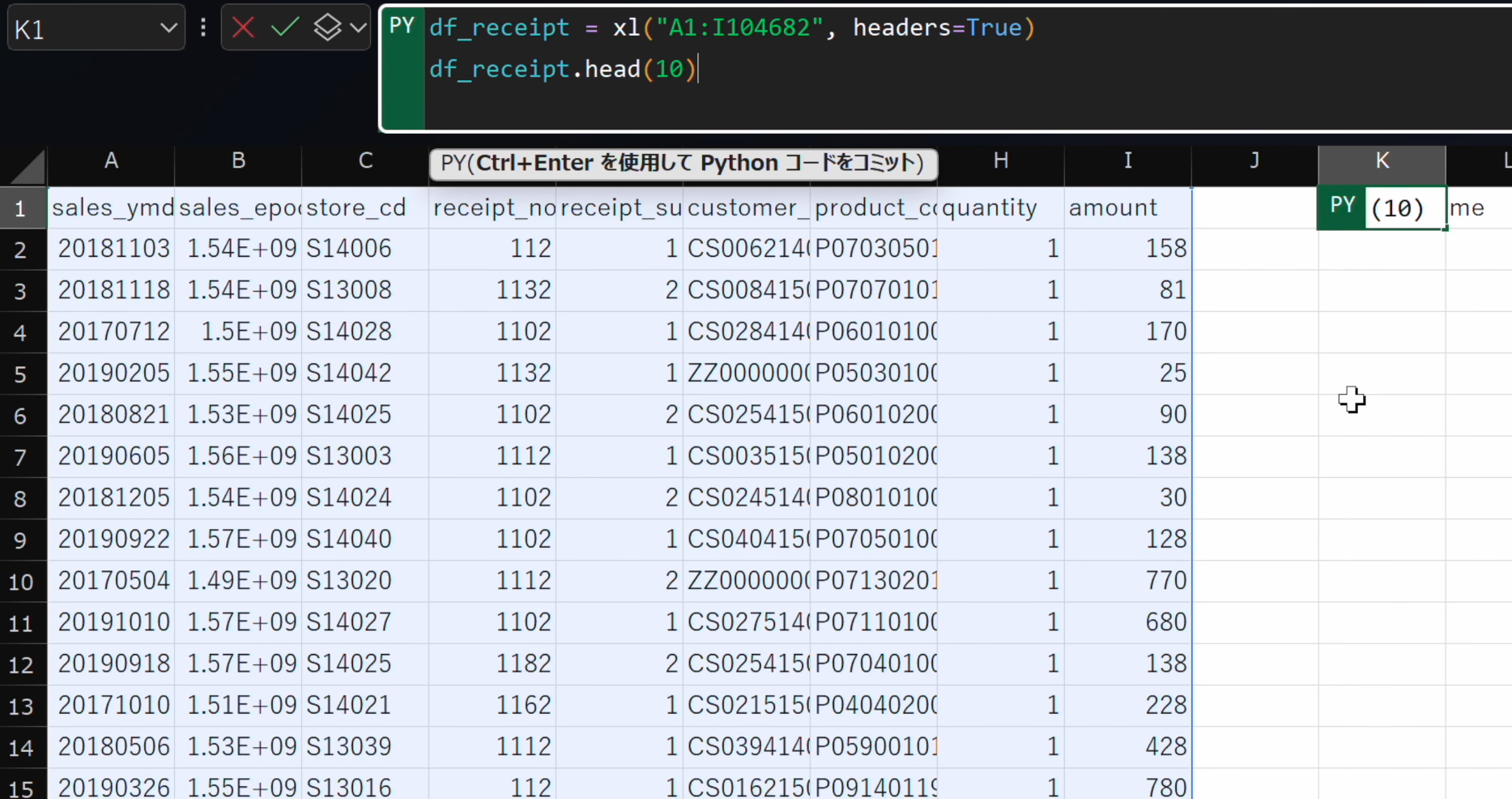
-
Ctrl + Enterで実行します。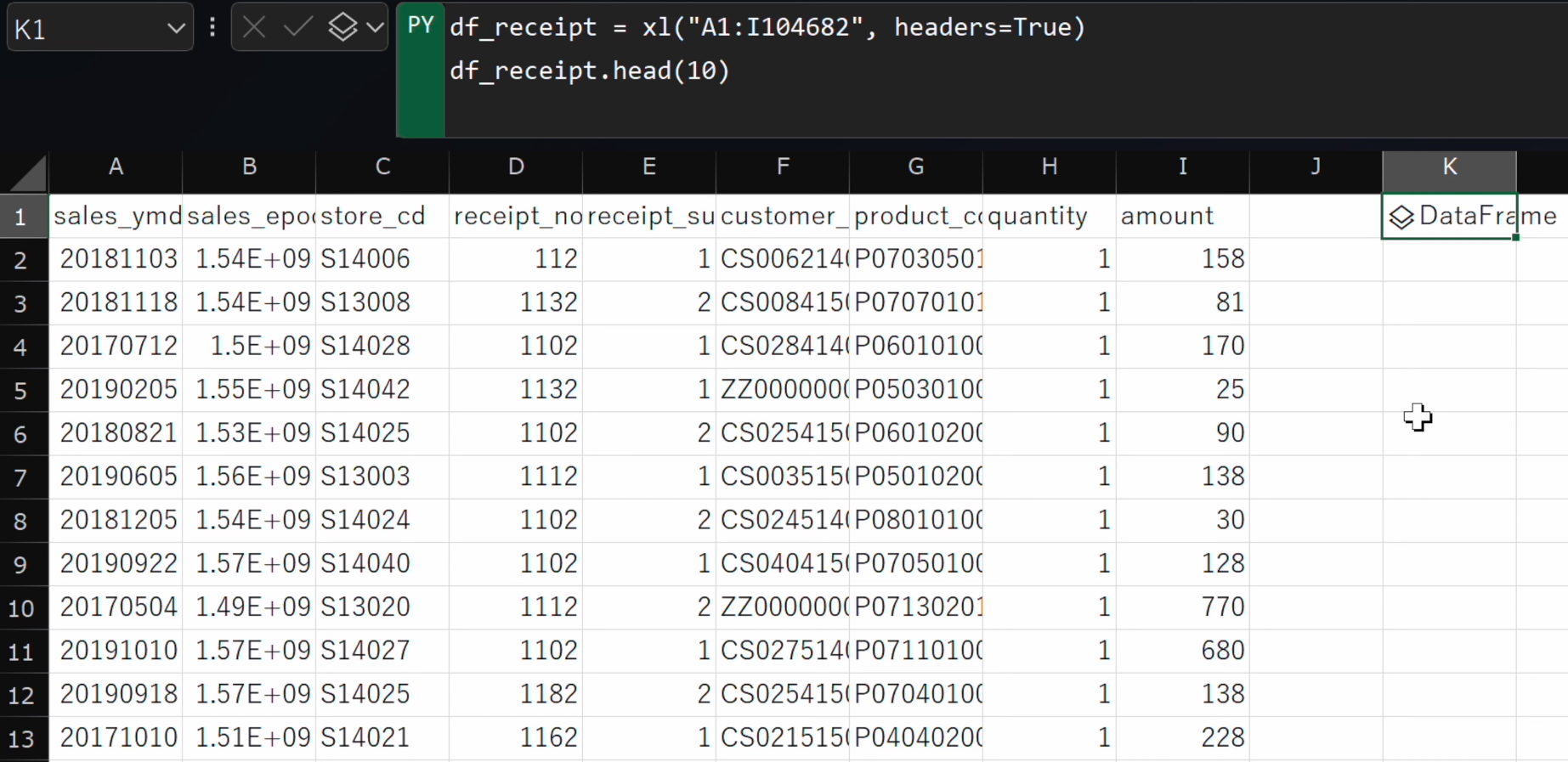
- 表示がBUSYからDataFrameに変わりましたら、数式バー隣のプルダウンメニューをクリック、PythonオブジェクトからExcelの値に変更します。
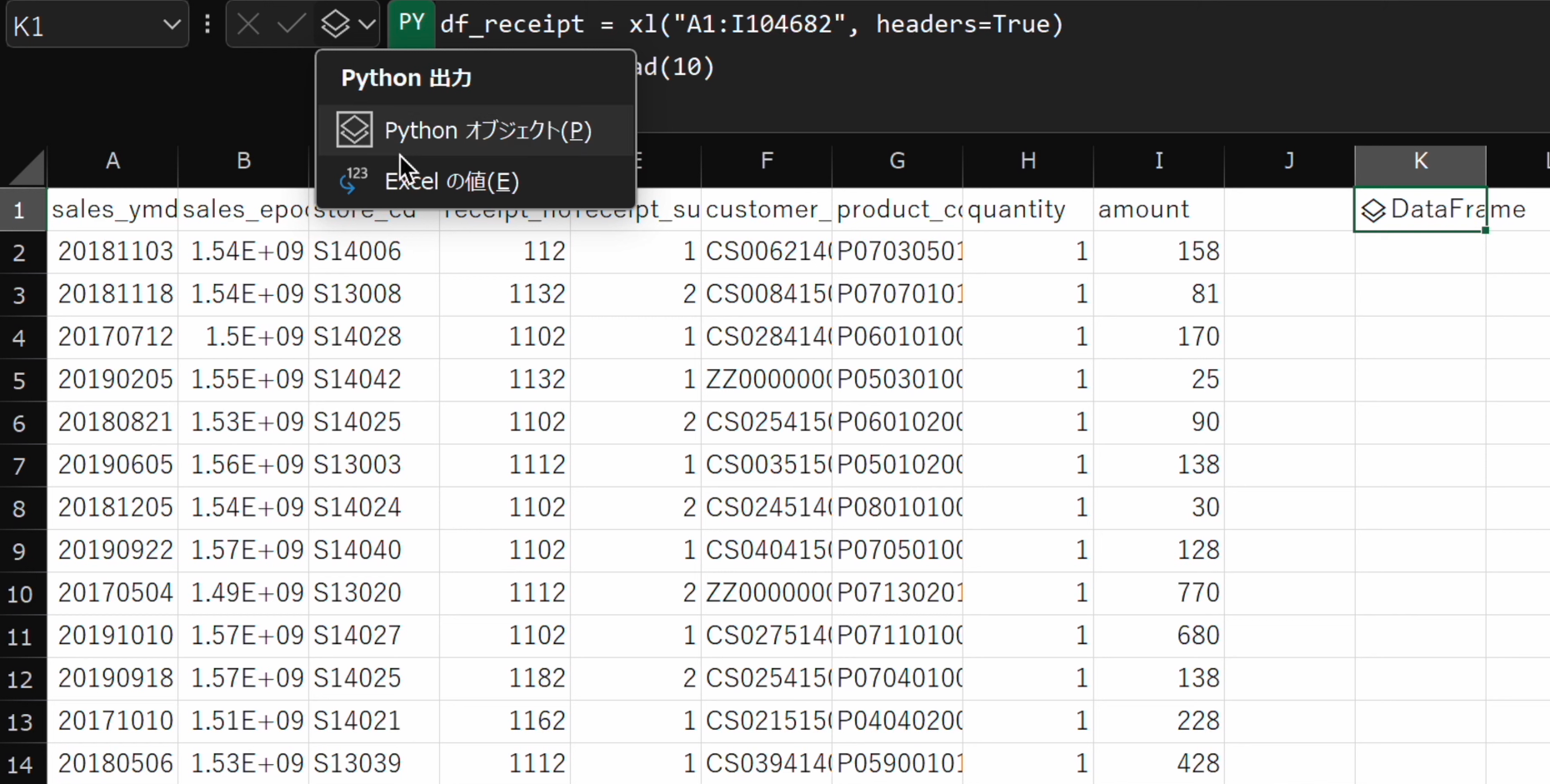
- 数値が出力されました。
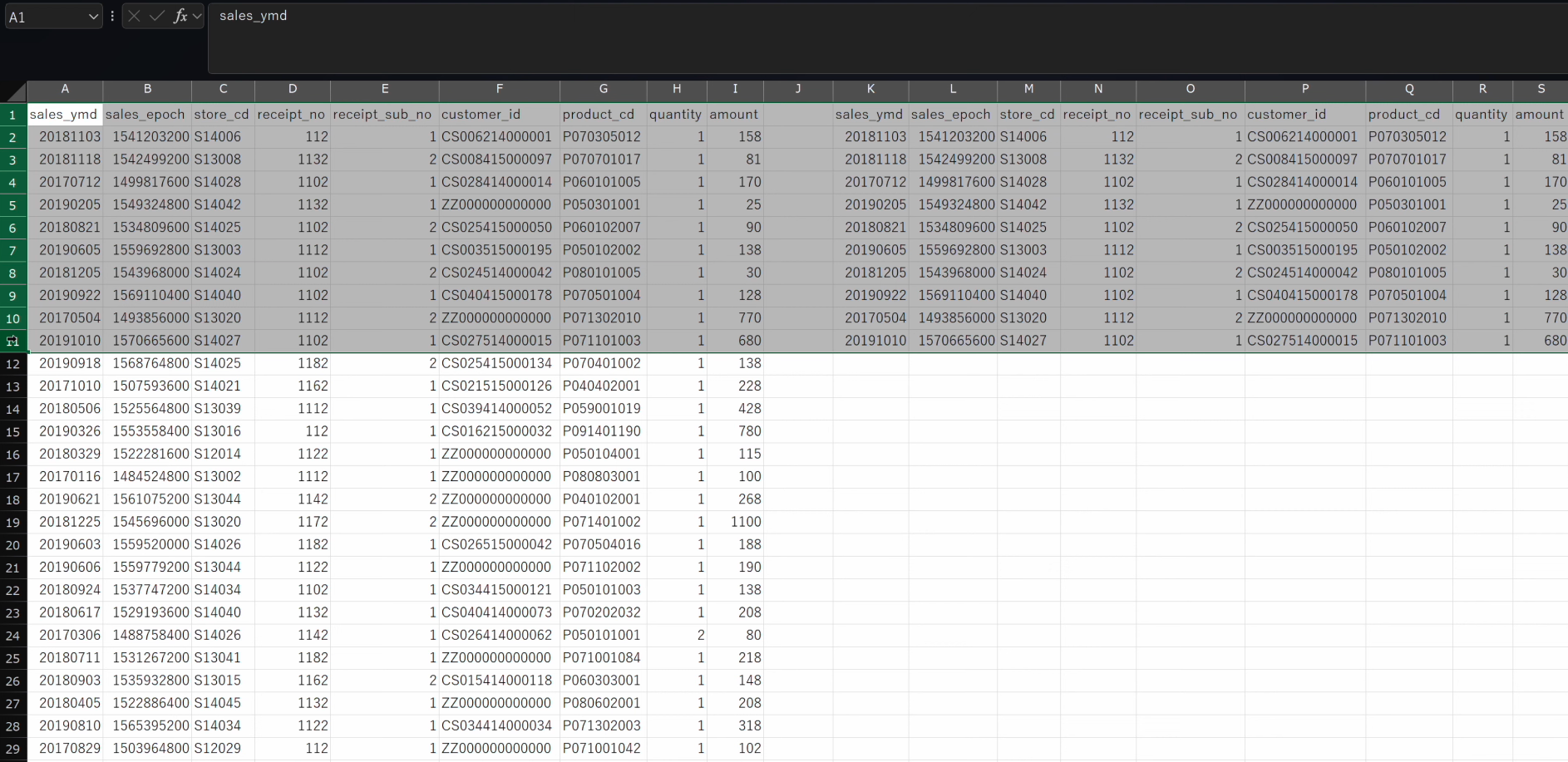
全項目の先頭10行が出力されました。
以上で、データサイエンス100本ノック演習問題001 全項目を指定行数抽出するをクリアしました。
5️⃣ おわりに
- 最後までお読みいただきありがとうございます!
- この記事へのご質問やアドバイスがありましたら、ぜひコメントもお待ちしております。
- またXでもVBA、Pythonに関するアウトプットをしていますので、🔽フォローいただけますと幸いです😆