

Pandasライブラリの基礎的な使い方
PandasはPythonでデータ解析を行うための強力なライブラリです。データの読み込み、変換、フィルタリング、集計など、様々な機能を提供しています。この記事では、Pandasライブラリの基本的な使い方を解説します。
応用的な使い方については、[Pandasライブラリ入門:Pythonでデータ解析をマスターする応用ガイド]を参照してください。
📄![]() Pandasライブラリ入門:Pythonでデータ解析をマスターする応用ガイド
Pandasライブラリ入門:Pythonでデータ解析をマスターする応用ガイド
1. Pandasのインストール
まずはじめに、Pandasをインストールします。Pandasはpipを用いて簡単にインストールできます。
pip install pandas
2. データの読み込み
今回使用するデータはこちらからダウンロードできます。
PandasではCSVやExcelなどのファイルからデータを読み込むことができます。
以下の例ではCSVファイルを読み込みます。
import pandas as pd
data = pd.read_csv("data.csv")
3. データフレームの基本操作
Pandasでは、データフレームという形式でデータを扱います。
データフレームは行と列からなる表形式のデータ構造です。
データフレームの確認
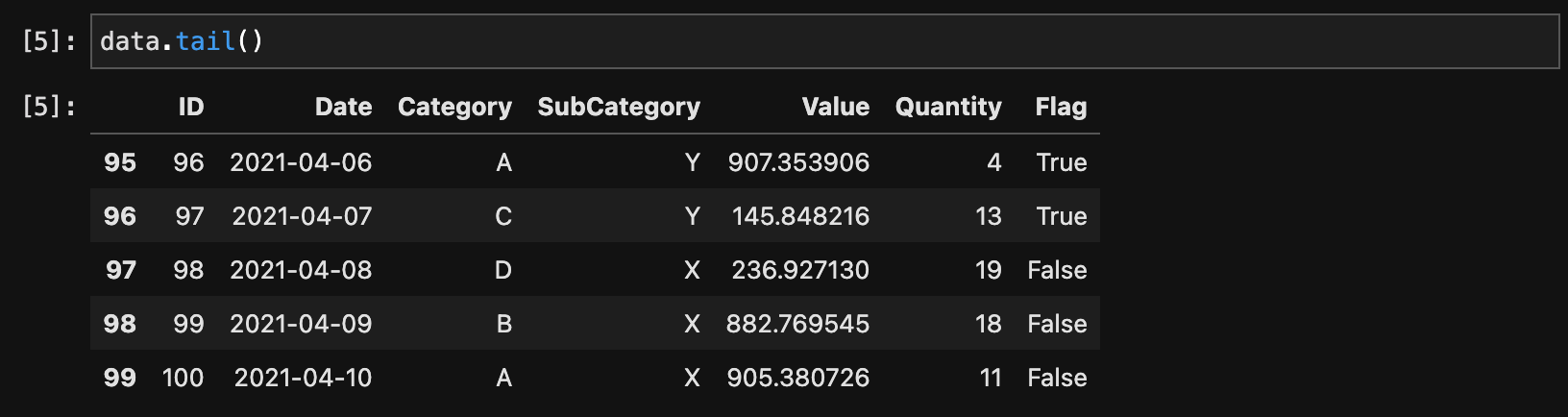
データフレームの先頭行を表示するにはhead()を、最後の行を表示するにはtail()を使います。
data.head()
data.tail()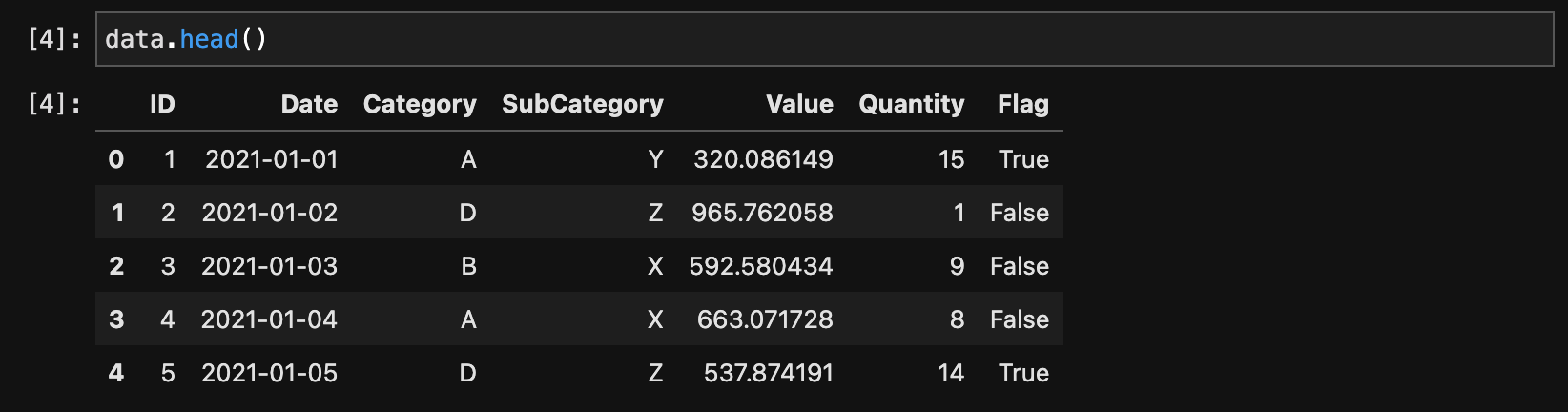
データフレームの行数と列数を確認するには、shape属性を使用します。
data.shape
列名を取得するには、columns属性を使用します。
data.columns
データフレームの情報
データフレームに含まれる情報を確認するには、info()を使います。
data.info()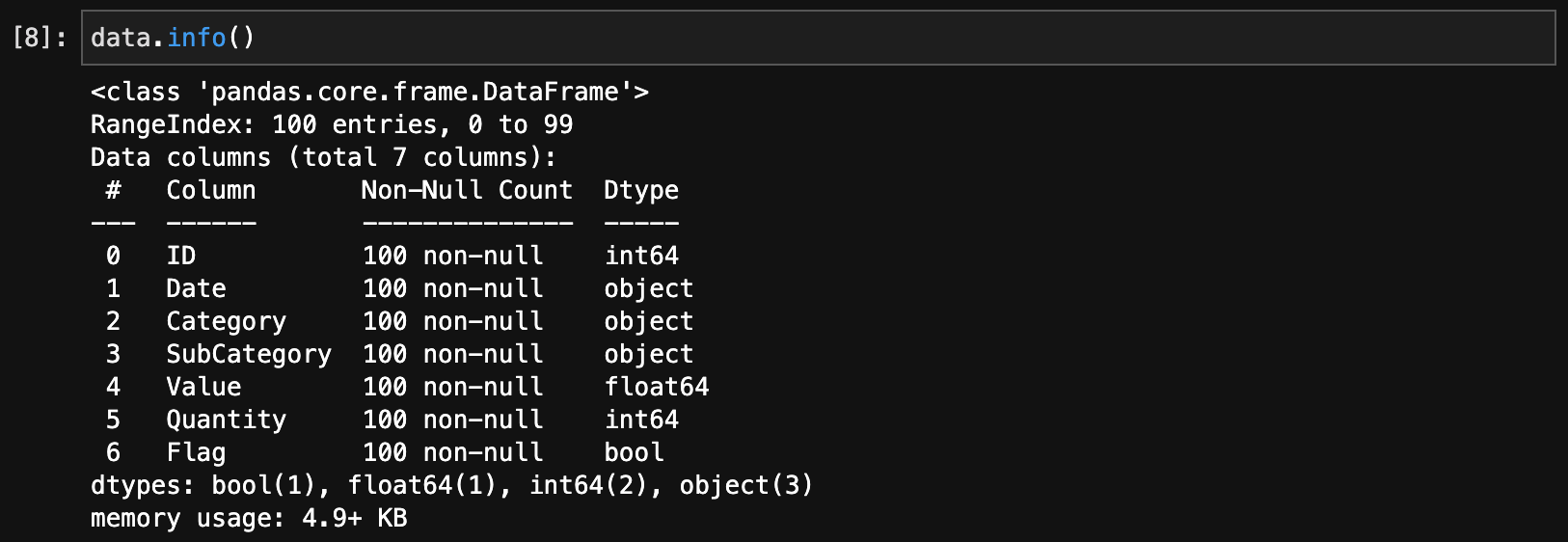
データフレームの統計情報を確認するには、describe()を使います。
data.describe()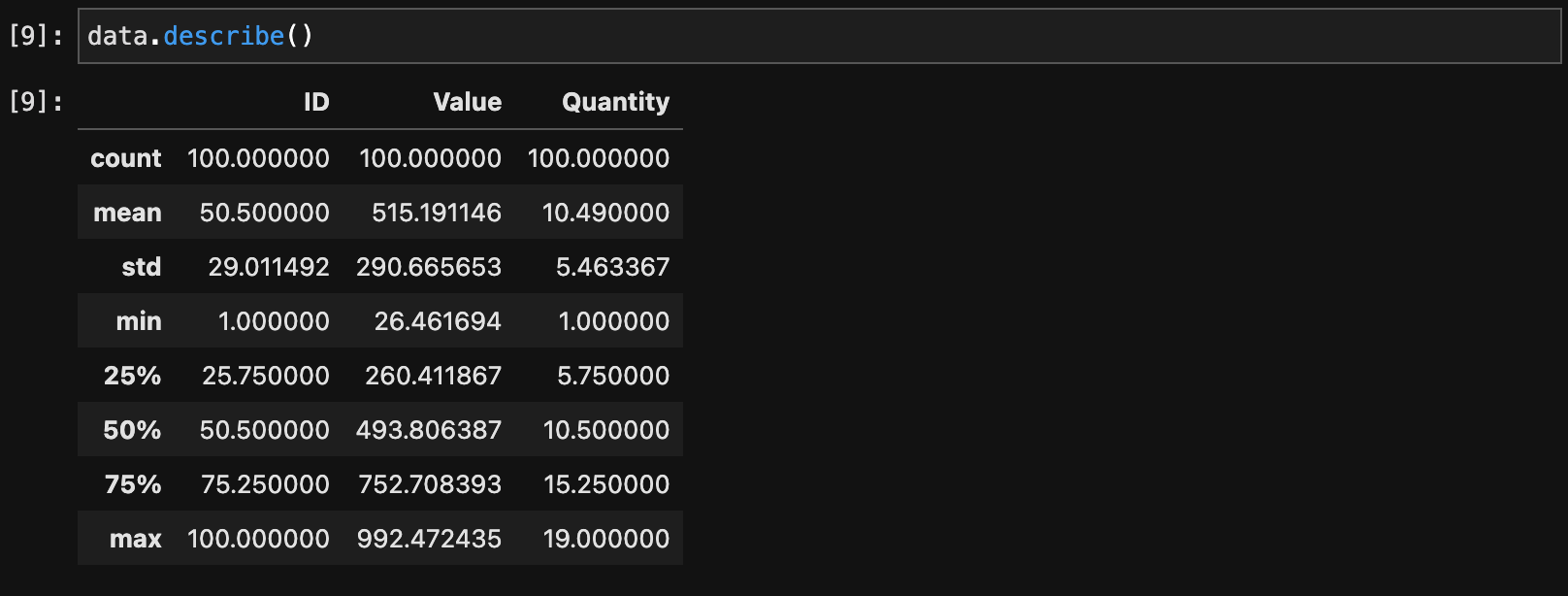
4. データの選択・抽出
列を選択するには、列名を指定します。
data["Date"]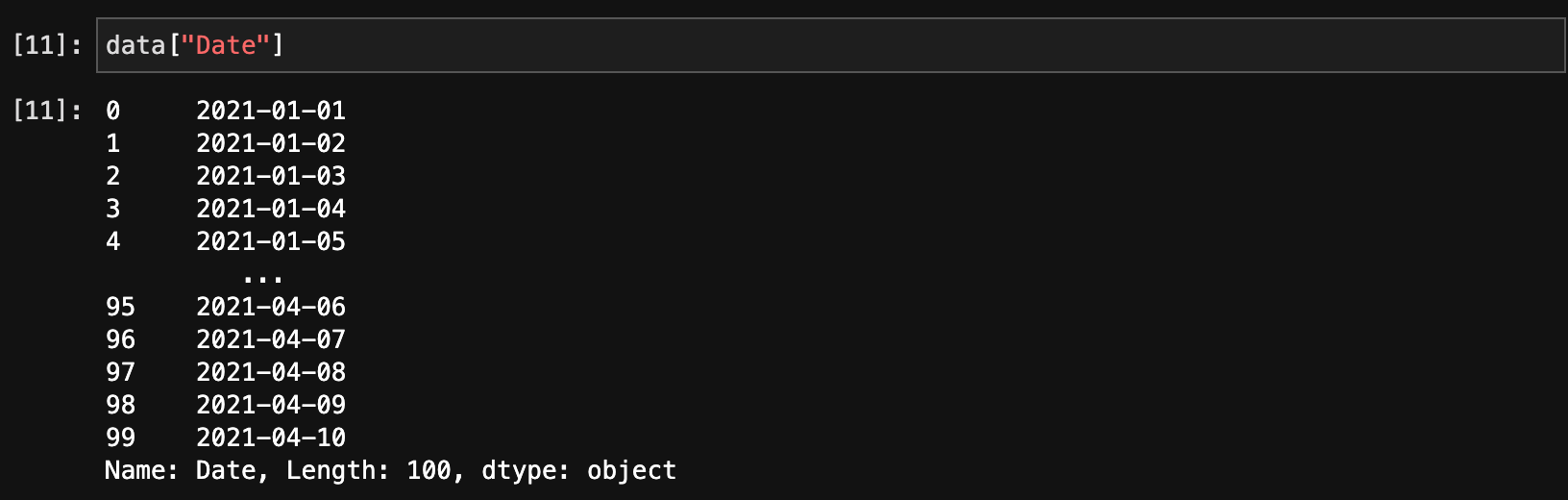
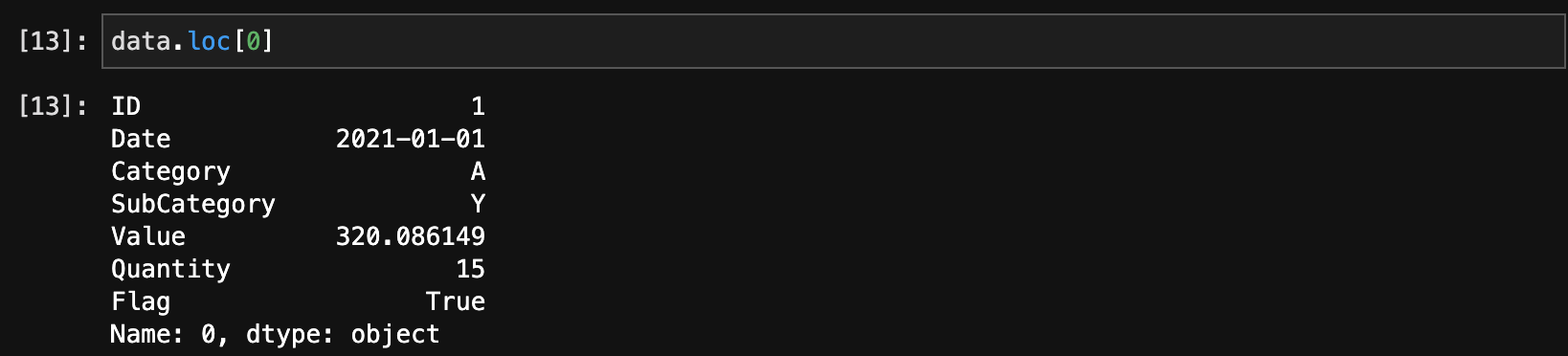
行を選択するには、ilocやlocを使います。
data.iloc[0] # 0番目の行を選択
data.loc[0] # インデックスが0の行を選択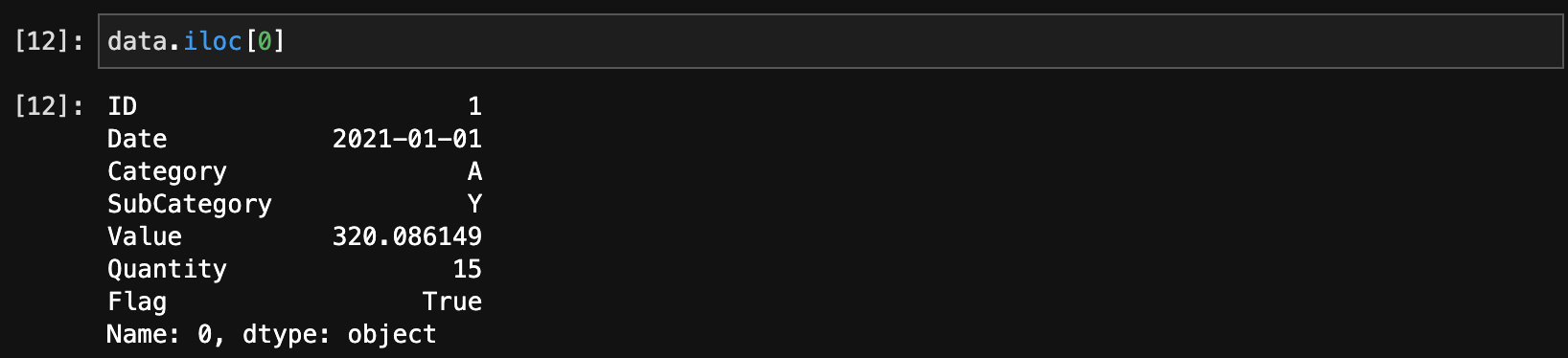
特定の条件を満たす行を選択するには、ブールインデックスを使います。
data[data["Quantity"] > 17]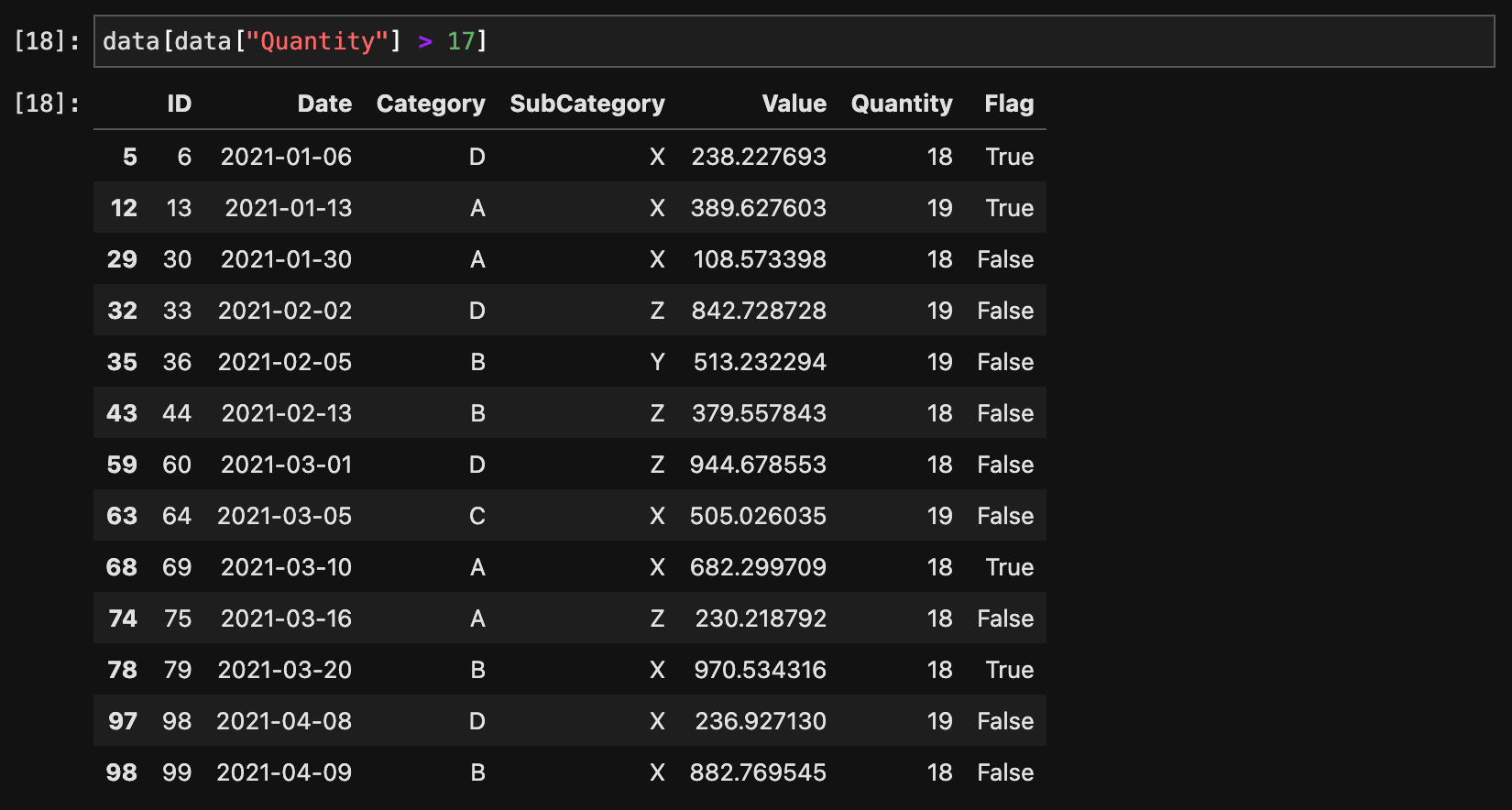
複数の条件を組み合わせて選択する場合は、&(and)や|(or)を使います。
data[(data["Quantity"] > 17) & (data["Value"] < 500)]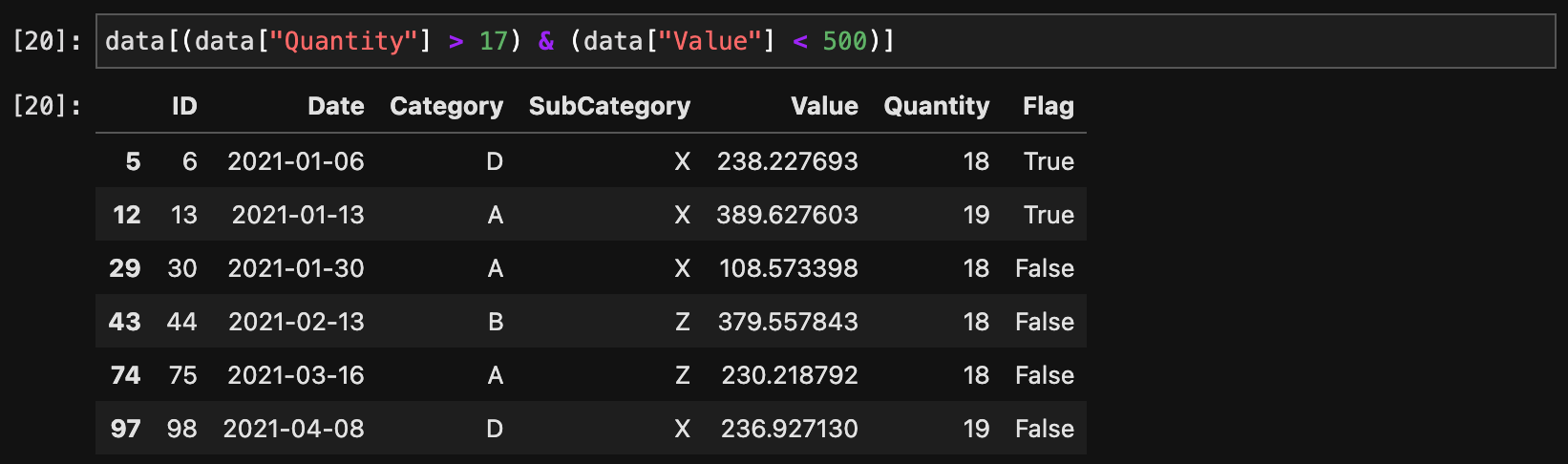
5. データのフィルタリング
特定の条件に基づいてデータをフィルタリングするには、query()メソッドを使用します。
data.query("ID > 95")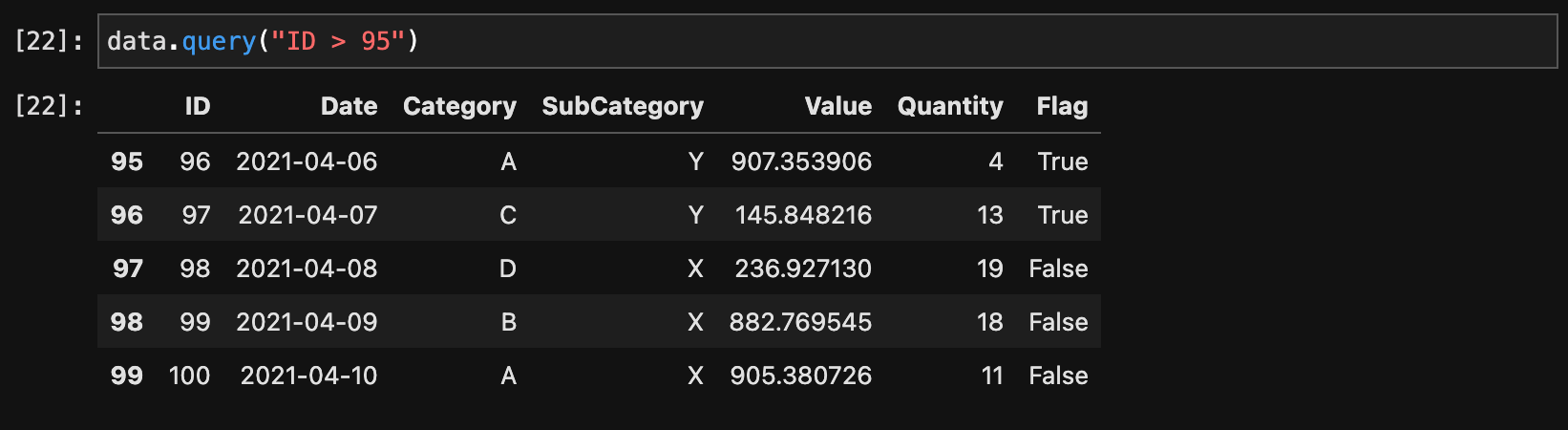
6. データの変換
列の追加・更新
新しい列を追加するには、新しい列名を指定して代入します。
data["CombinedCategory"] = data["Category"] + data["SubCategory"]
data["CombinedCategory"]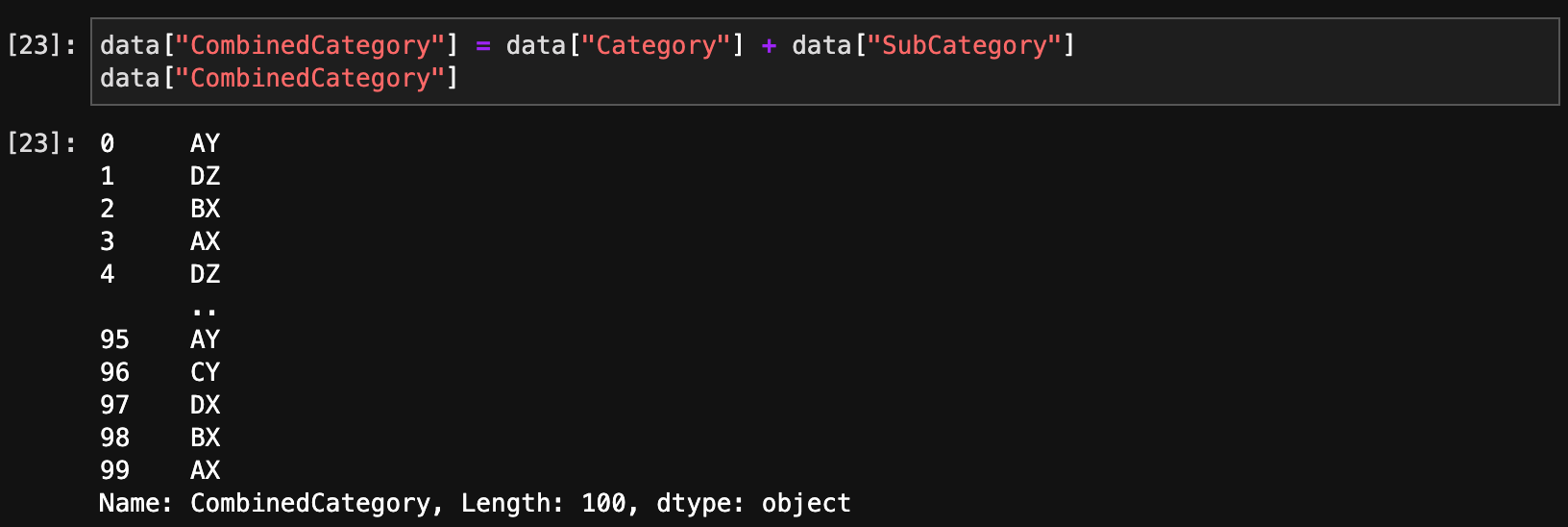
列の削除
列を削除するには、drop()メソッドを使用します。
data.drop("Flag", axis=1, inplace=True)
data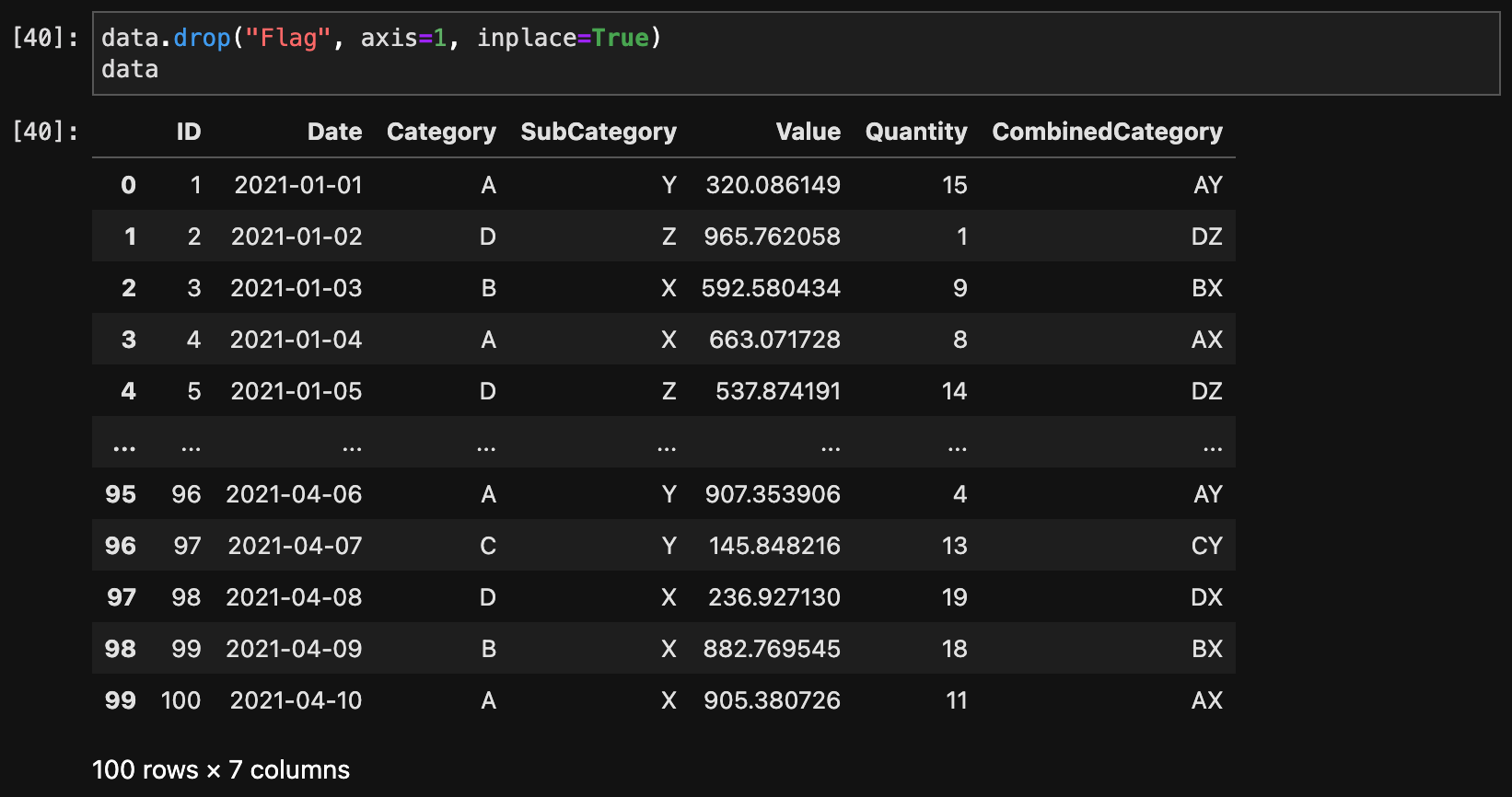
行の削除
行を削除するには、drop()メソッドを使用し、axis=0を指定します。
data.drop(2, axis=0, inplace=True)
data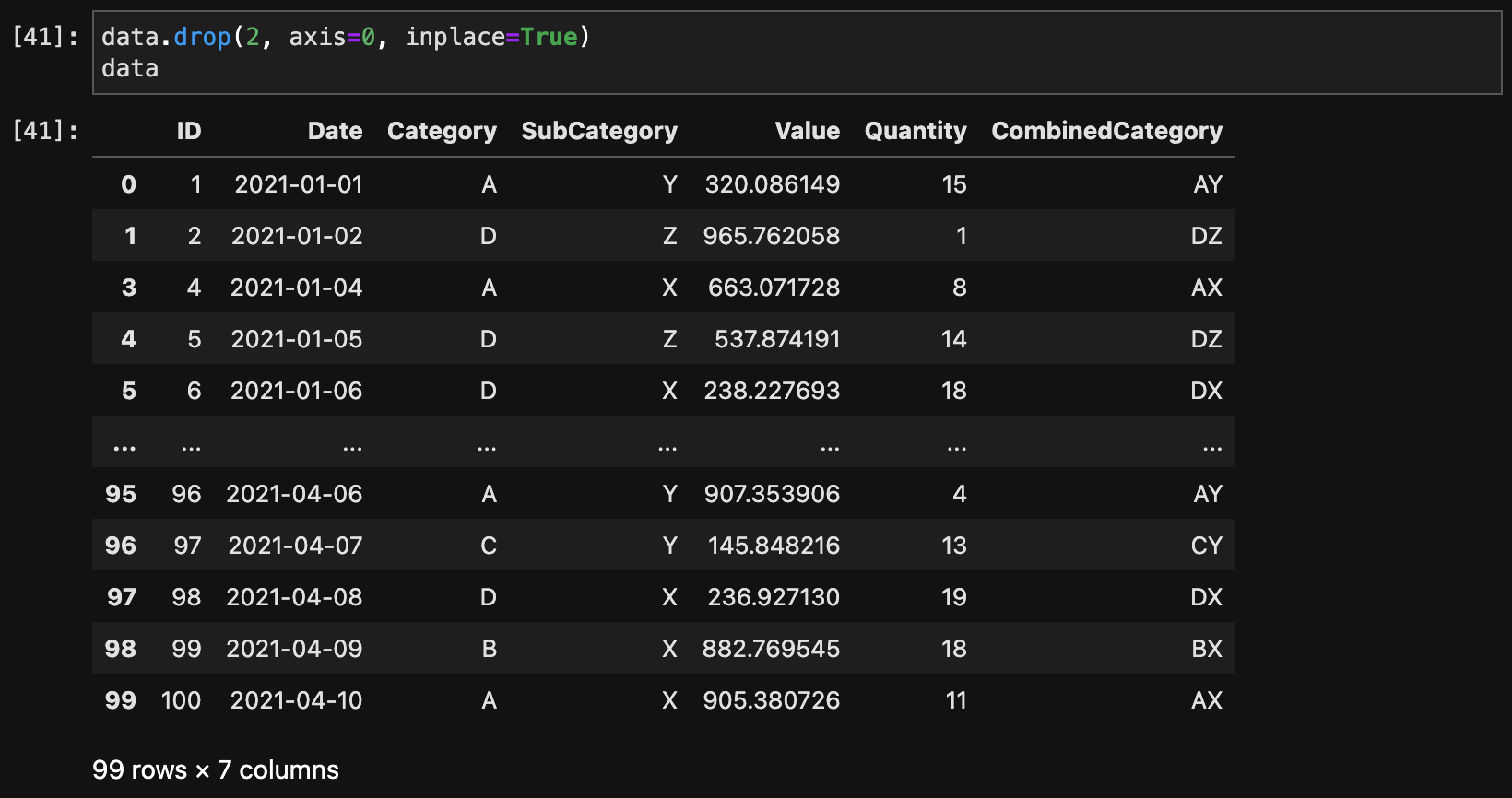
列のリネーム
列名を変更するには、rename()メソッドを使用します。
data.rename(columns={"CombinedCategory": "CategoryGrouping"}, inplace=True)
data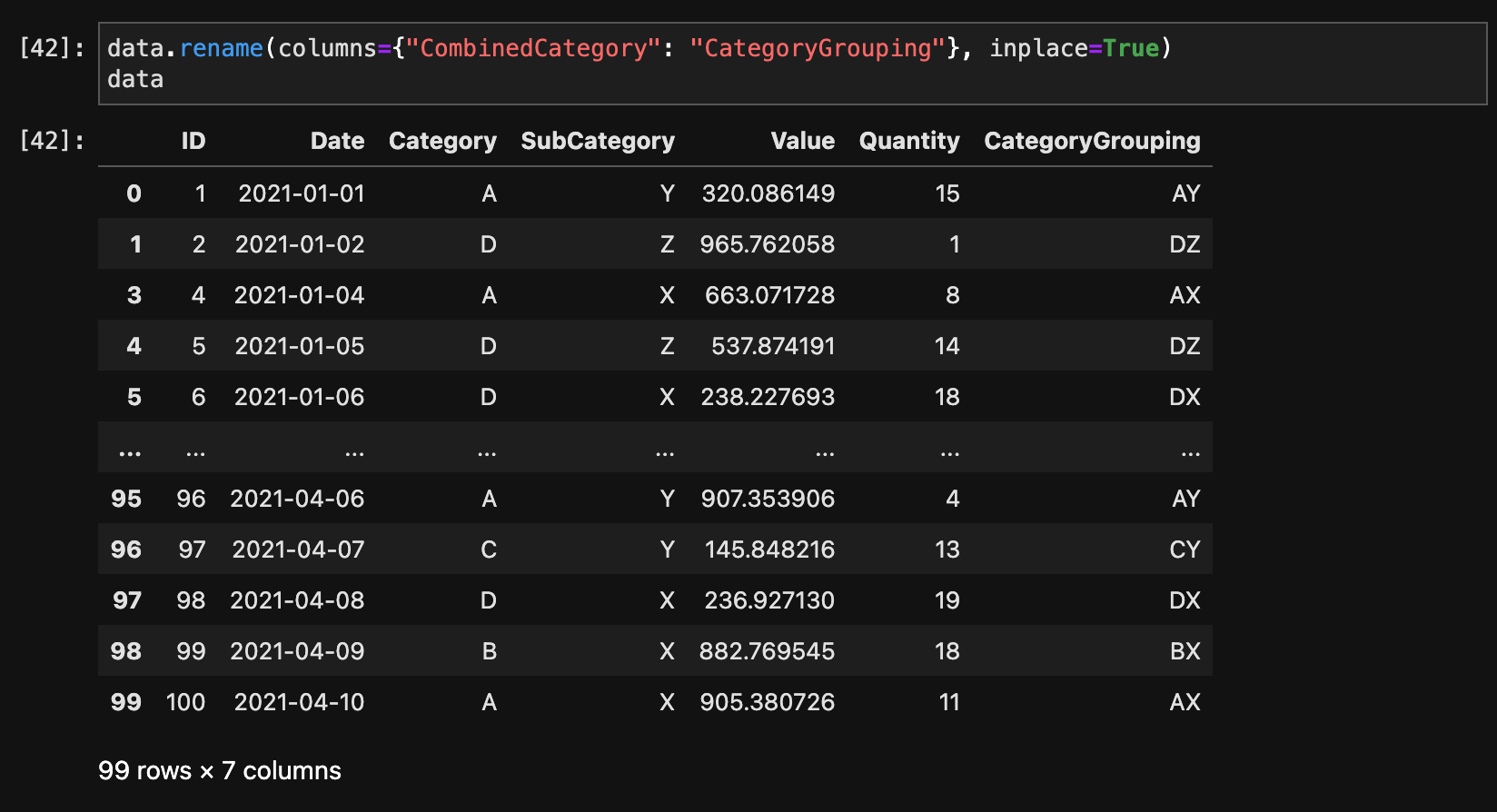
7. データの集計
グループ化
データをグループ化して集計するには、groupby()メソッドを使用します。
grouped_data = data.groupby("Quantity")
grouped_data.sum()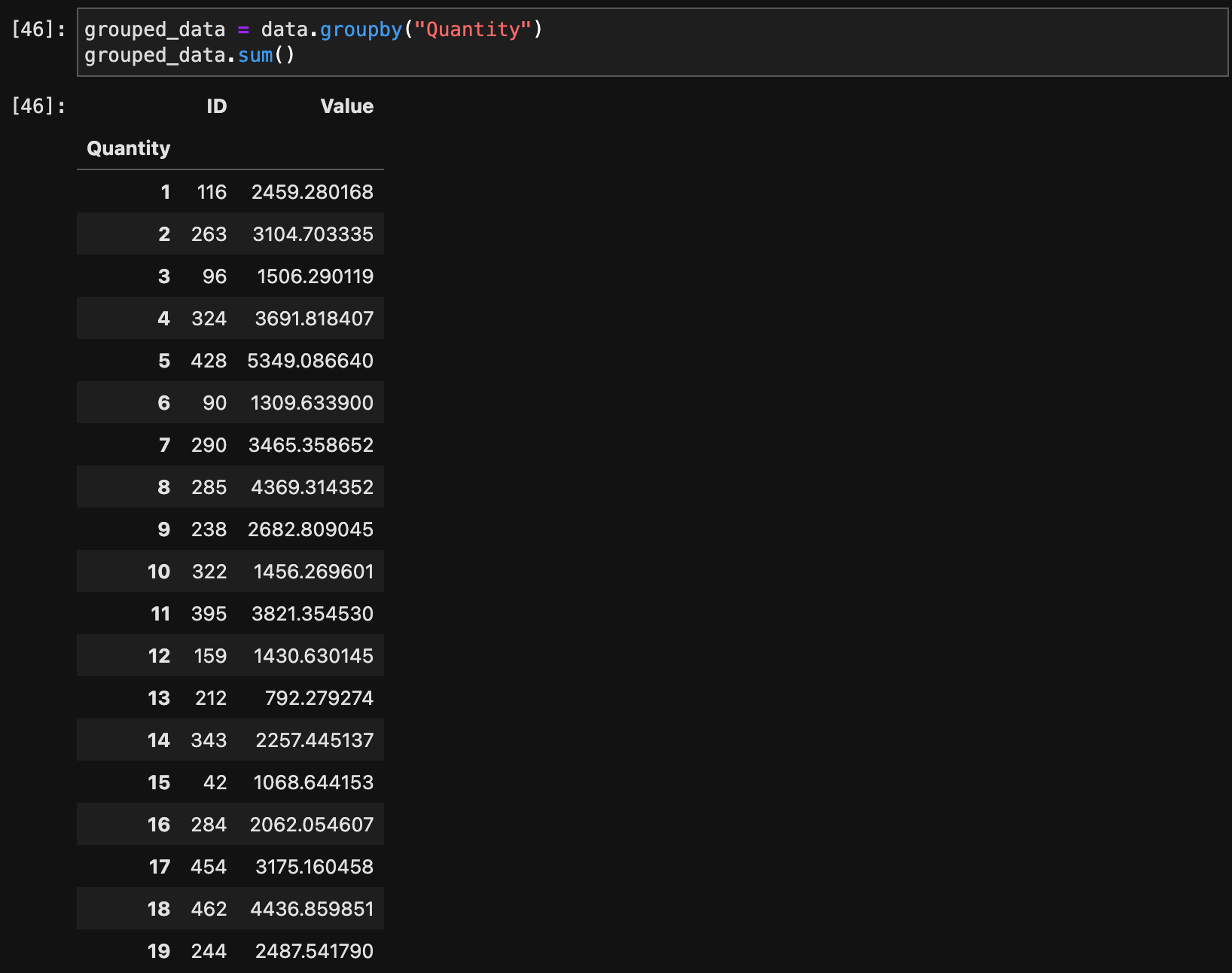
集計関数
グループ化したデータに対して集計関数を適用します。以下は一部の集計関数です。
-
sum(): 合計 -
mean(): 平均 -
min(): 最小 -
max(): 最大 -
count(): カウント
grouped_data["Value"].sum()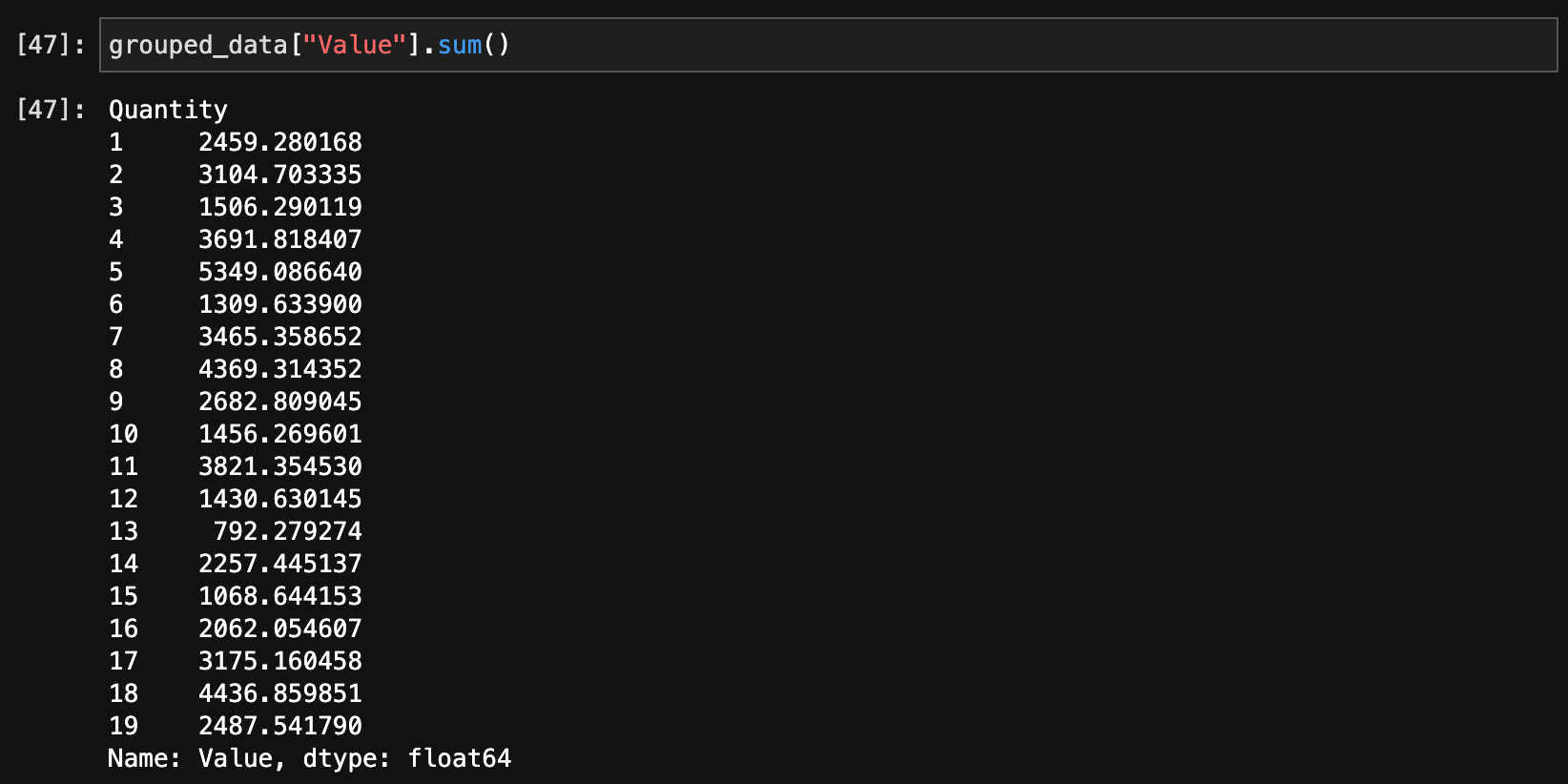
ピボットテーブル
ピボットテーブルを作成するには、pivot_table()メソッドを使用します。
data.pivot_table(values="Value", index="Quantity", columns="Category", aggfunc="sum")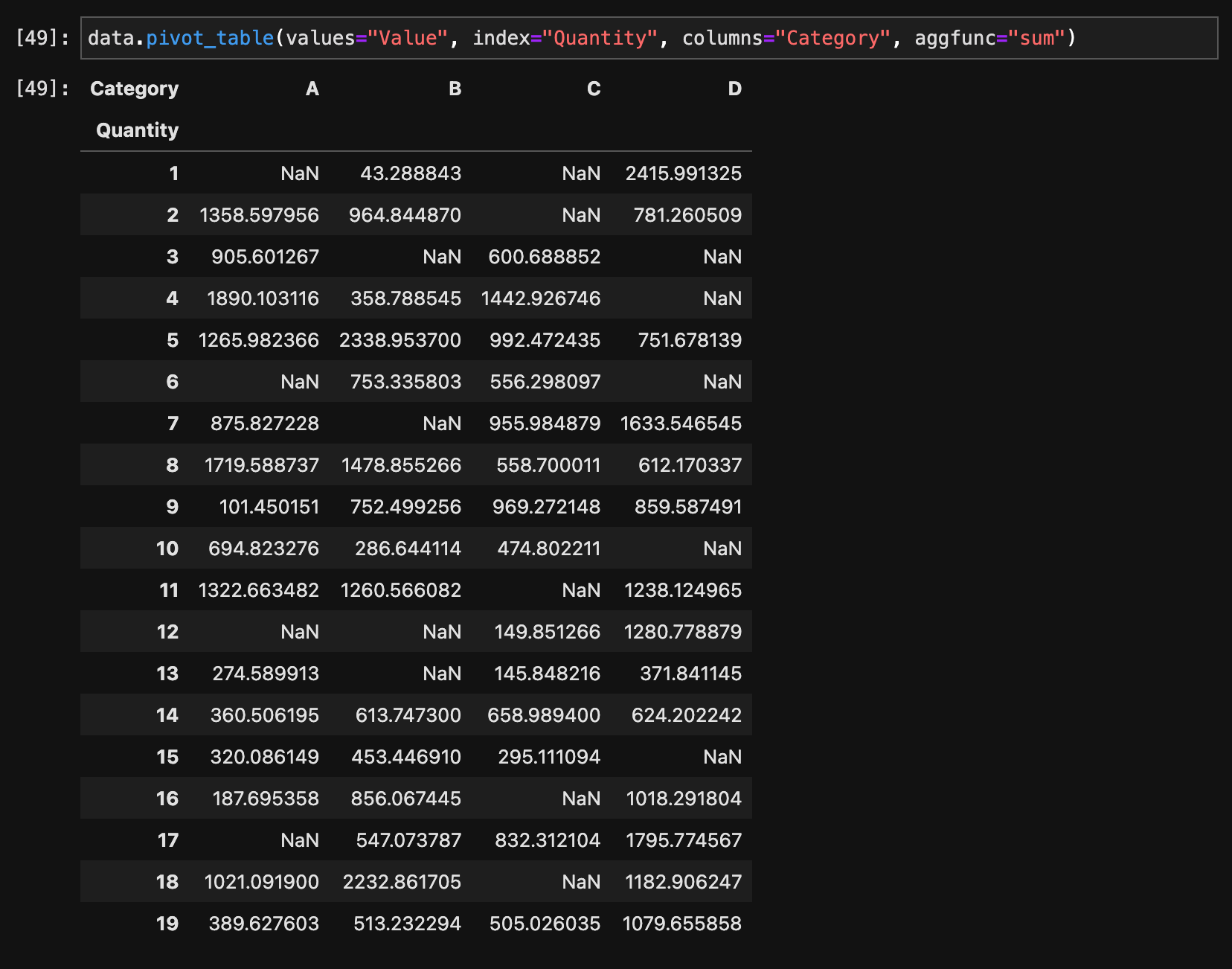
8. データの結合
結合するデータはこちらからダウンロードできます。
結合するデータを読み込みます。
data2 = pd.read_csv("data2.csv")
data2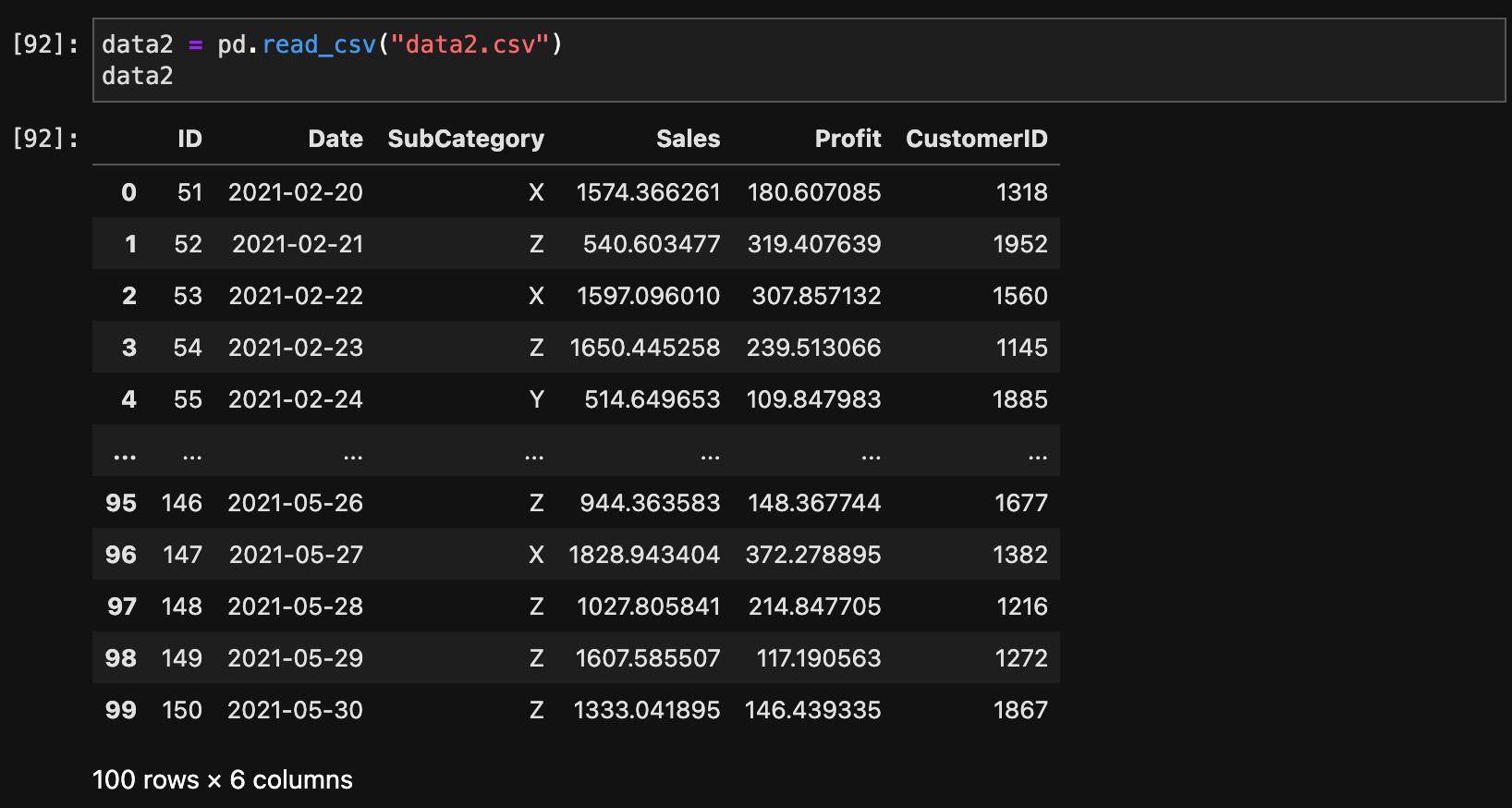
横方向の結合
データフレーム同士を横方向に結合するには、concat()関数を使用します。
combined_data = pd.concat([data, data2], axis=1)
combined_data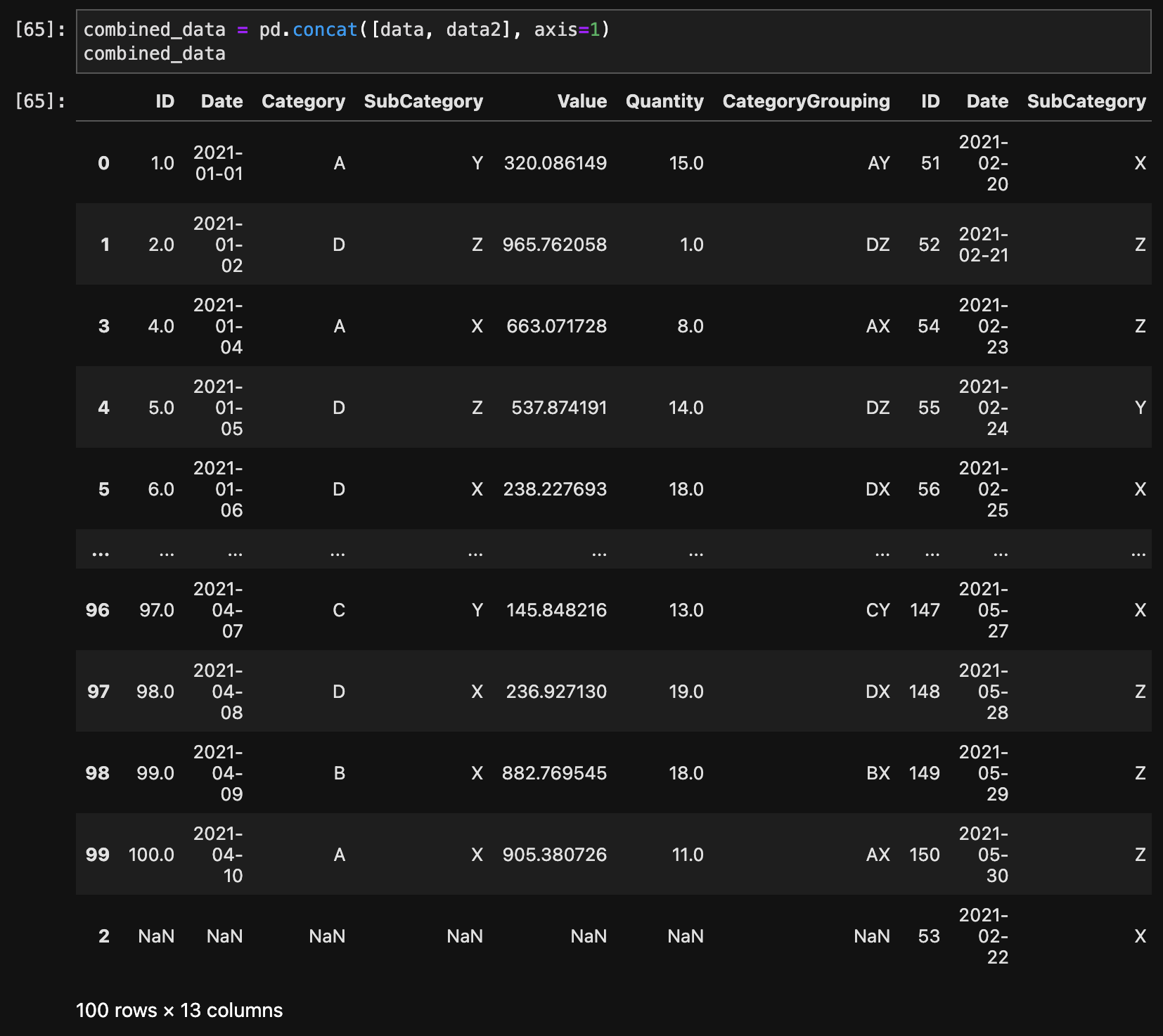
縦方向の結合
データフレーム同士を縦方向に結合するには、concat()関数でaxis=0を指定します。
combined_data = pd.concat([data, data2], axis=0)
combined_data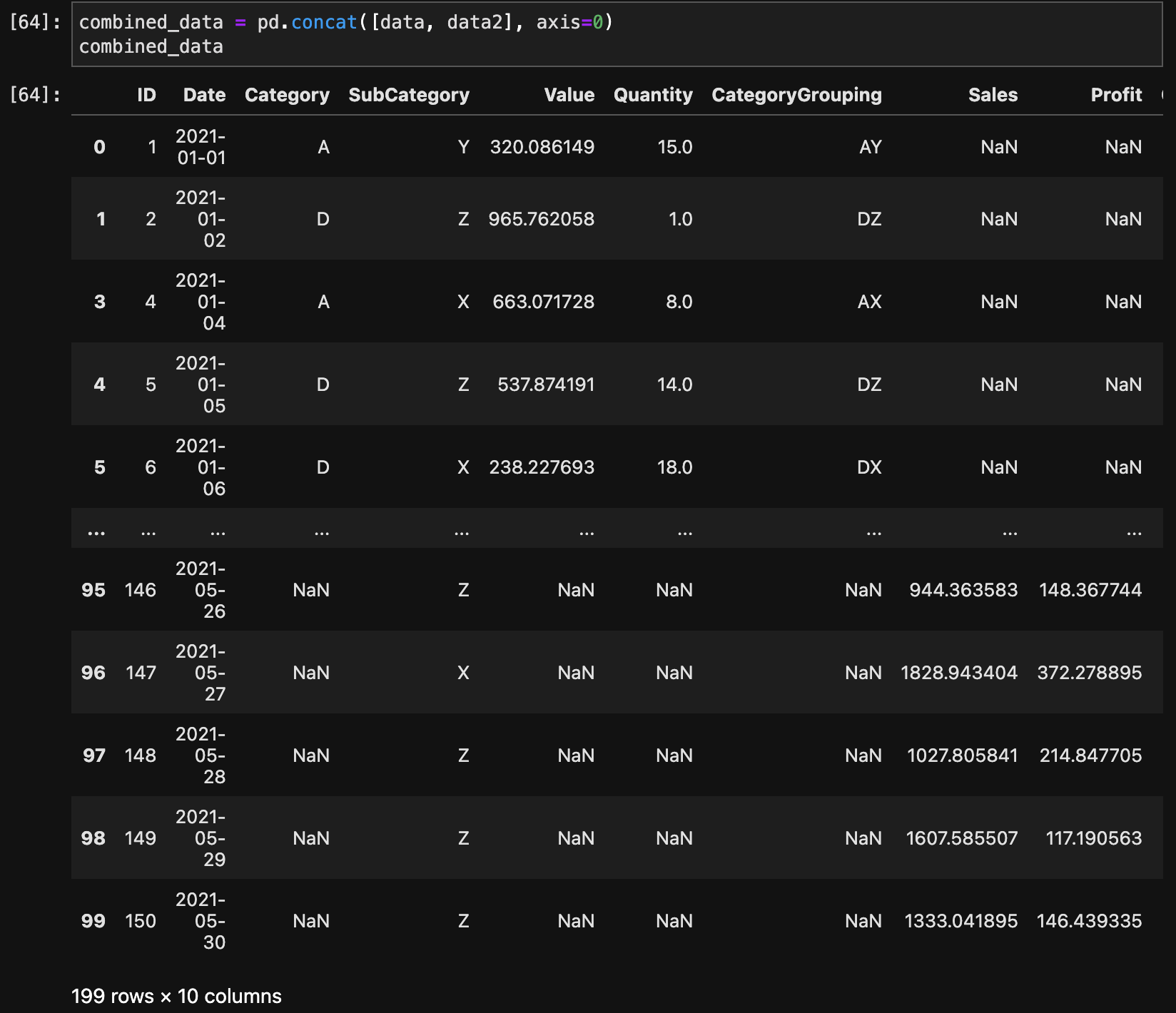
内部結合
共通のキーを持つデータフレーム同士を内部結合するには、merge()関数を使用します。
merged_data = pd.merge(data, data2, on="Date")
merged_data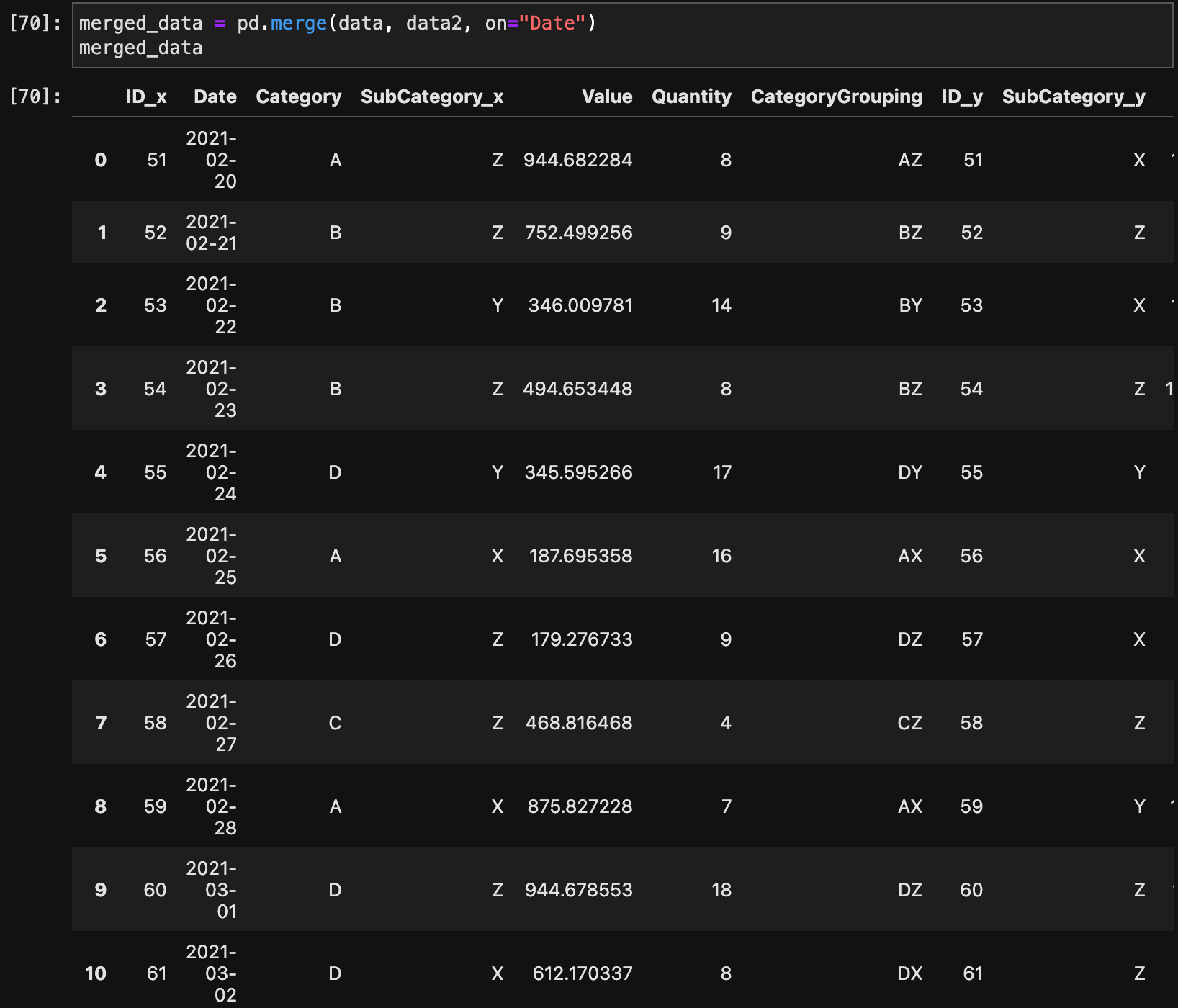
外部結合
共通のキーを持つデータフレーム同士を外部結合するには、merge()関数でhow="outer"を指定します。
merged_data = pd.merge(data, data2, on="Date", how="outer")
merged_data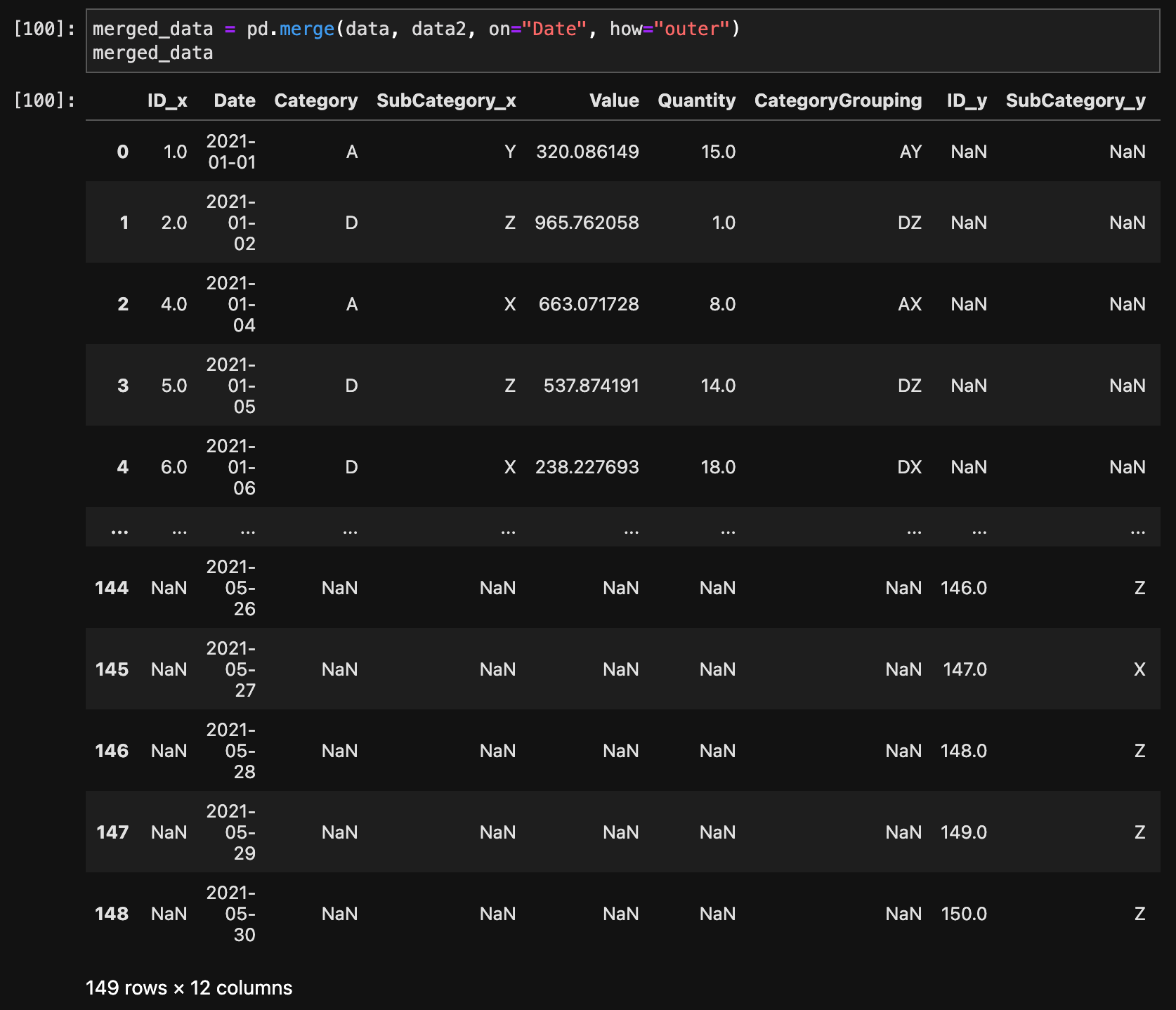
9. データの出力
データフレームをCSVファイルとして出力するには、to_csv()メソッドを使用します。
merged_data.to_csv("output.csv", index=False)
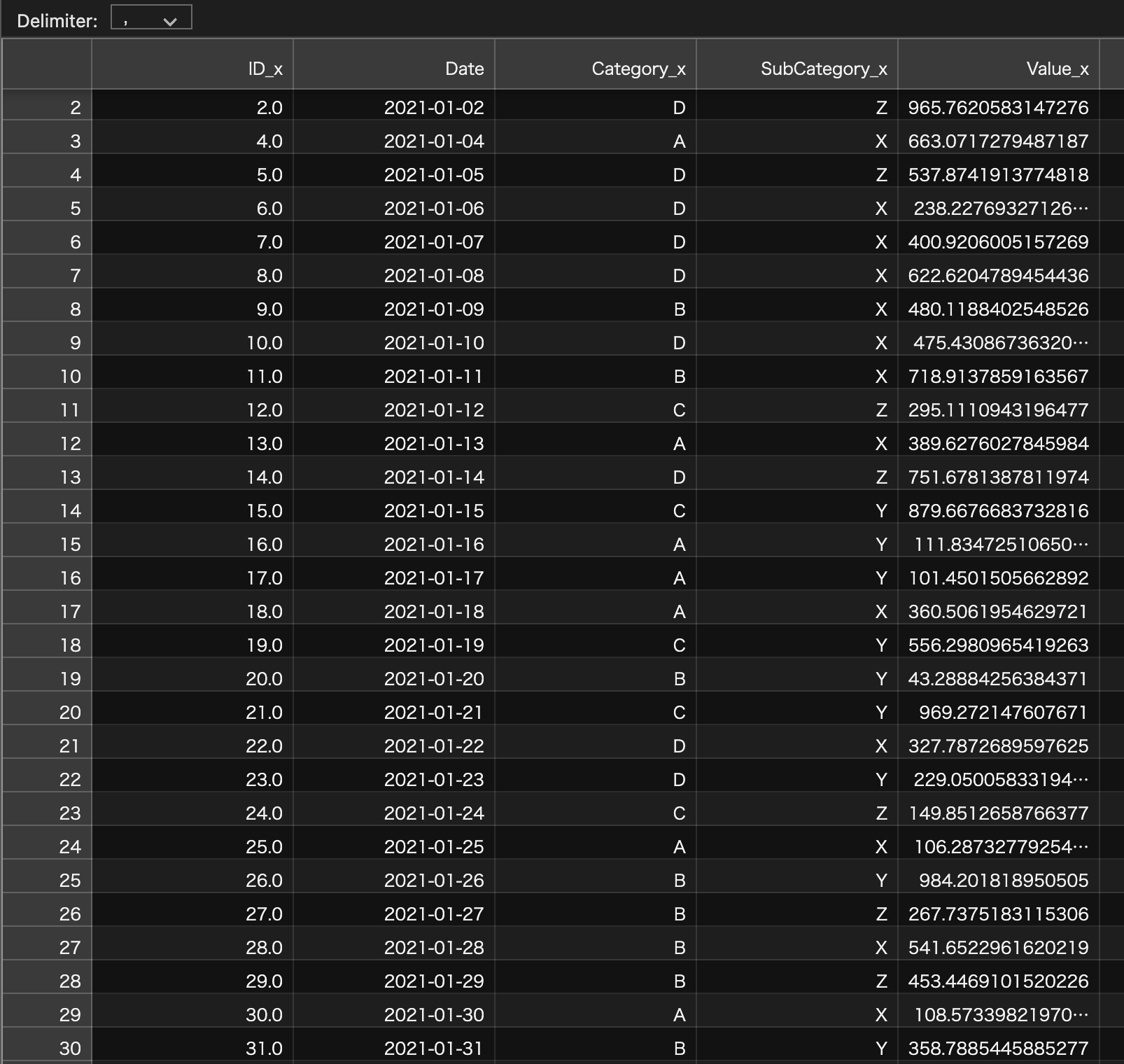
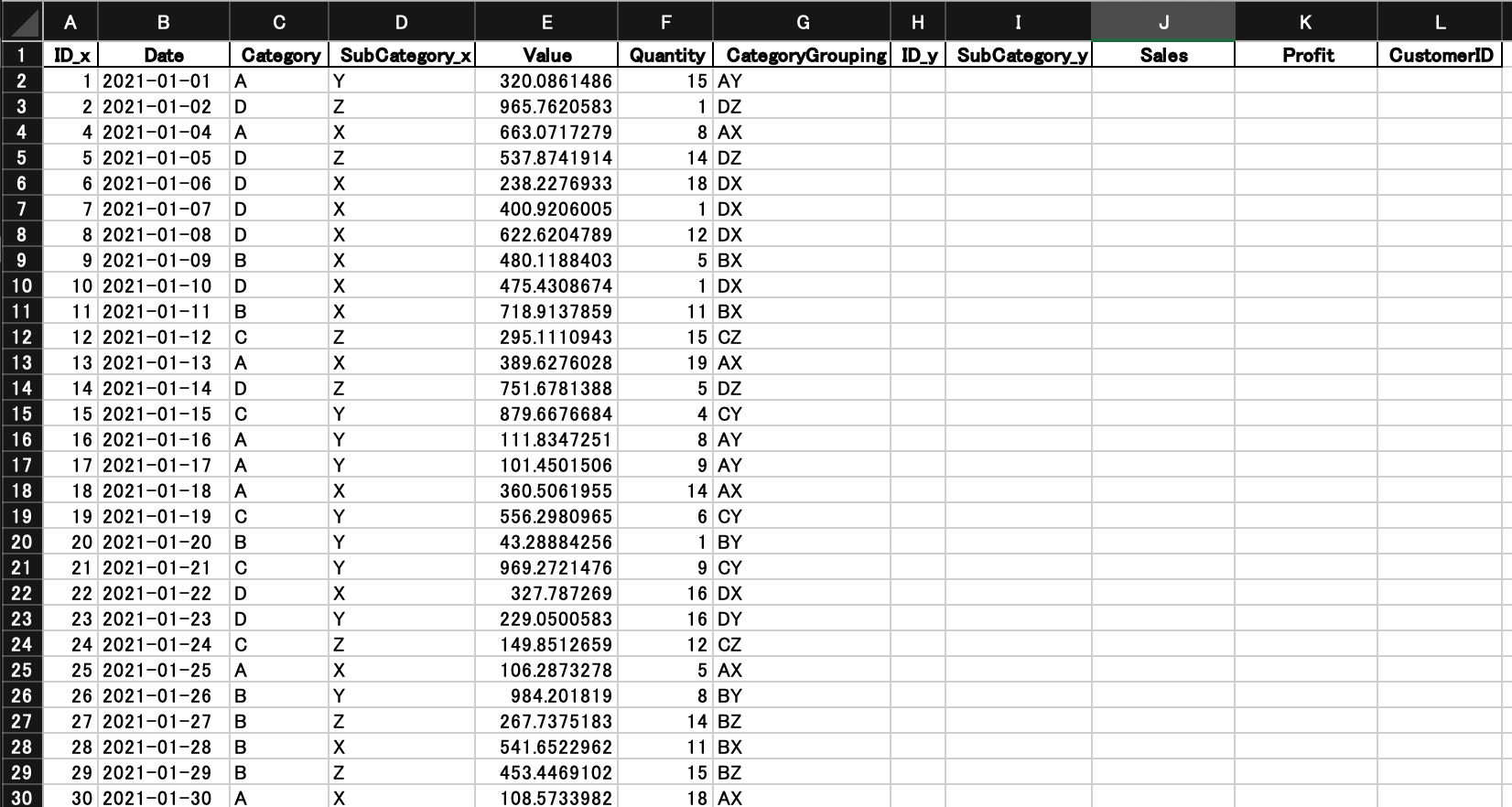
Excelファイルとして出力するには、to_excel()メソッドを使用します。ただし、openpyxlライブラリが必要です。
import openpyxl
merged_data.to_excel("output.xlsx", index=False)
まとめ
この記事では、Pandasライブラリの基礎的な使い方を解説しました。
データの読み込み、データフレームの基本操作、データの選択・抽出、フィルタリング、変換、集計、結合、出力など、Pandasはデータ解析に必要な機能を豊富に提供しています。これらの基本操作をマスターすることで、より高度なデータ解析が可能になります。
Pandasは非常に柔軟で強力なライブラリであり、データサイエンスや機械学習の分野で広く使用されています。この記事で紹介した機能は、Pandasの一部に過ぎません。更なる習熟のためには、実際にデータを扱いながら、さまざまな操作を試してみることが重要です。
Pandasの公式ドキュメントや、Pandasを使用したデータ解析のチュートリアルなども参考にして、Pandasを活用したデータ解析のスキルを高めていきましょう。
そして、日々の業務やプロジェクトにおいて、効率的かつ正確なデータ解析を行うことで、より良い意思決定や問題解決に役立ててください。
最後までお読みいただきありがとうございます!
この記事へのご質問やアドバイスがありましたら、ぜひコメントもお待ちしております。
またXでもVBA、Pythonに関するアウトプットをしていますので、🔽フォローいただけますと幸いです😆