

Pandasライブラリの応用的な使い方
この記事では、Pandasライブラリの応用的な使い方を解説します。
基本的な使い方については、[Pandasライブラリ入門:Pythonでデータ解析をマスターする基本ガイド]を参照してください。
📄![]() Pandasライブラリ入門:Pythonでデータ解析をマスターする基本ガイド
Pandasライブラリ入門:Pythonでデータ解析をマスターする基本ガイド
1. データの読み込み
今回使用するデータはこちらからダウンロードできます。
PandasではCSVやExcelなどのファイルからデータを読み込むことができます。
以下の例ではCSVファイルを読み込みます。
import pandas as pd
data = pd.read_csv("missing_data.csv")
data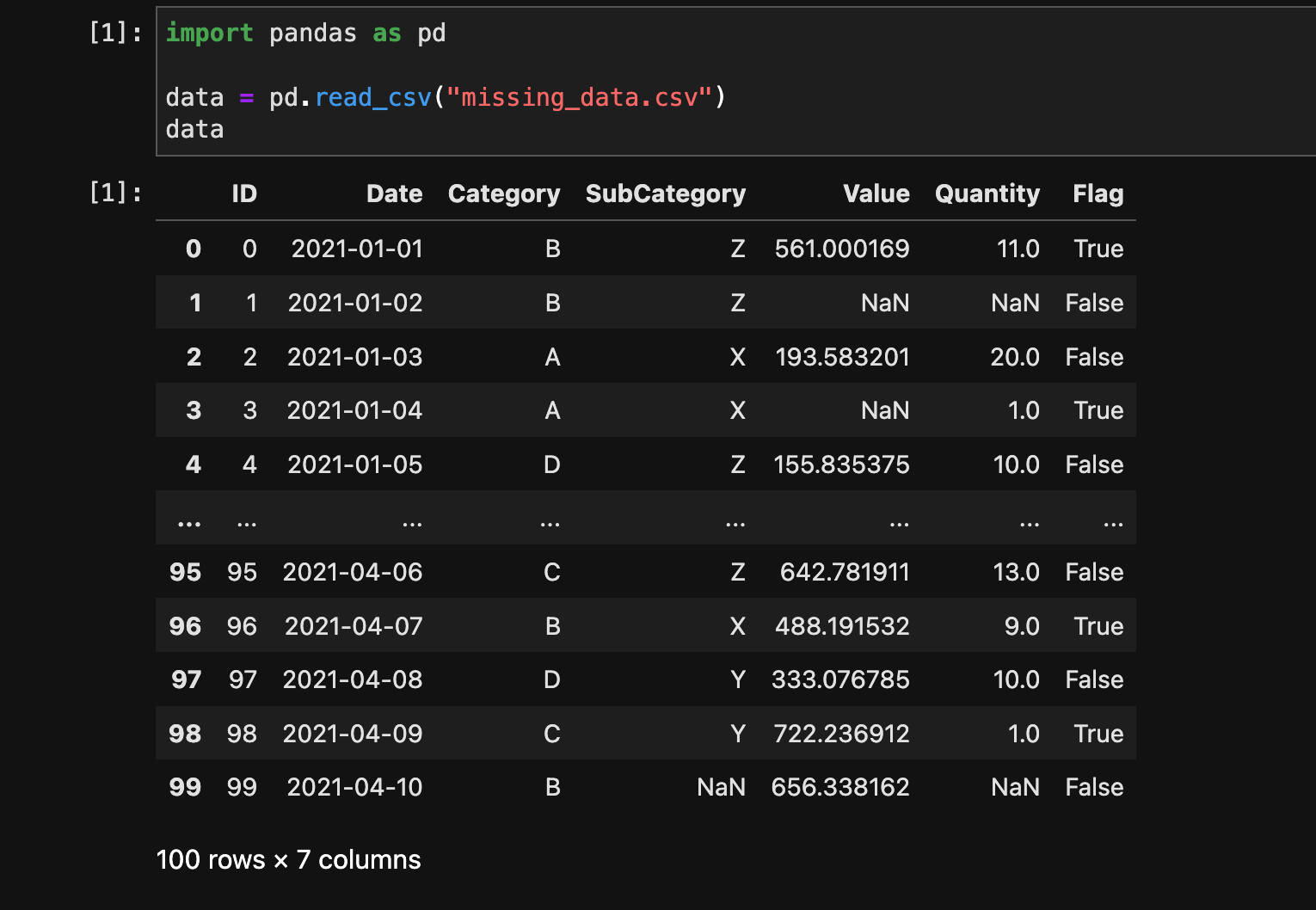
2. 欠損値の処理
欠損値の削除
欠損値が含まれる行や列を削除するには、dropna()メソッドを使用します。
data.dropna(axis=0) # 欠損値が含まれる行を削除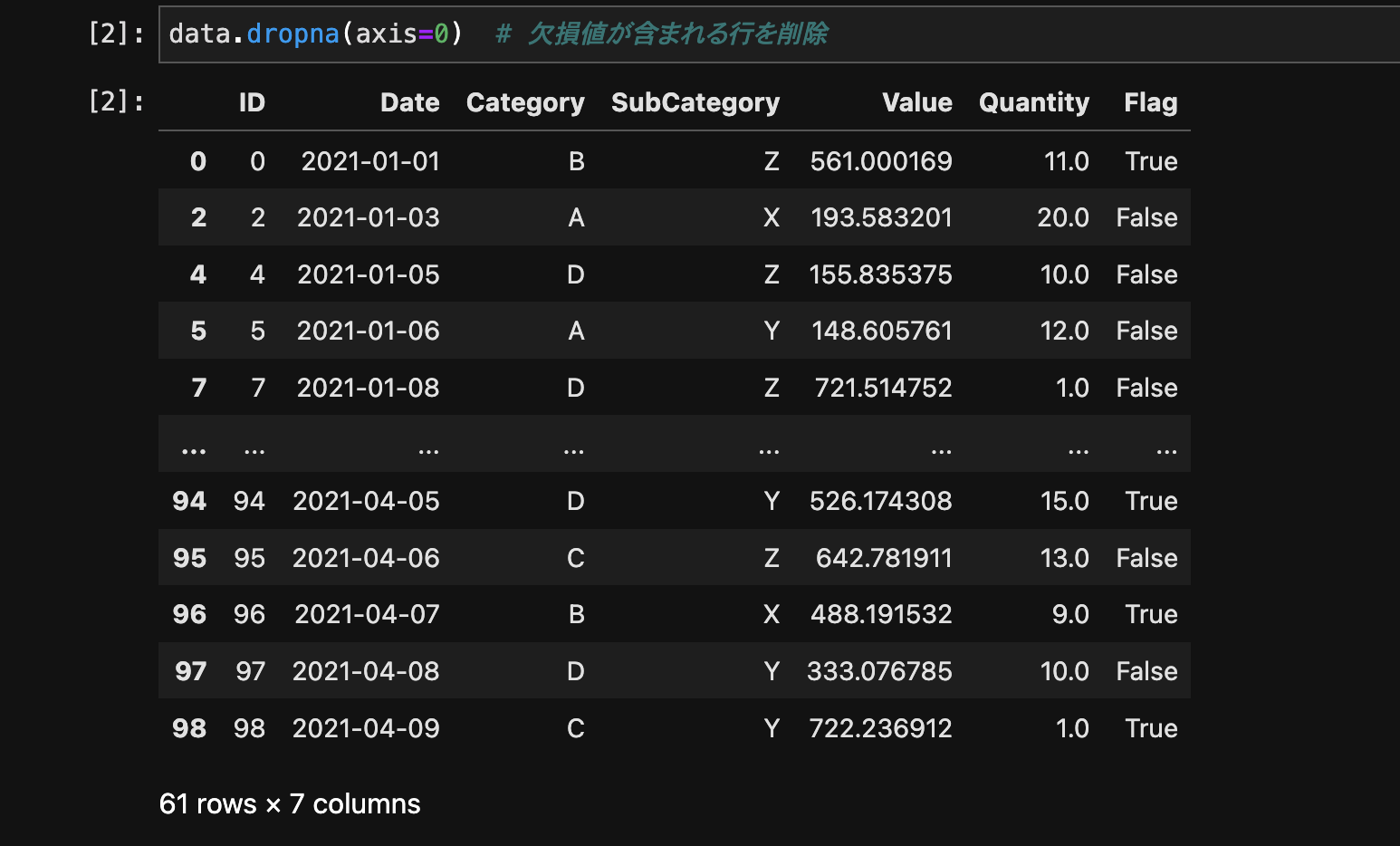
data.dropna(axis=1) # 欠損値が含まれる列を削除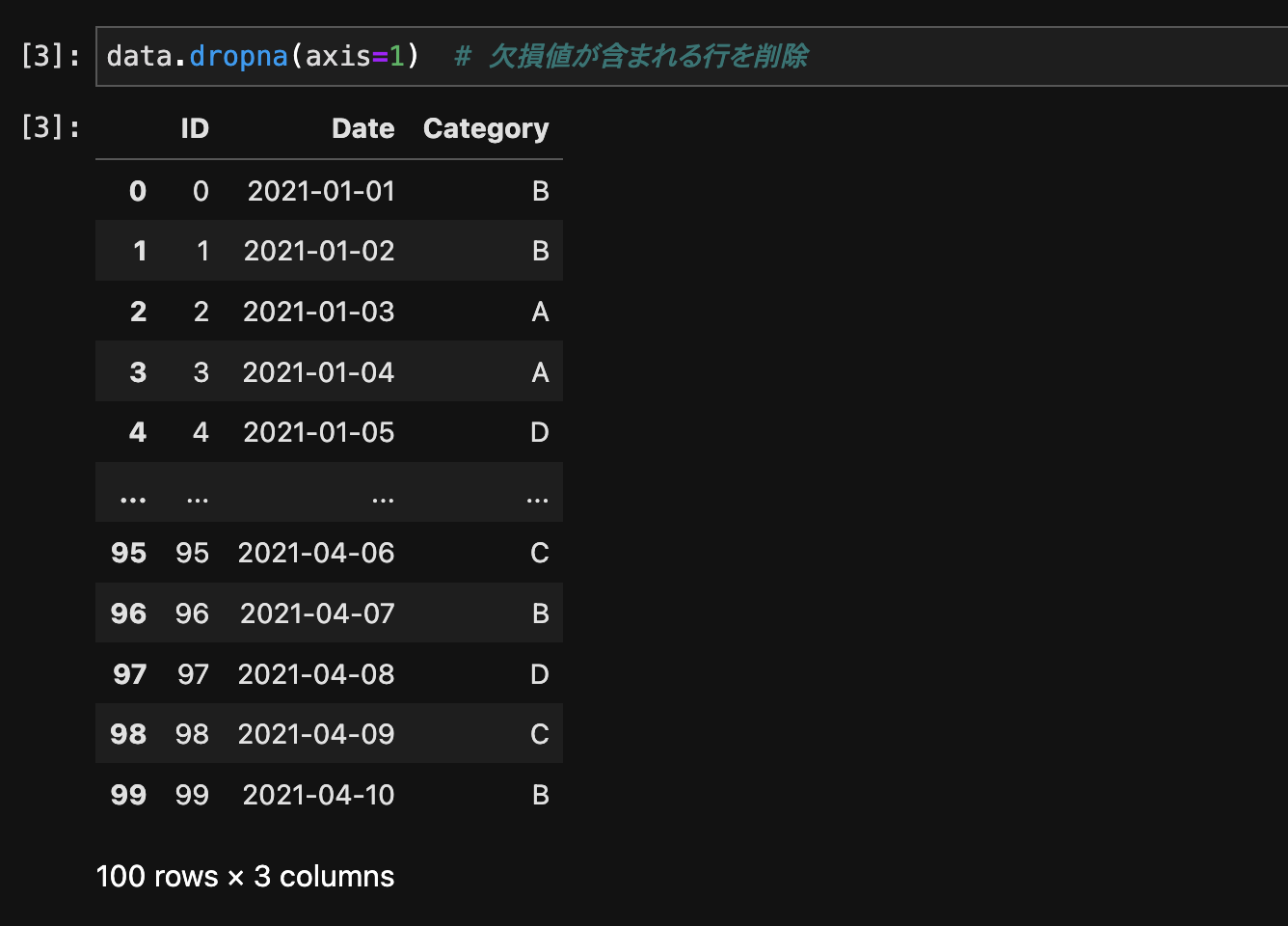
欠損値の補間
欠損値を補間するには、fillna()メソッドを使用します。
data.fillna(0) # 欠損値を特定の値で補間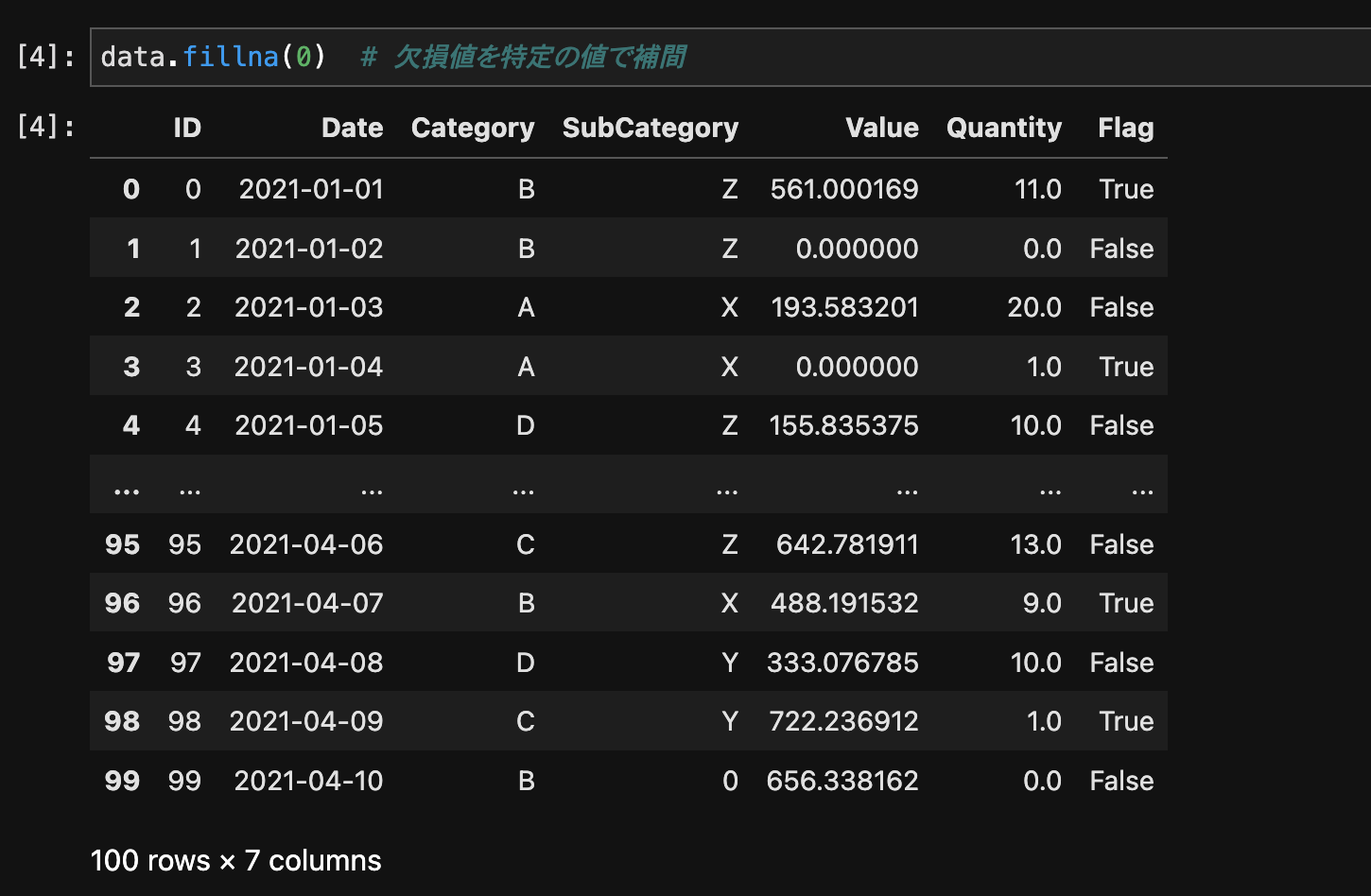
data.fillna(method="ffill") # 前の値で補間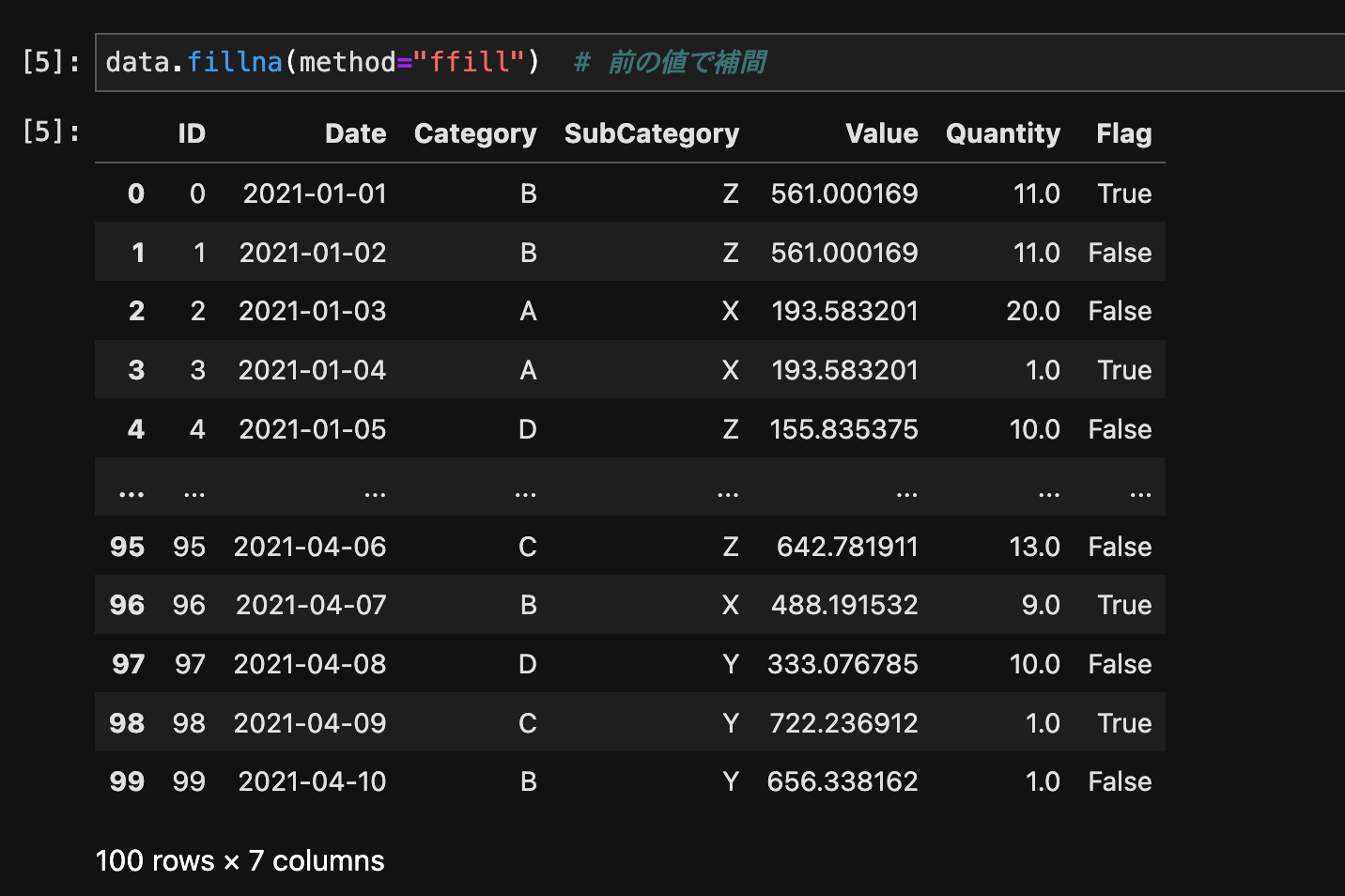
data.fillna(method="bfill") # 後ろの値で補間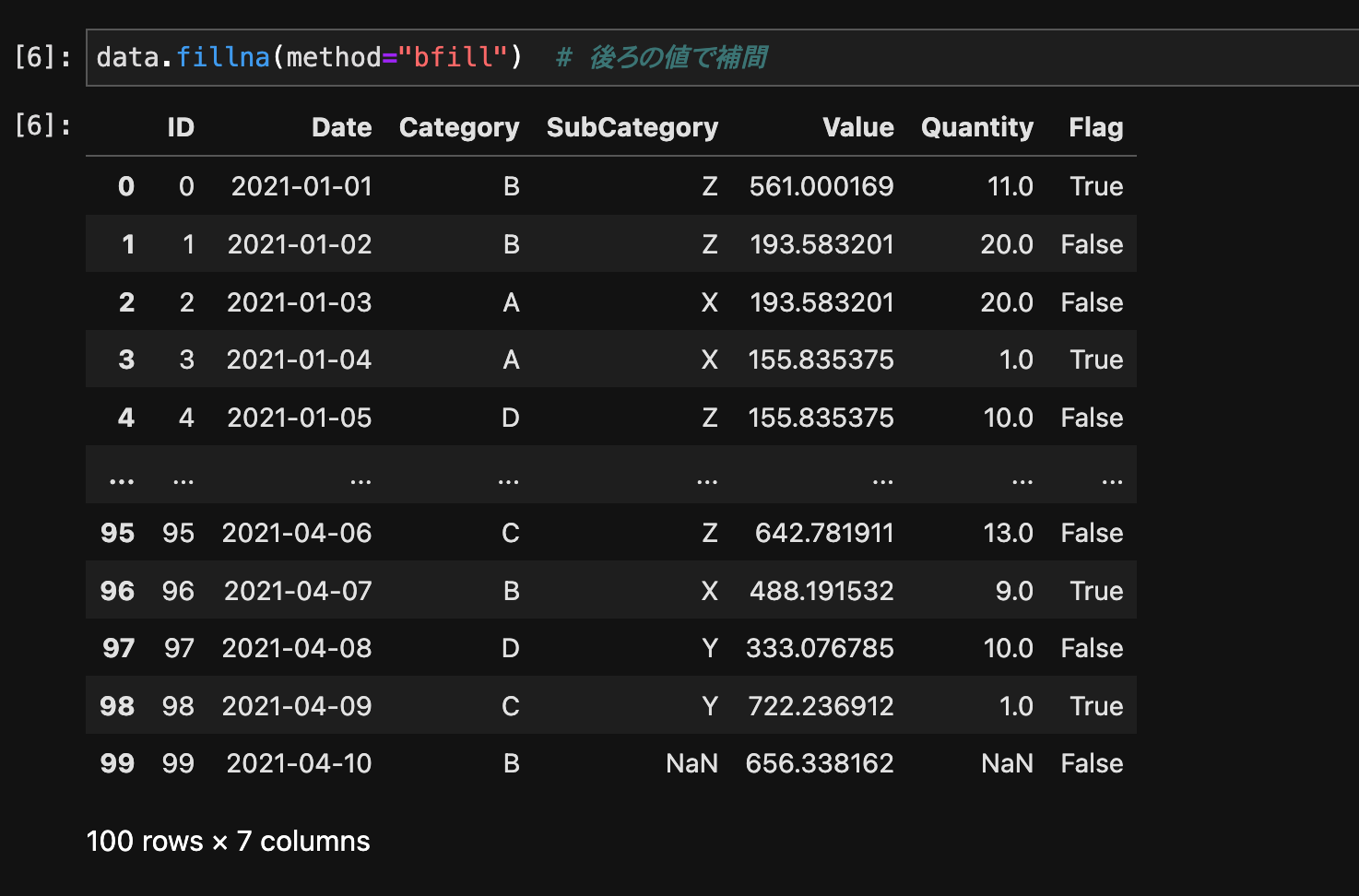
3. カテゴリ変数の処理
ラベルエンコーディング
ラベルエンコーディングとは、カテゴリ変数(文字列やラベルなど)を数値に変換する手法です。これにより、機械学習アルゴリズムが理解しやすい形でデータを扱うことができます。たとえば、色を表すカテゴリ変数(「赤」、「青」、「緑」など)がある場合、ラベルエンコーディングはこれらを連続した整数値(例えば「0」、「1」、「2」など)に割り当てます。
ただし、この方法には注意が必要です。数値に変換する際に、本来無関係なカテゴリ間に数学的な関係(例えば「赤 < 青 < 緑」のような大小関係)が生じることがあります。そのため、このような順序関係がデータに意味を持たない場合は、ワンホットエンコーディングのような他の手法を検討することが推奨されます。ワンホットエンコーディングでは、各カテゴリを独立した列として表現し、該当するカテゴリだけに「1」を、それ以外には「0」を割り当てます。
ラベルエンコーディングを行うには、map()メソッドを使用します。
mapping = {"A": 1, "B": 2, "C": 3, "D": 4}
data["encoded_column"] = data["Category"].map(mapping)
data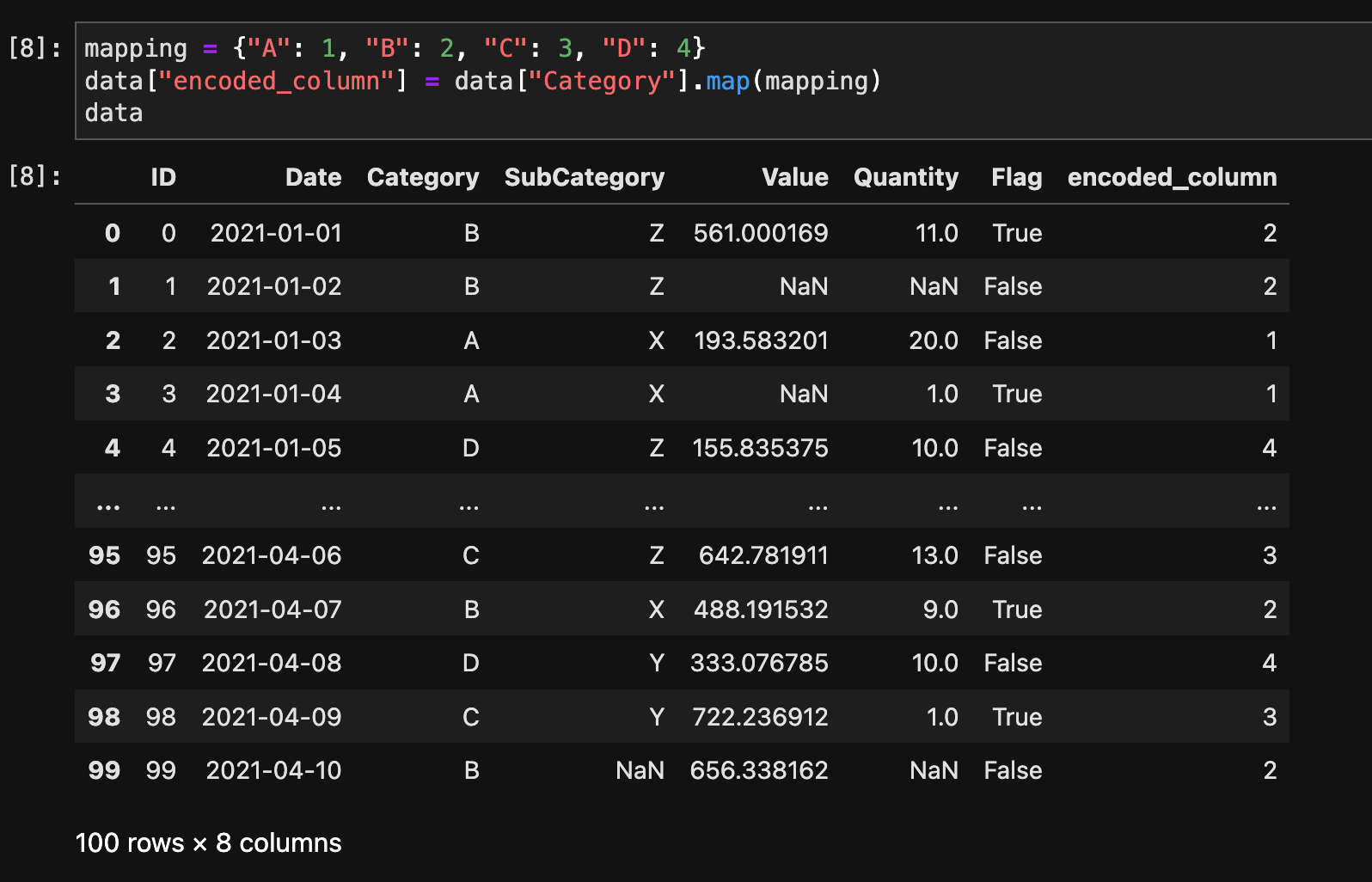
ワンホットエンコーディング
ワンホットエンコーディングは、カテゴリ変数を扱う一般的な手法で、特に機械学習モデルで広く利用されています。この手法では、カテゴリ変数の各カテゴリを新しい特徴(または列)として表現し、該当するカテゴリの列に「1」を、それ以外の列には「0」を割り当てます。これにより、カテゴリ間の無関係性が保持され、モデルが誤解釈をすることなくデータを解釈できます。
たとえば、色のカテゴリ変数に「赤」、「青」、「緑」という3つの値がある場合、ワンホットエンコーディングでは次のようになります:
- 赤 = [1, 0, 0]
- 青 = [0, 1, 0]
- 緑 = [0, 0, 1]
この方法は、特にカテゴリ間に順序関係がない場合(例えば色や都市名など)に適しています。各カテゴリが独立した特徴としてモデルに入力されるため、互いに影響を与えることなく処理されます。ただし、カテゴリ数が非常に多い場合は、データの次元が大きくなりすぎるという問題が発生する可能性があります。そのため、非常に多くのカテゴリが存在する場合は、次元削減技術や別のエンコーディング手法が検討されることがあります。
ワンホットエンコーディングを行うには、get_dummies()関数を使用します。
encoded_data = pd.get_dummies(data, columns=["Category"])
encoded_data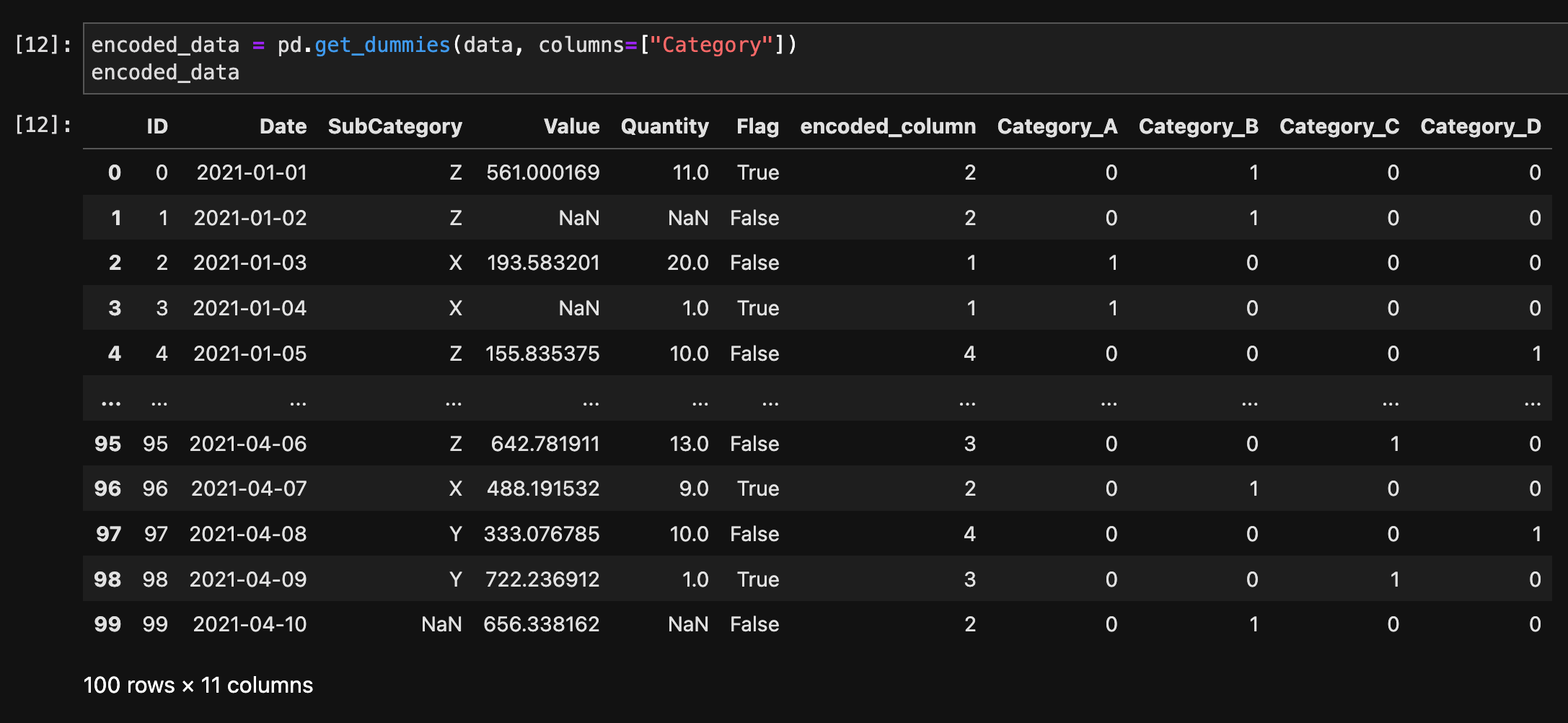
4. 時系列データの処理
日付・時刻の変換
文字列形式の日付・時刻をdatetimeオブジェクトに変換するには、to_datetime()関数を使用します。
encoded_data["Date"] = pd.to_datetime(encoded_data["Date"])
encoded_data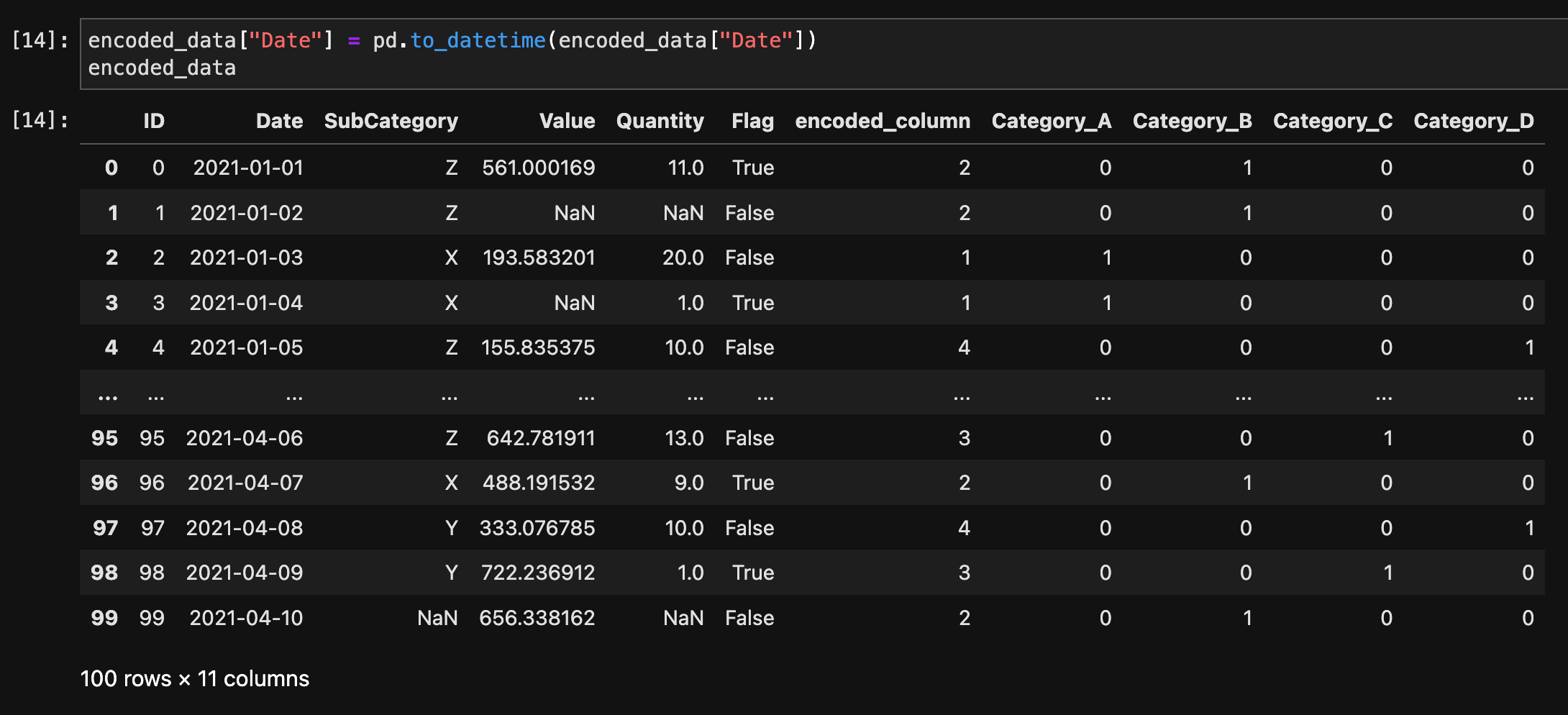
時系列データの抽出
日付・時刻の情報を抽出するには、dtアクセサを使用します。
encoded_data["year"] = encoded_data["Date"].dt.year
encoded_data["month"] = encoded_data["Date"].dt.month
encoded_data["day"] = encoded_data["Date"].dt.day
encoded_data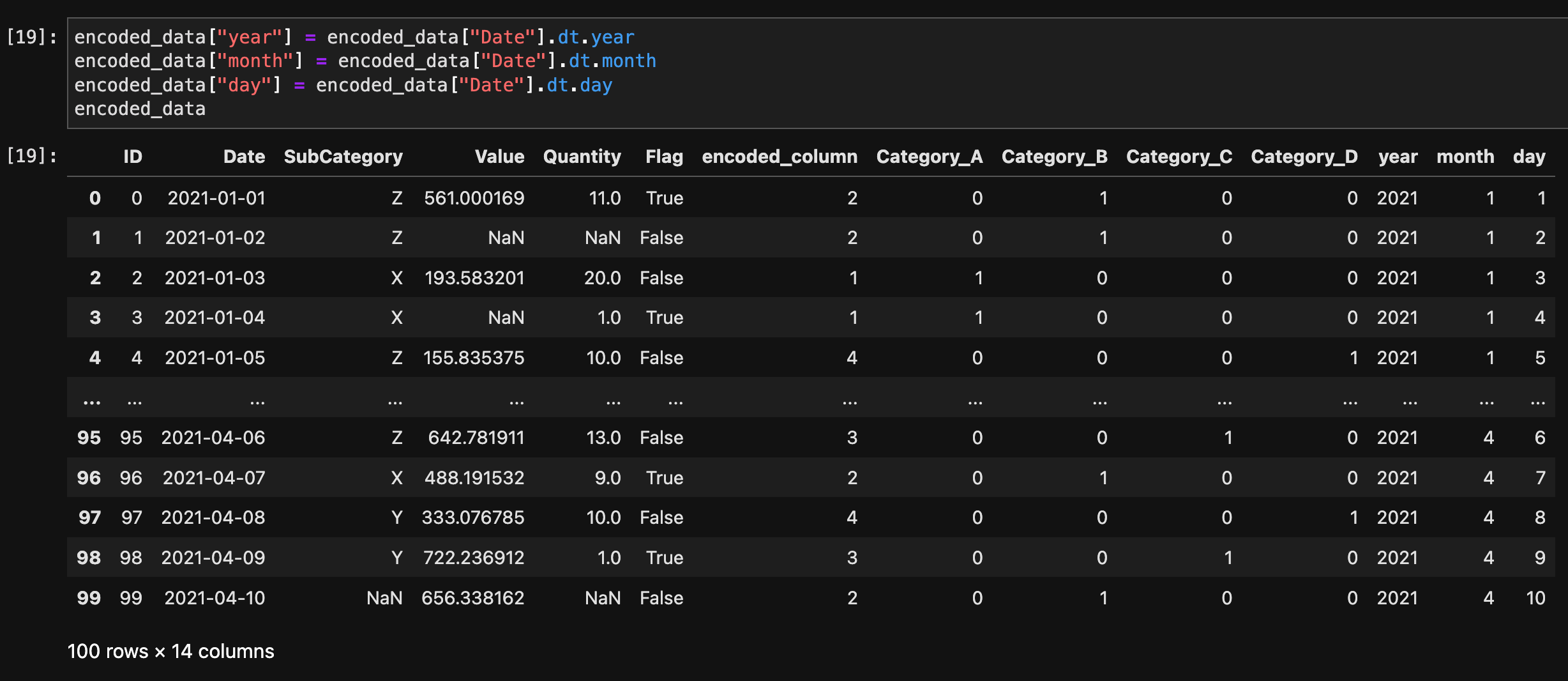
時系列データのリサンプリング
時系列データをリサンプリングするには、resample()メソッドを使用します。
encoded_data.set_index("Date", inplace=True)
resampled_data = encoded_data.resample("M").mean() # 月単位でリサンプリング
resampled_data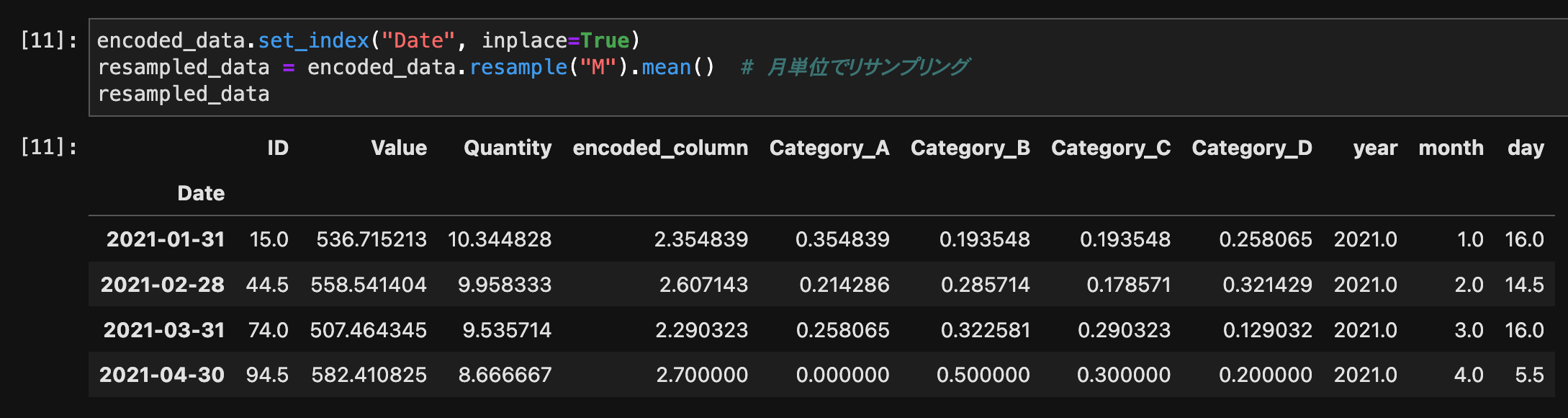
5. データの正規化
Min-Max正規化
Min-Max正規化(最小最大正規化とも呼ばれる)は、データのスケーリング(規模調整)手法の一つで、データセット内の各特徴の値を特定の範囲(通常は0から1、あるいは-1から1)にスケーリングする方法です。この手法は、データの元の分布を保ちつつ、異なる特徴量間でのスケールの違いを調整し、モデルが特徴量のスケールに依存しないようにするために用いられます。
Min-Max正規化の式
Min-Max正規化は以下の式で計算されます:
ここで、は元のデータ値、はデータセット内の最小値、は最大値です。この式により、変換後のデータ値は0から1の範囲に収まります。
例
例えば、ある特徴量が0から100の範囲の値を取るとします。この特徴量の値が20の場合、Min-Max正規化を適用すると以下のように計算されます:
このように、Min-Max正規化を使用すると、データの相対的な位置関係や分布の形状は保たれつつ、すべての特徴が同じスケールに調整されます。これは、ニューラルネットワークや距離に基づくアルゴリズム(例えばK近傍法)など、データのスケールに敏感な機械学習アルゴリズムで特に重要です。
Min-Max正規化を行うには、次の式を使用します。
normalized_data = (resampled_data - resampled_data.min()) / (resampled_data.max() - resampled_data.min())
normalized_data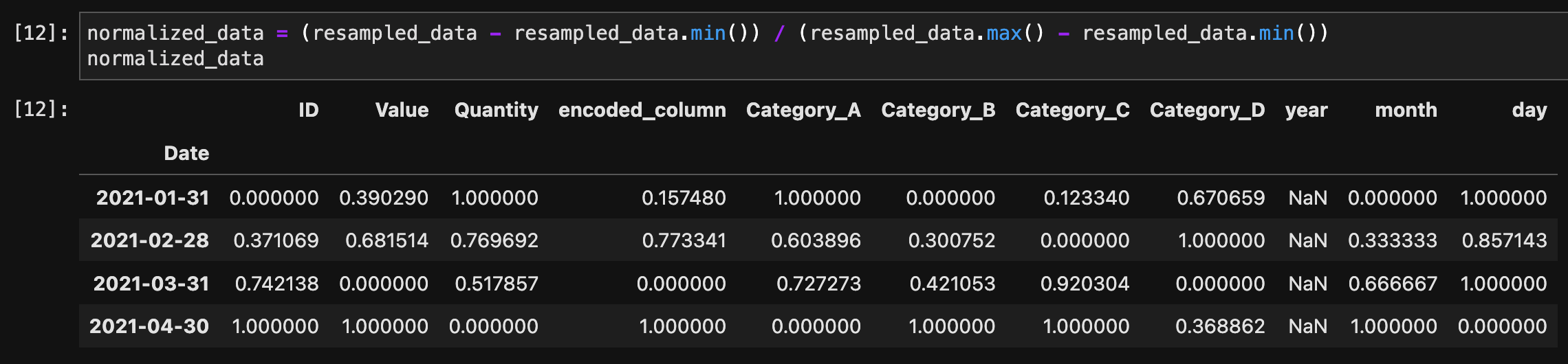
Zスコア正規化
Zスコア正規化(または標準化)は、データのスケーリング技法の一つで、各データポイントから平均値を引き、その結果を標準偏差で割ることによって行われます。この手法によって、データセットは平均が0、標準偏差が1の分布に変換されます。これは、異なるスケールの特徴量を比較可能にし、多くの機械学習アルゴリズムで効果的な性能を発揮するために重要です。
Zスコア正規化の数式
Zスコアの計算は以下の式で表されます:
ここで、は元のデータポイント、はデータセットの平均値、は標準偏差です。この変換により、データセットは標準正規分布に従うように調整されます。
例
データセットの平均が50、標準偏差が10で、あるデータポイントが60の場合、そのZスコアは次のように計算されます:
この値は、元のデータポイントがデータセットの平均から1標準偏差だけ離れていることを意味します。
Zスコア正規化の利点と注意点
利点:
- 特徴間のスケールが異なる場合でも、データを同一の尺度に調整するため、アルゴリズムが特徴を公平に評価できるようになります。
- 多くの機械学習アルゴリズム(特に距離ベースの方法や、正規化の影響を受けやすいアルゴリズム)で性能が向上します。
注意点:
- 元のデータに外れ値が含まれる場合、これらの外れ値によって平均と標準偏差が歪められる可能性があるため、その影響を受けやすくなります。
- データが元々正規分布に従わない場合、この変換後のデータが最適な形で分布するとは限りません。
Zスコア正規化を行うには、次の式を使用します。
normalized_data = (resampled_data - resampled_data.mean()) / resampled_data.std()
normalized_data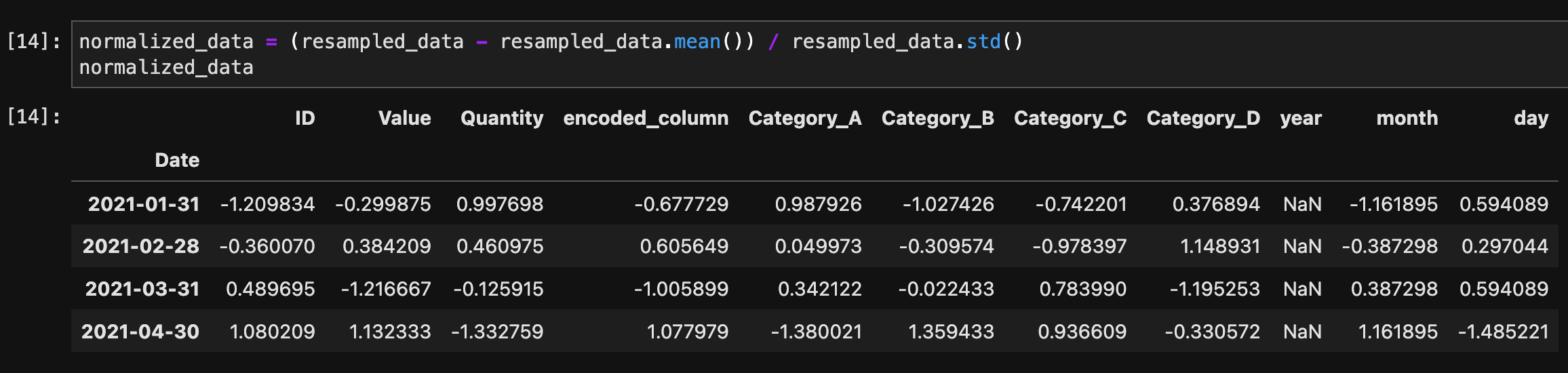
6. データの可視化
PandasはMatplotlibと連携して、データフレームから直接グラフを描画する機能を提供しています。
折れ線グラフ
折れ線グラフを描画するには、plot()メソッドを使用します。
resampled_data.plot(x="Quantity", y="Value")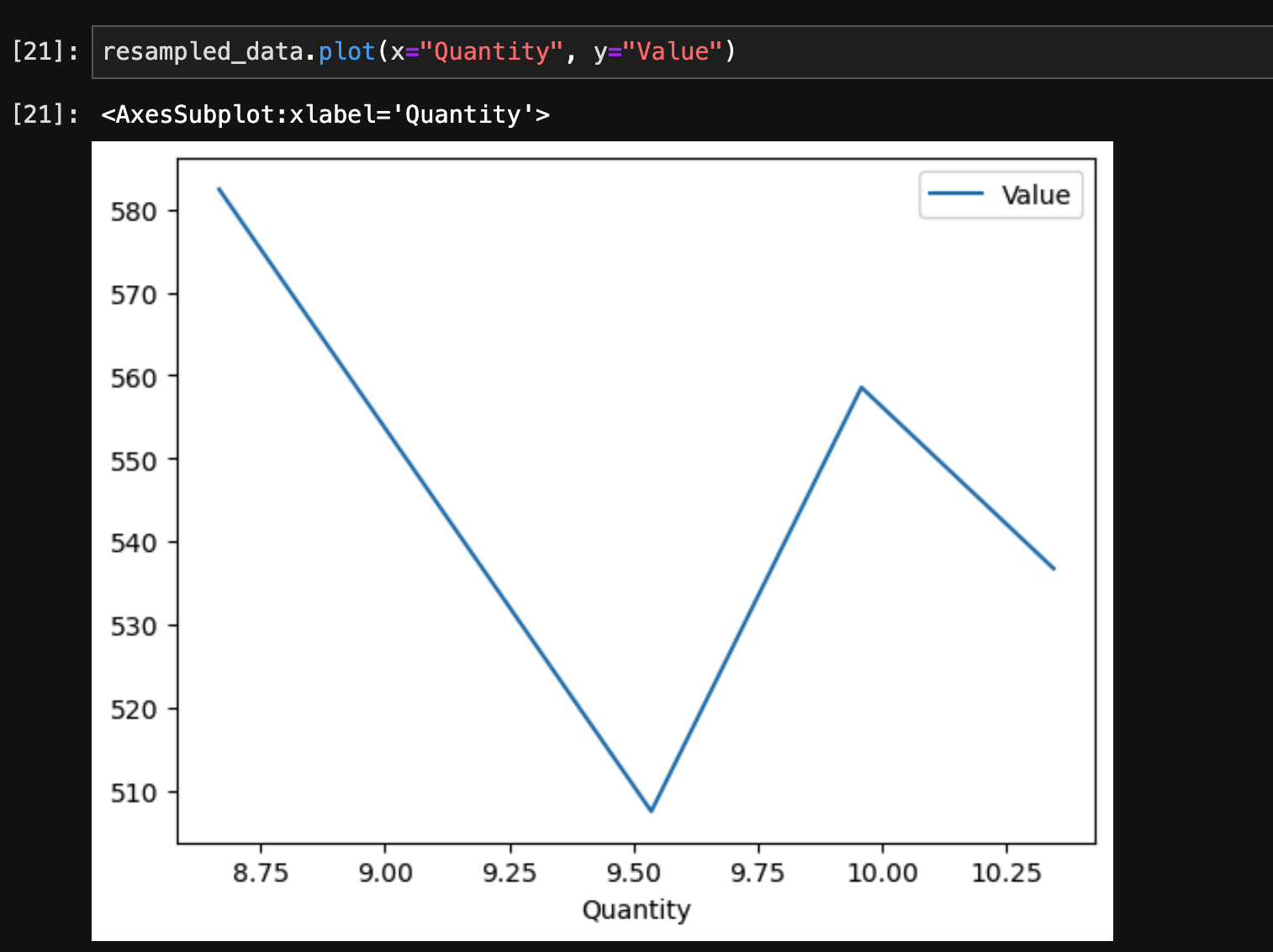
棒グラフ
棒グラフを描画するには、plot.bar()メソッドを使用します。
# 日付インデックスの書式を変更(時間部分を除去)
resampled_data.index = resampled_data.index.date
# 書式化した日付で棒グラフを描画
resampled_data['Quantity'].plot.bar(ylabel='Quantity', xlabel='Date')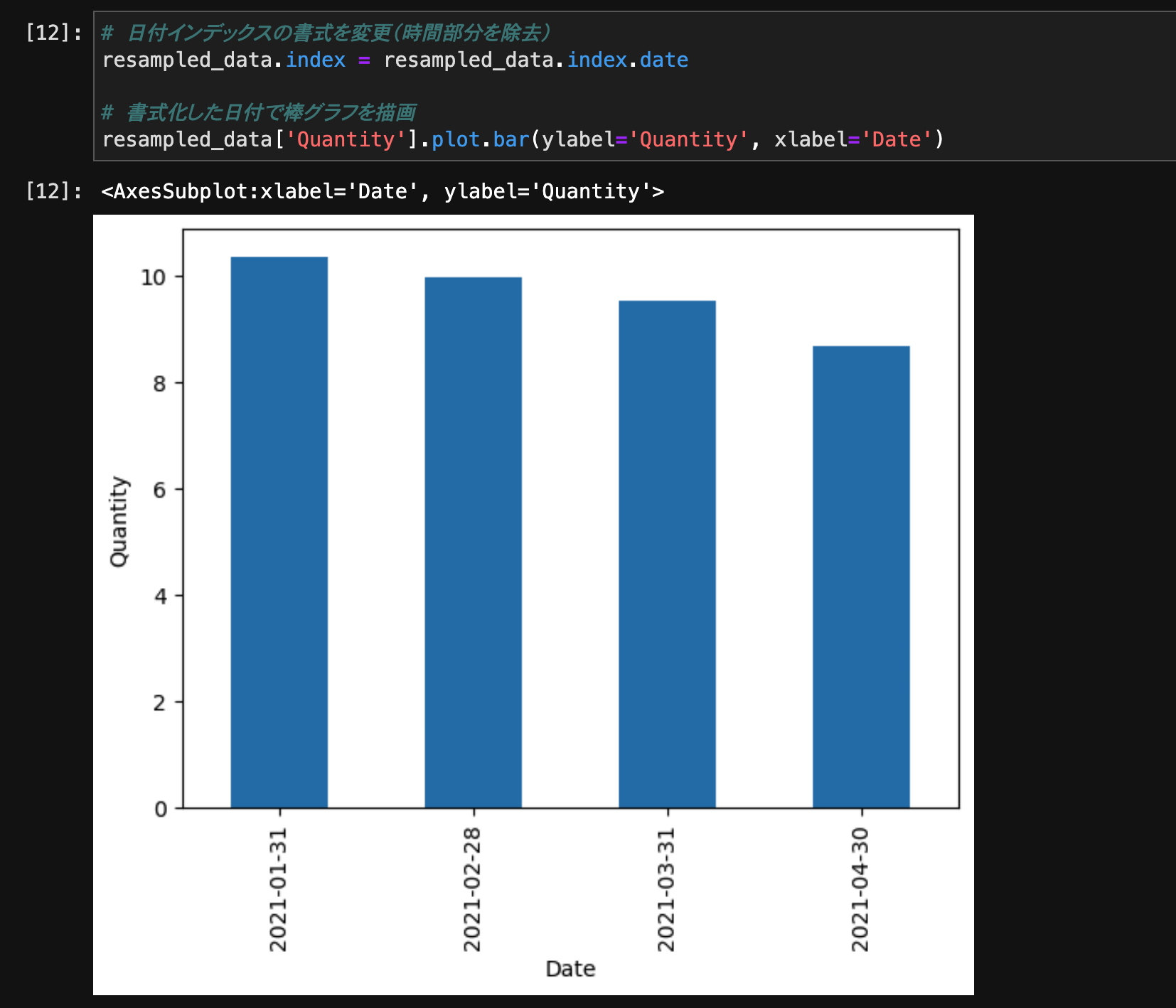
散布図
散布図を描画するには、plot.scatter()メソッドを使用します。
encoded_data.plot.scatter(x="Quantity", y="Value")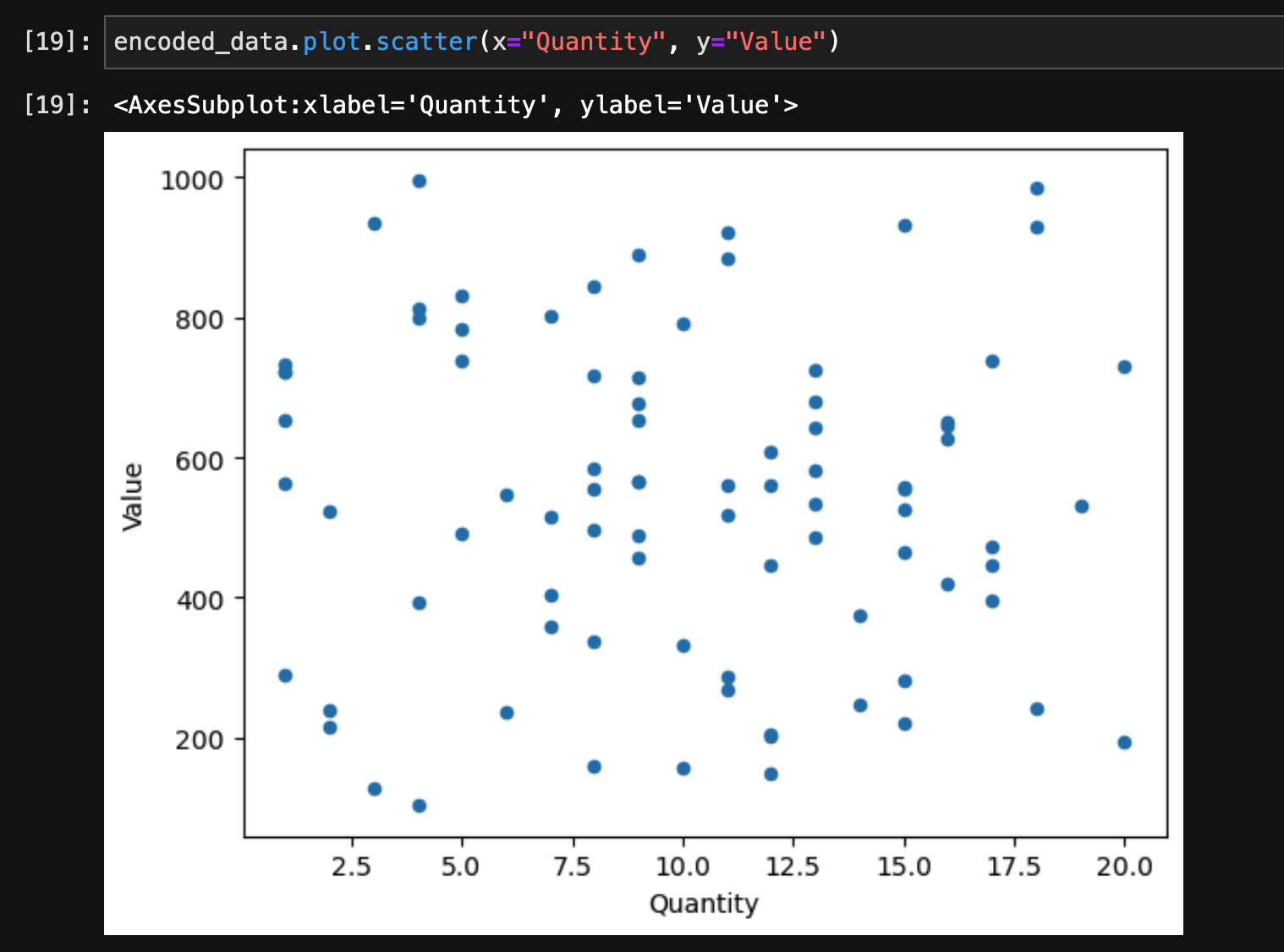
ヒストグラム
ヒストグラムを描画するには、plot.hist()メソッドを使用します。
encoded_data["Value"].plot.hist()
まとめ
この記事では、Pandasライブラリの応用的な使い方を解説しました。欠損値の処理、カテゴリ変数の処理、時系列データの処理、データの正規化、データの可視化など、これらの応用的な操作をマスターすることで、さらに高度なデータ解析が可能になります。
Pandasは非常に多機能なライブラリであり、その全てをカバーすることは難しいですが、この記事で紹介した機能を使いこなすことで、データ解析の幅が広がります。継続的に実践を重ねることで、Pandasを使ったデータ解析のスキルを磨いていきましょう。
最後までお読みいただきありがとうございます!
この記事へのご質問やアドバイスがありましたら、ぜひコメントもお待ちしております。
またXでもVBA、Pythonに関するアウトプットをしていますので、🔽フォローいただけますと幸いです😆