

1️⃣ はじめに
この連載では、私がこれまでに経験したPythonのエディター・環境構築についてシェアしています。
前回は、Anacondaを使った環境構築に焦点を当てましたが、第2回目の今回は初心者にも優しく、マシンパワーもカバーしてくれるGoogle Colaboratoryの魅力に迫りたいと思います。
🔻前回の記事はこちらから
📄![]() "Pythonの環境構築を振り返ります:第1回 - カレールウとAnaconda!?”
"Pythonの環境構築を振り返ります:第1回 - カレールウとAnaconda!?”
Google Colaboratory(以下Google Colab)は、データサイエンスや機械学習の初心者にとって非常に取り組みやすい環境です。
私はUdemyの講座をきっかけにGoogle Colabを使い始めました。
Googleのプログラミング言語といえばGAS(Google Apps Scripts)が有名ですよね!

GASはスプレッドシートや、Googleカレンダーとの連携などで少し触ったことがありました。
一方でGoogle Colabは当時その存在すら知らず、当初はGoogleにはPythonのコーディング環境もあるのか〜、ふーんくらいの感じでしたが…
操作してみてびっくり!!
あまりにも快適なエディター環境と強力な機能に驚かされたというのが第一印象でした。

Google ColabはPython初心者が直面する環境構築のハードルを大きく下げてくれる上に、その強力なエディター機能は非常に魅力的でした。
また、最近ではGoogle Geminiを活用したコーディング補完機能も実装されて、ますます便利になっています。
この記事を通じて、Python学習の一環としてGoogle Colabを取り入れるメリットについて、皆さんにお伝えできればと思います。
では、早速本題に入っていきましょう!
これまでの私のPythonの開発環境の変遷
| No. | 環境 | 主な特徴 | 利点 |
| 1 | Anaconda | データサイエンスと機械学習向けのPythonディストリビューション。 多数のライブラリが含まれる。 | 多数の科学計算ライブラリが含まれており、設定が容易。 |
| 2 | Google Colab | クラウドベースのPython実行環境。 GPUやTPUの利用が可能。 | 無料で高性能な計算リソースが利用可能。 設定不要で手軽に使える。 |
| 3 | Docker | アプリケーションをコンテナ内で実行するためのプラットフォーム。 | 環境の再現性と移植性が高く、 様々なシステムで同じ環境を作れる。 |
| 4 | Python in Excel | Excel内でPythonスクリプトを実行するためのアドオンやツール。 | Excelデータを直接Pythonで扱える。 ビジネスシーンでのデータ処理に便利。 |
| 5 | ASDF + Poetry | ASDFは複数のランタイムを管理するツール、Poetryは依存関係の管理とパッケージングを行うツール。 | 複数のPythonバージョンと依存関係を簡単に管理できる。 開発環境の構築が容易になる。 |
2️⃣ UdemyでGoogle Colabに入門
私のGoogle Colabとの出会いは、Udemyの講座でした。

Pythonを使った機械学習にチャレンジするためデータサイエンスに関する講座を購入しました。
購入した講座は講師の方による丁寧な説明に沿ったハンズオンスタイルで進み、開発環境として推奨されていたのがGoogle Colabでした。
Google Colabの特徴

open in colabによるコードの共有
こちらの講座で特に便利だったのが、ノートブックを共有可能なopen in colabという機能です。
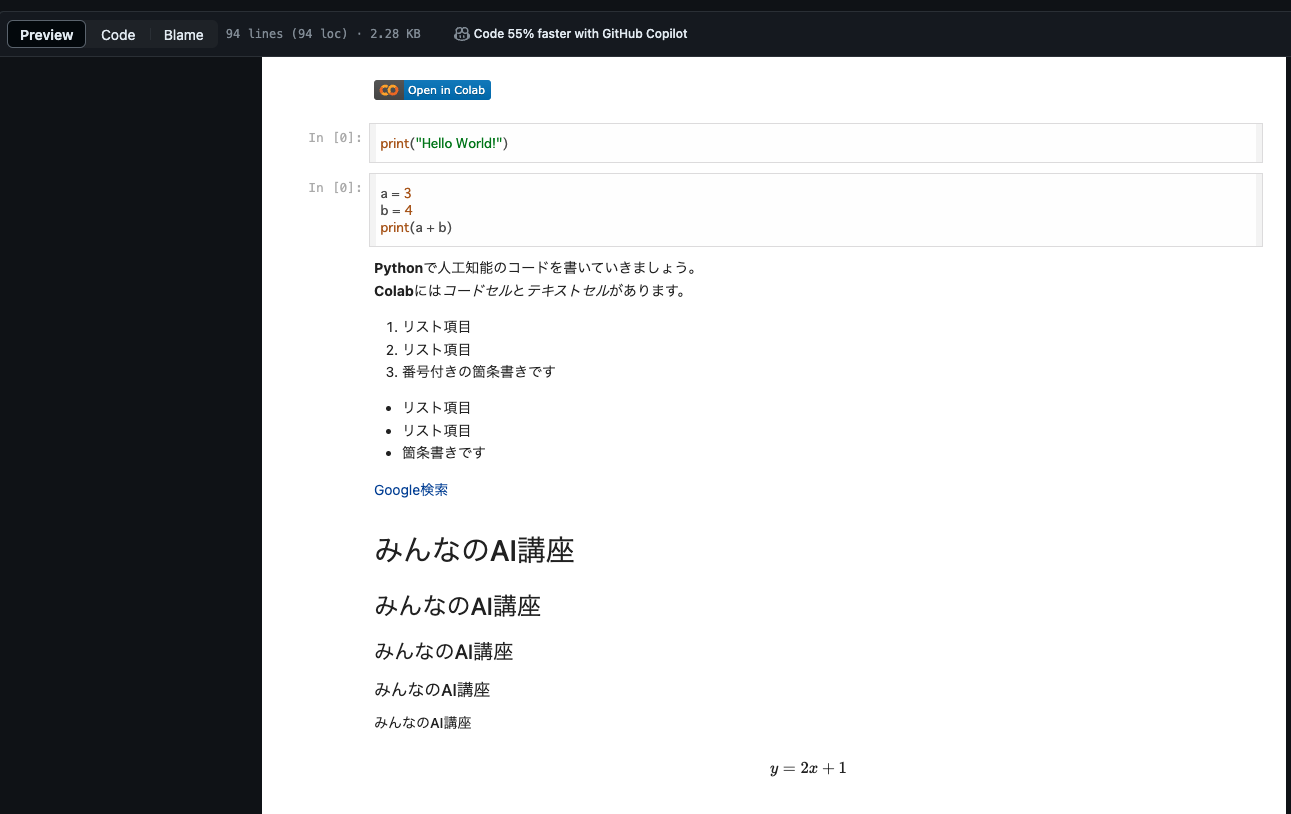
open in colabを使うことで、Udemy講座内で使用するコードや演習課題が記述されたJupyter Notebookを直接Google Colabで開いて利用することができました。
- open in colabのボタンをクリックするとGoogle Colabが開かれます。

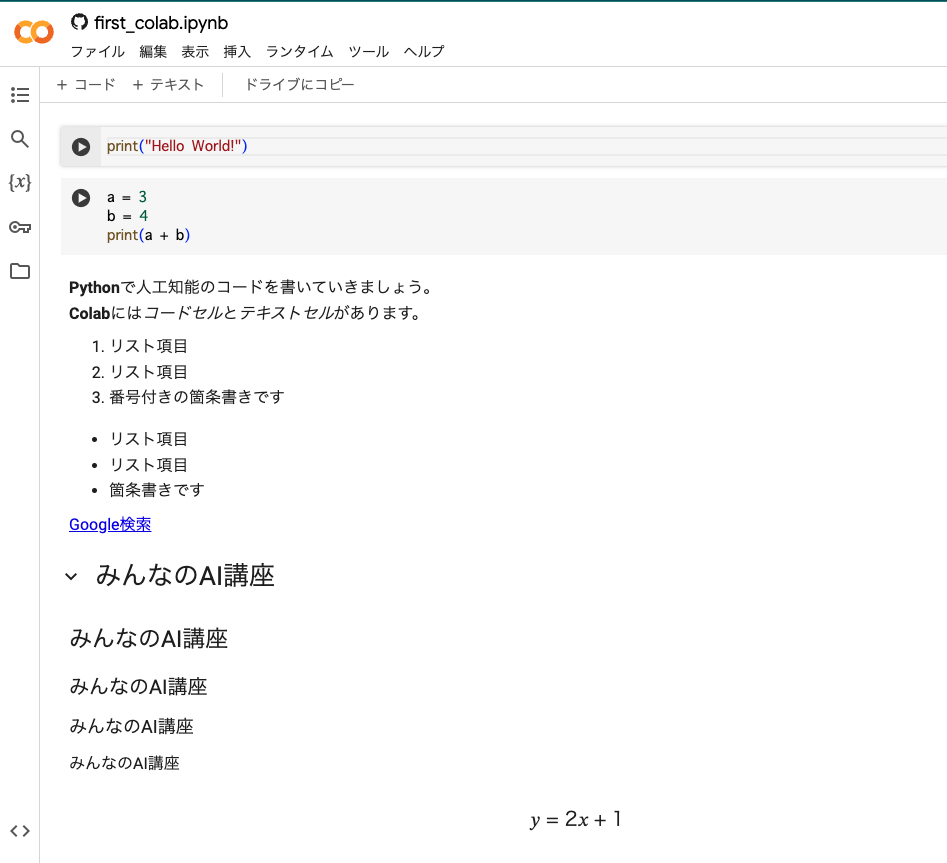
この機能のおかげで自身でコードをすべて記述しなくても、ざっくりとどのようにして機械学習モデルを構築するのか、そして実際にコードを実行して確認することができたので、実践 → 理論の順で機械学習の理解を深めることができました。
また、Google ColabはGoogleアカウントと連携しており、共有されたノートブックを自身のGoogle Driveに保存することも簡単でした。
学習の進捗管理や、自身の書いたコードと照合するなど非常に役立ちました。
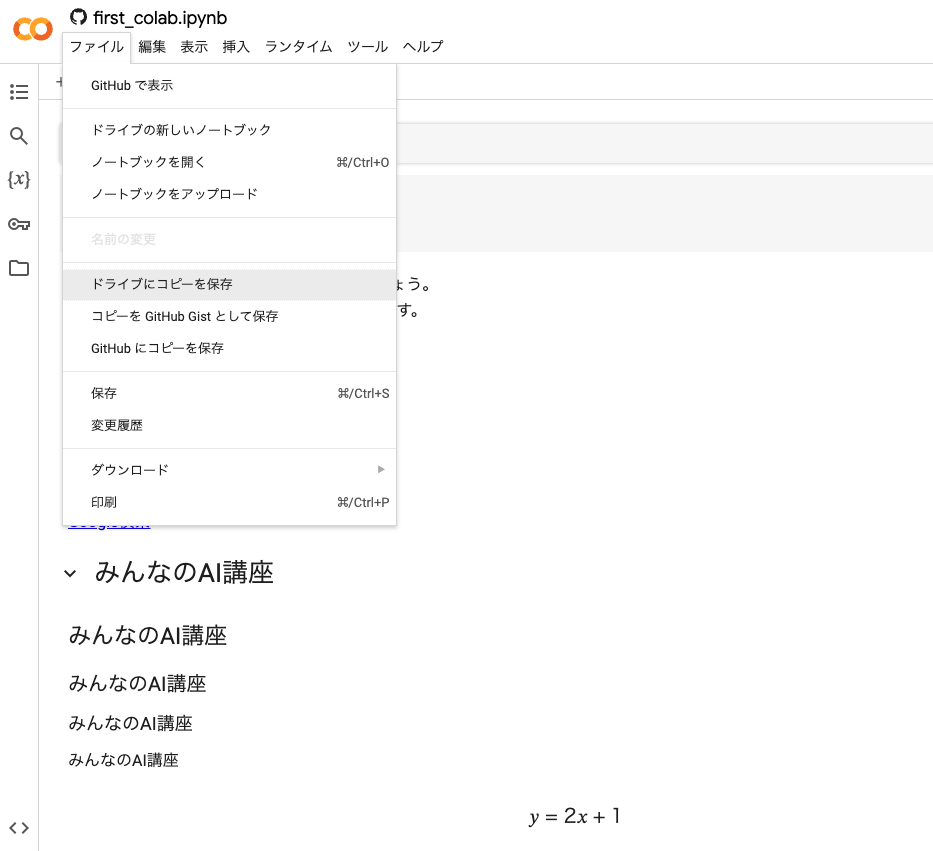
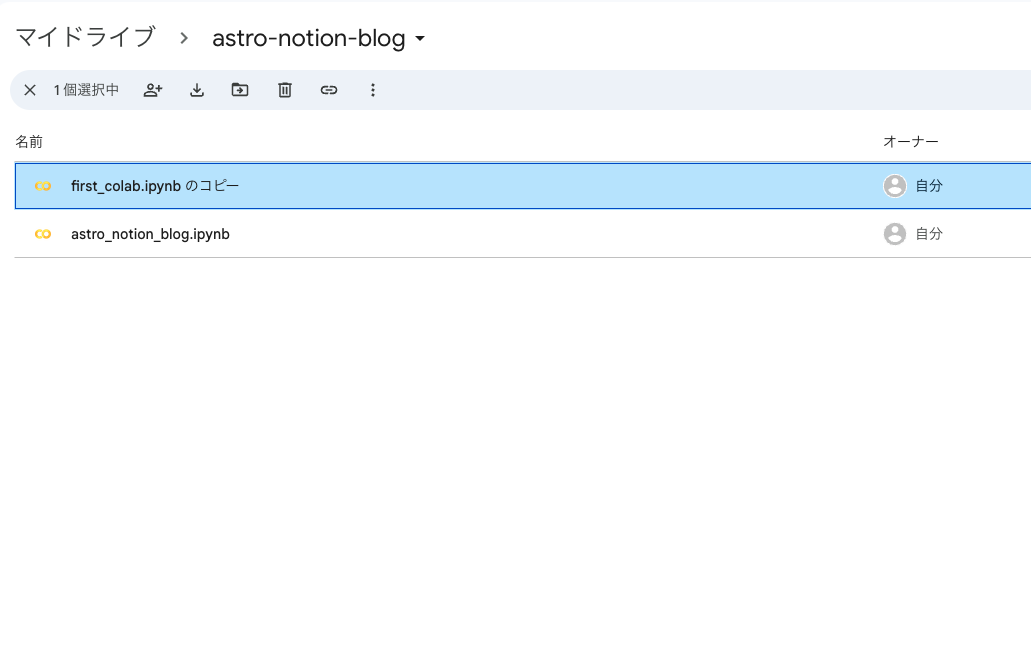
- ファイルの「ドライブにコピーを保存」とするとマイドライブにコピーされますので自身の学習中のフォルダに移動させて管理していました。
高度なリソースの提供について
さらに、Google Colabでは、高性能なリソースが無料で提供される点も大きな魅力です。
- ランタイムのタイプを変更の画面でハードウェアアクセラレータを選択できます。
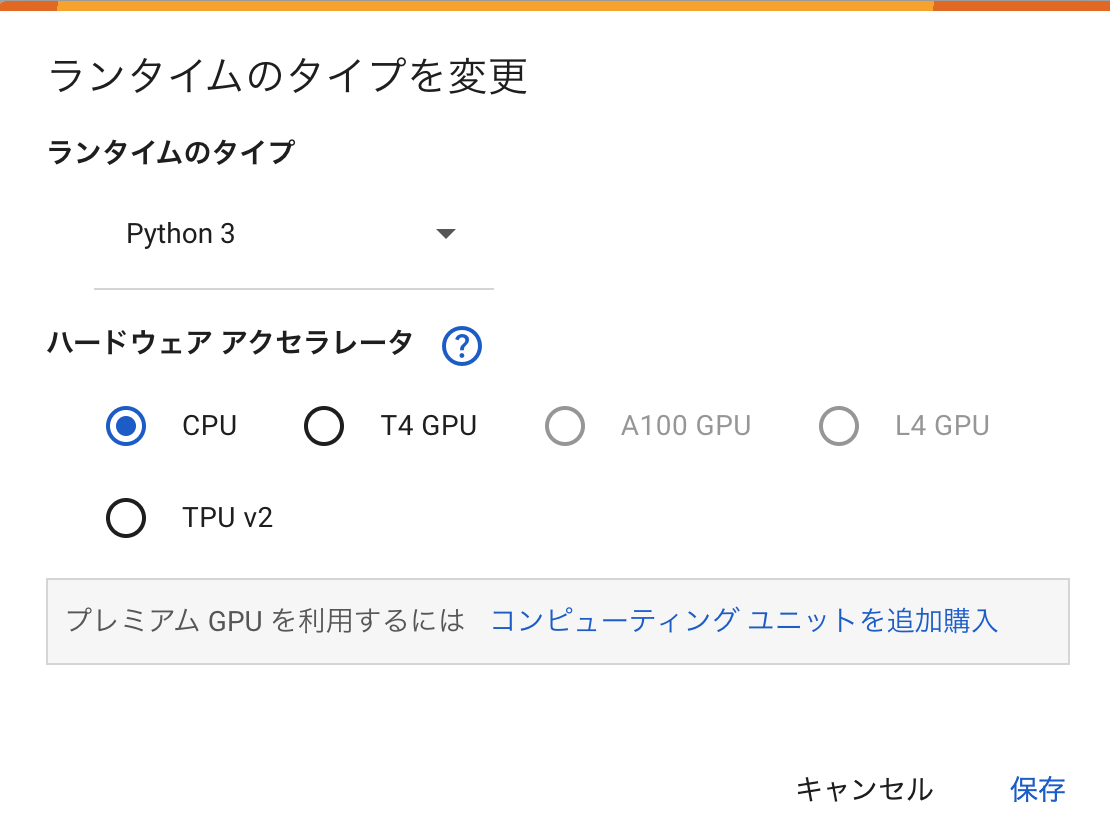
高価なPCを購入せずとも、GPUやTPUを用いた高度な機械学習が可能になります。
この点は、特にリソースに限りがあるPCを使用していた私にとって、学習の大きな助けとなりました。
Google Colabのおかげで、データサイエンスの世界にスムーズに足を踏み入れることができ、機械学習を学ぶ楽しさを実感できました。

Google Colabはこれから機械学習を始めようと思っている方に、ぜひ試してもらいたい環境であると感じています。
次のセクションでは、Google Colabの環境構築と基本操作についてもう少し詳しく見ていきましょう。
3️⃣ Google Colabで環境構築しコードを実行する方法
Google Colabの基本機能
- Jupyter Notebookベース
コードとテキストを組み合わせたノートブック形式で作業できます。
- 無料でGPUが使える
機械学習などの重い処理に適したGPUを無料で利用可能です。
- 主要なライブラリがプリインストール済み
NumPy、Pandas、TensorFlowなど、データ分析や機械学習に必要なライブラリが最初から使えます。
Google Colabは、Pythonを用いた機械学習やデータ分析に特化した環境として設計されています。
その最大の特徴は、何と言ってもブラウザベースで動作する点です。これにより、どんなデバイスからでもアクセスし、作業を行うことができます。
Google Colabの環境構築
- GoogleドライブからGoogle Colabを開きます。
- これで環境構築は完了です!簡単ですね!
- ノートブック名は左上のボックスで変更可能です。
- フォルダに戻るとファイル名がきちんと変更されています。
Pythonコードの入力方法や便利機能
- コードセルにPythonのコードを入力し、
Ctrl + EnterやShift + Enterで実行します。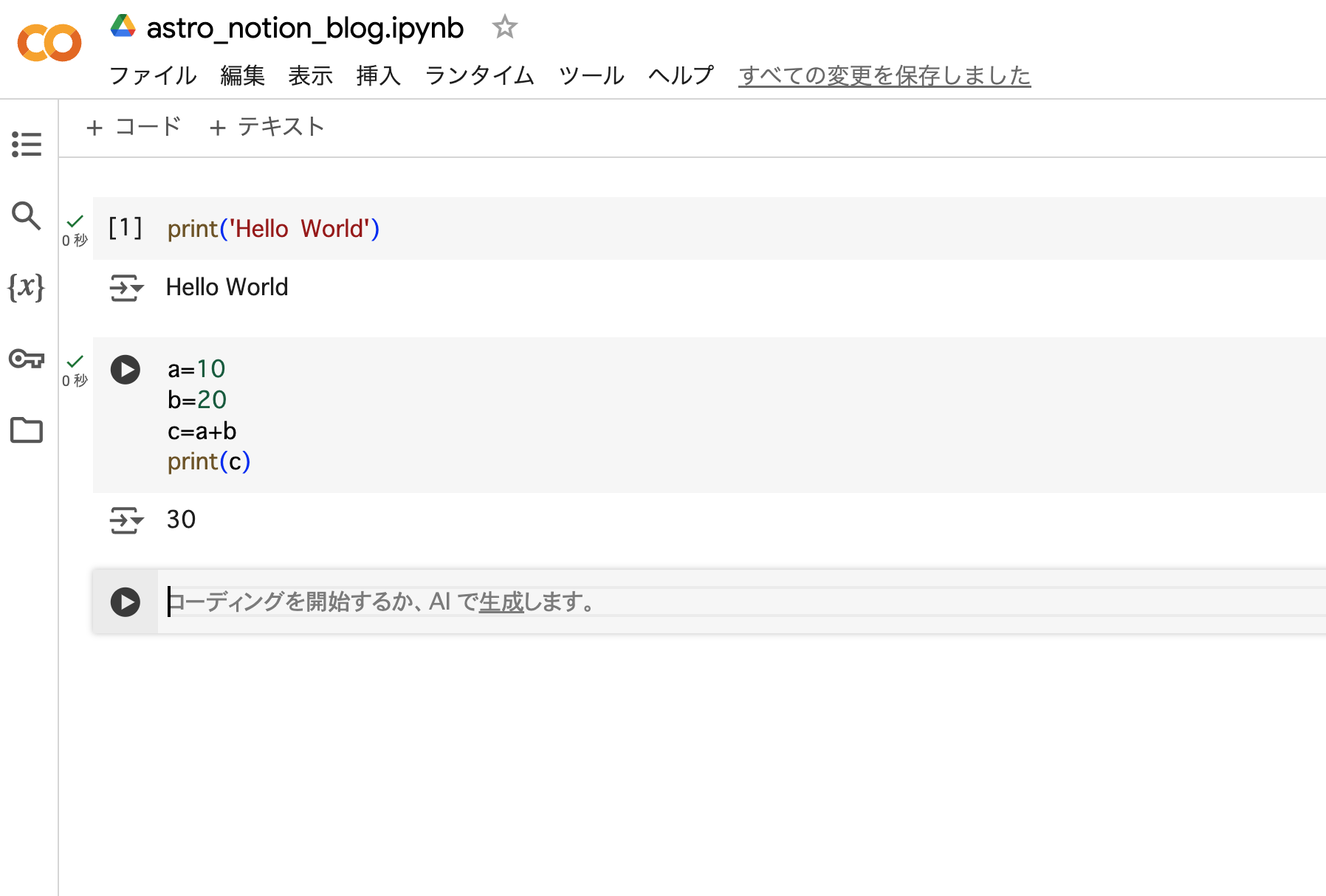
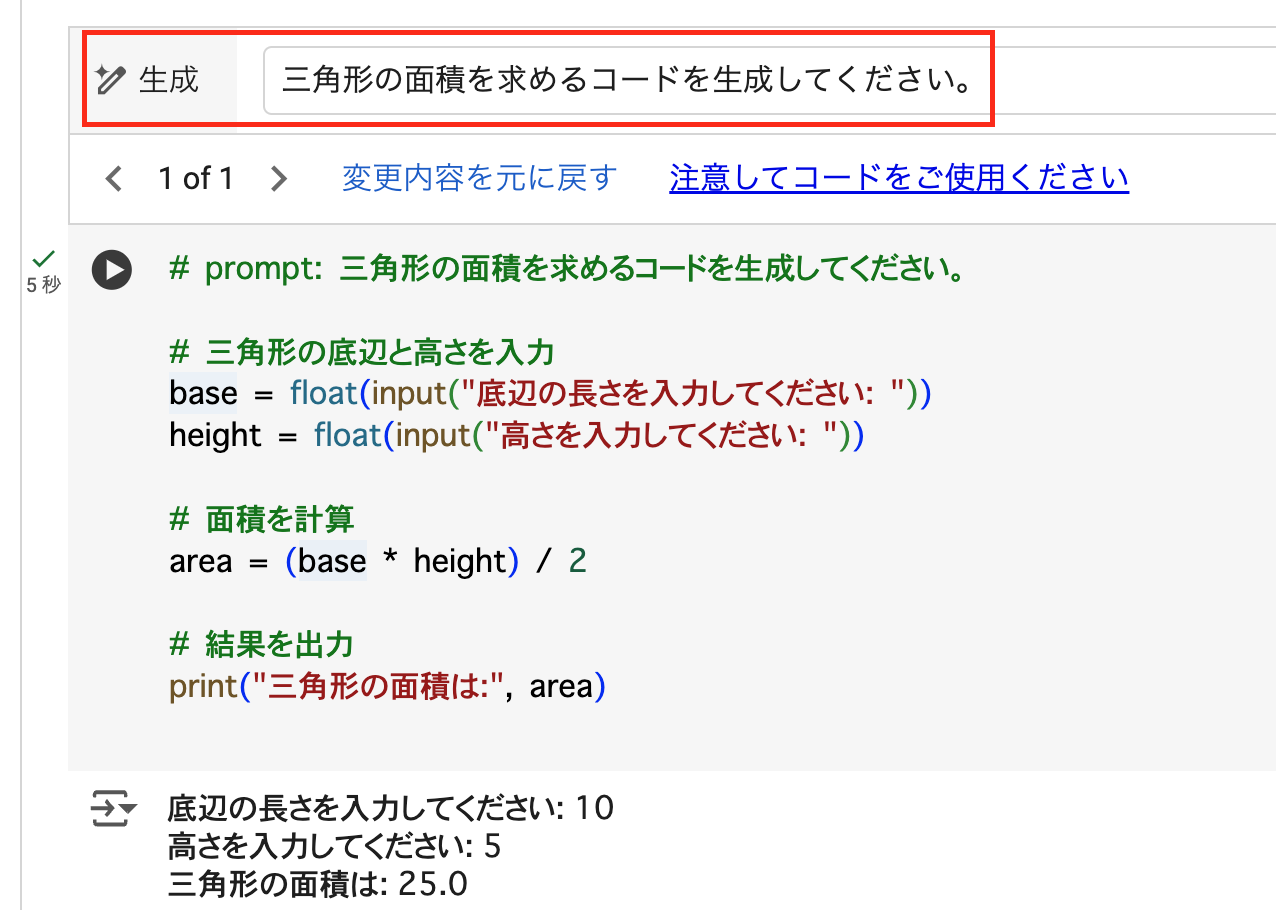
- 私が使い始めた頃はなかったのですが、最近は生成AIを使ったコード生成も可能となり、より便利になりました。 🪄三角形の面積を求めるコードを生成してください。
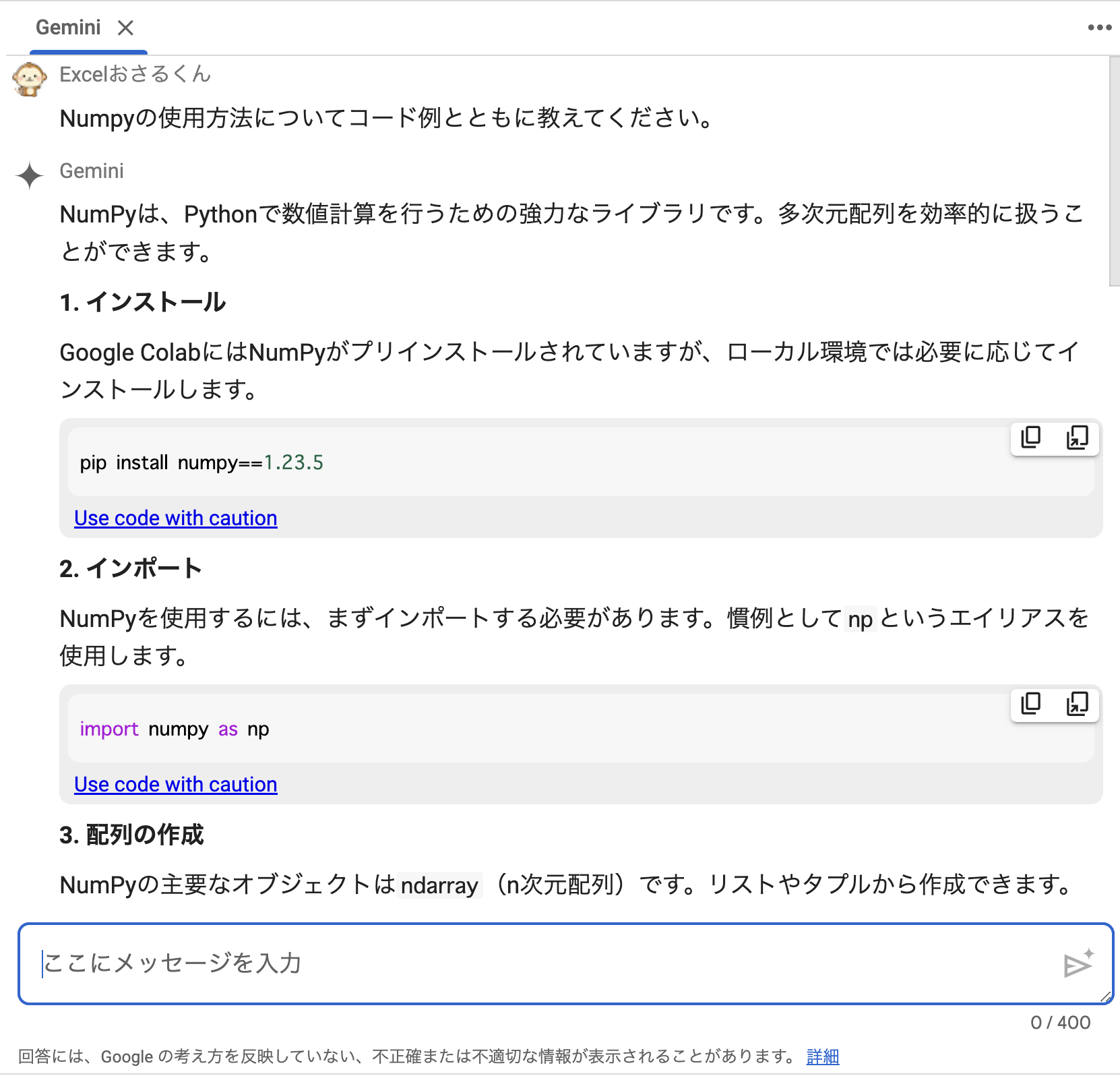
- Googleの生成AIであるGeminiを使って質問することも出来ます。
- テキストセルを使えばマークダウン形式でノートを書いていくことも可能です。
左側が入力画面、右側がプレビュー画面です。
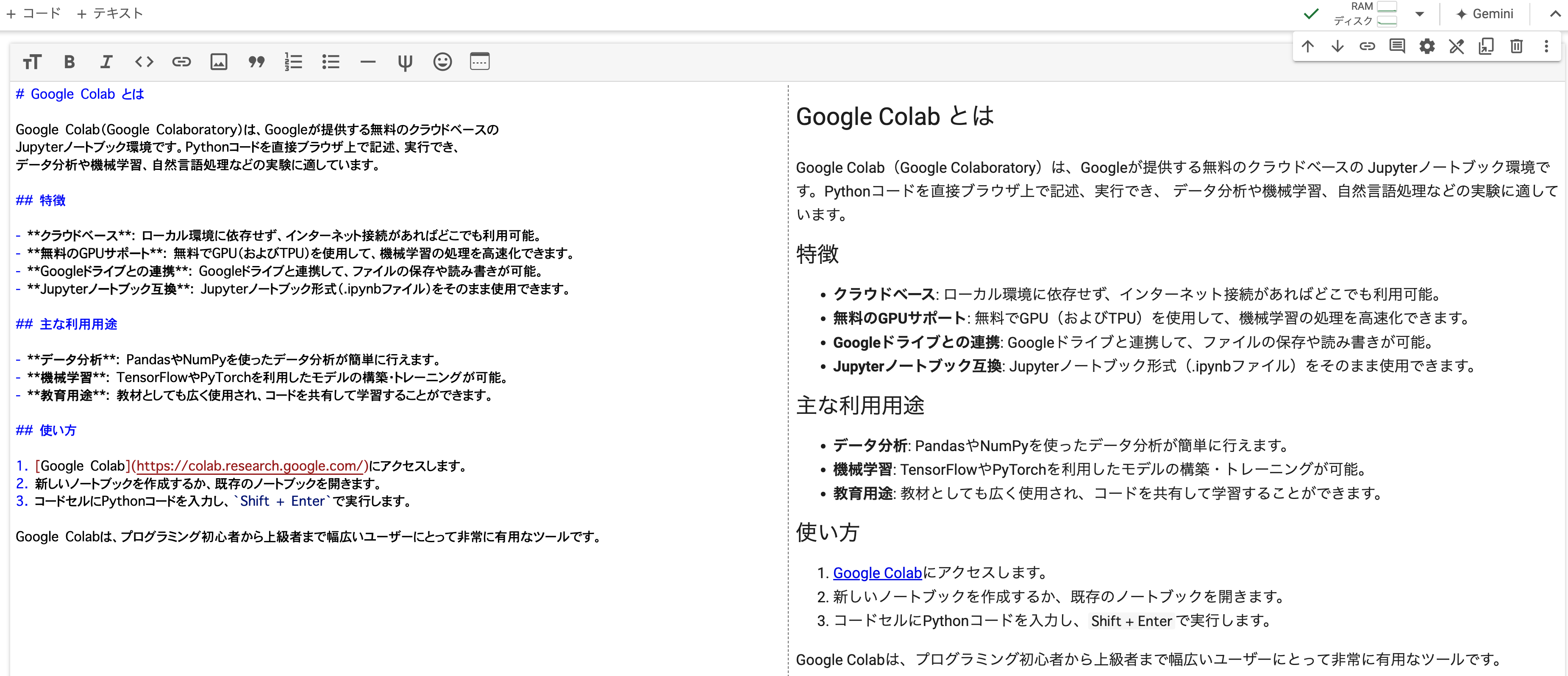
プレビューは横だけでなく縦に並べることもできます。
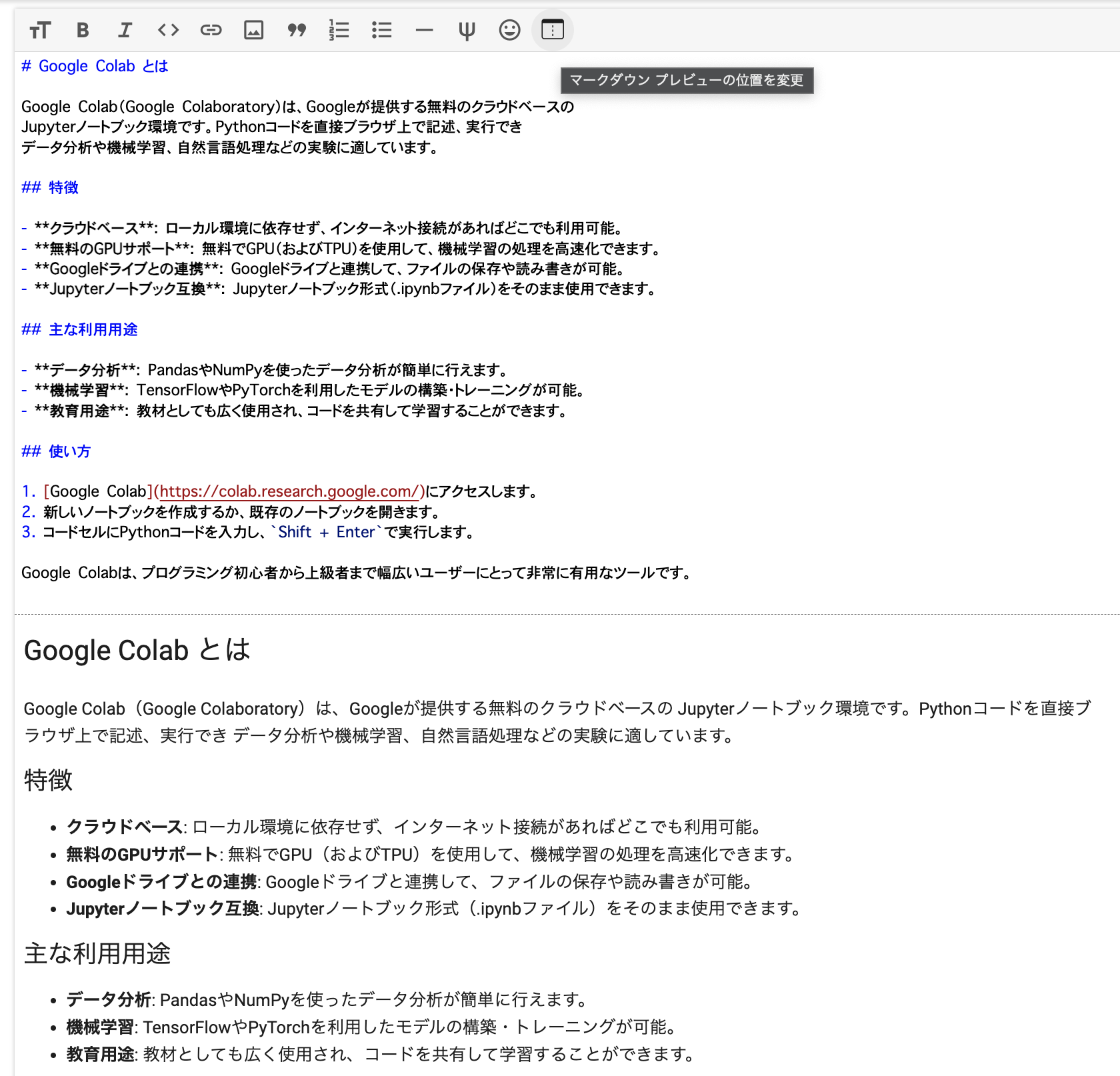
コードセルとテキストセルの組み合わせてインタラクティブなドキュメントを作成できます。
これによって、コードの実行結果と解説文を一つのドキュメント内で直接組み合わせることができ、学習ノートや簡単なプレゼンテーション資料の作成も可能となっています。
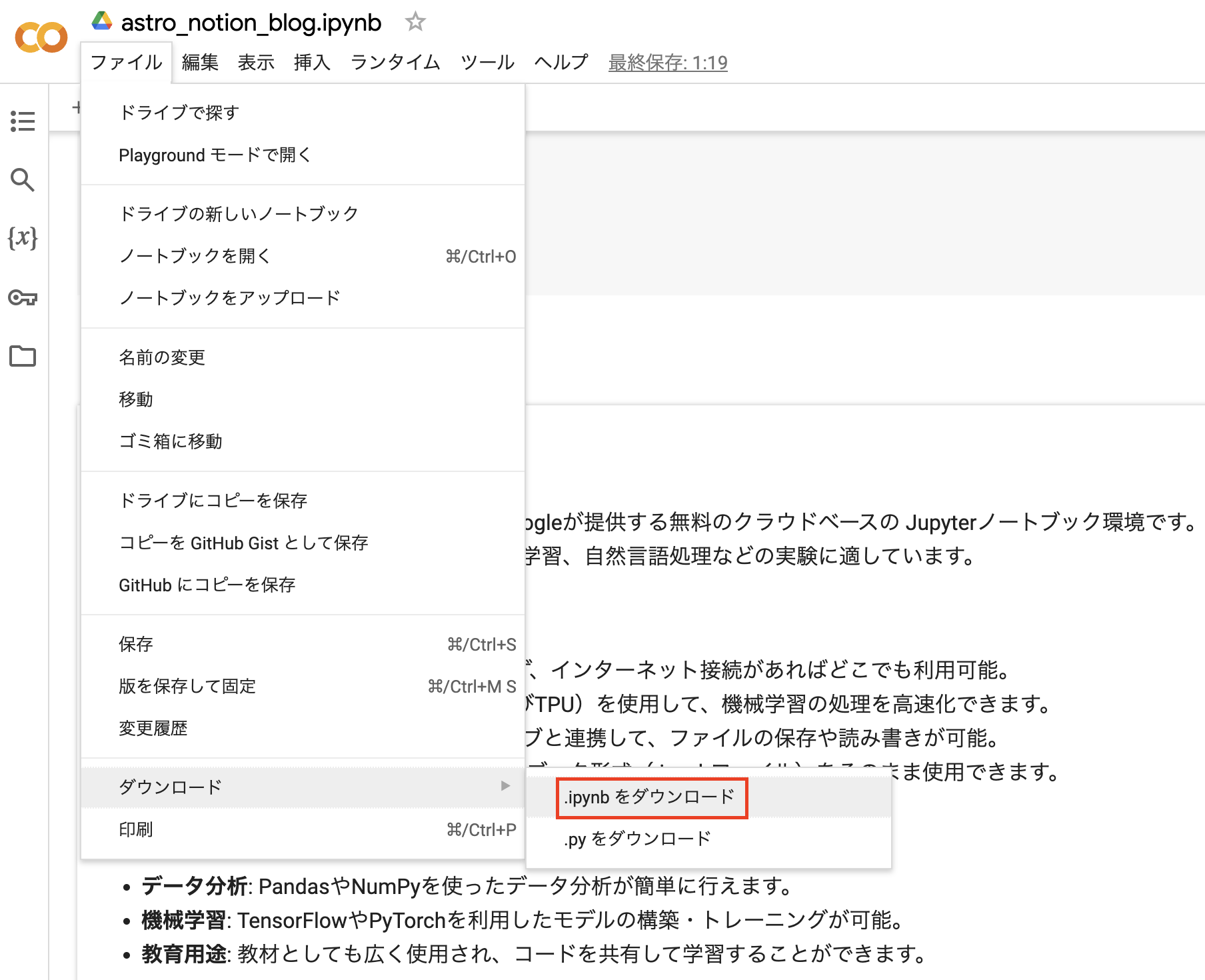
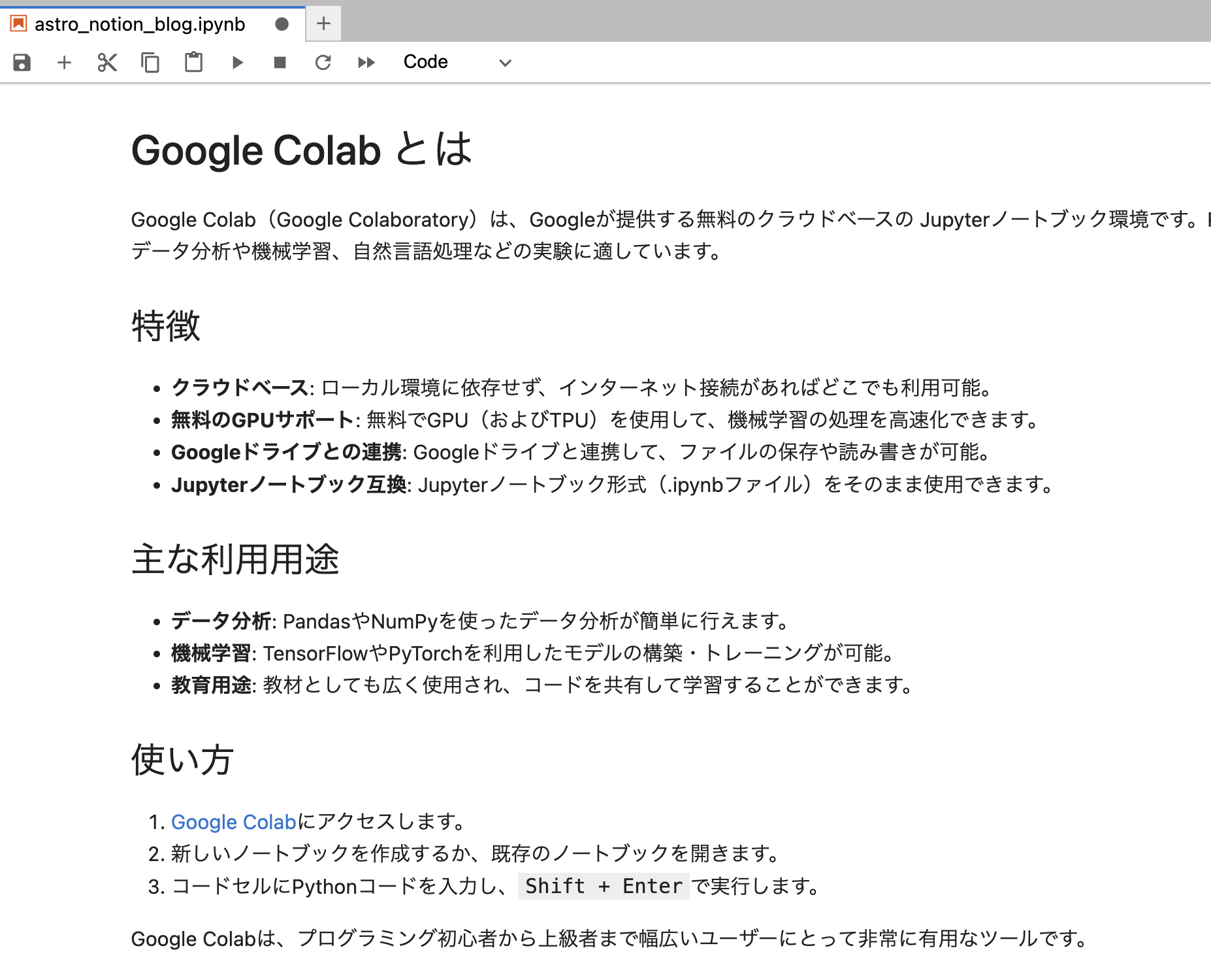
- ノートブックのダウンロード
ipynb形式で保存すればJupyter Labの環境で開くことも可能です。
- ノートブックの自動保存
Googleドキュメントやスプレッドシート同様にノートブックは自動保存されます。

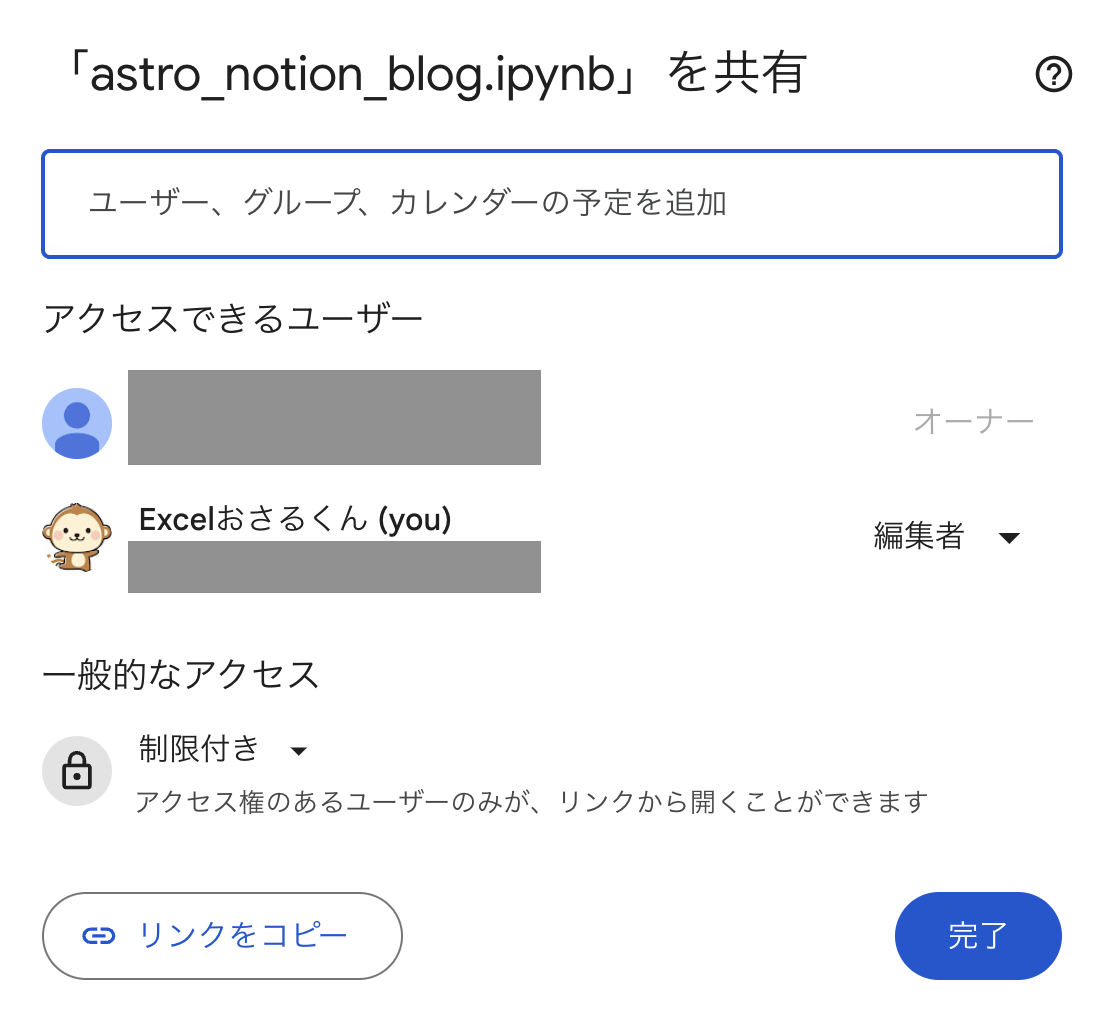
- ノートブックの共有機能
アクセスできるユーザーを限定した上で、編集・閲覧権限などを付与することができます。
- 追加ライブラリのインストール
pip freezeコマンドでインストール済みのライブラリを確認できます。
必要に応じて追加のライブラリをインストールすることも可能です。
seleniumをインストールし、本ブログのタイトルを取得してみました。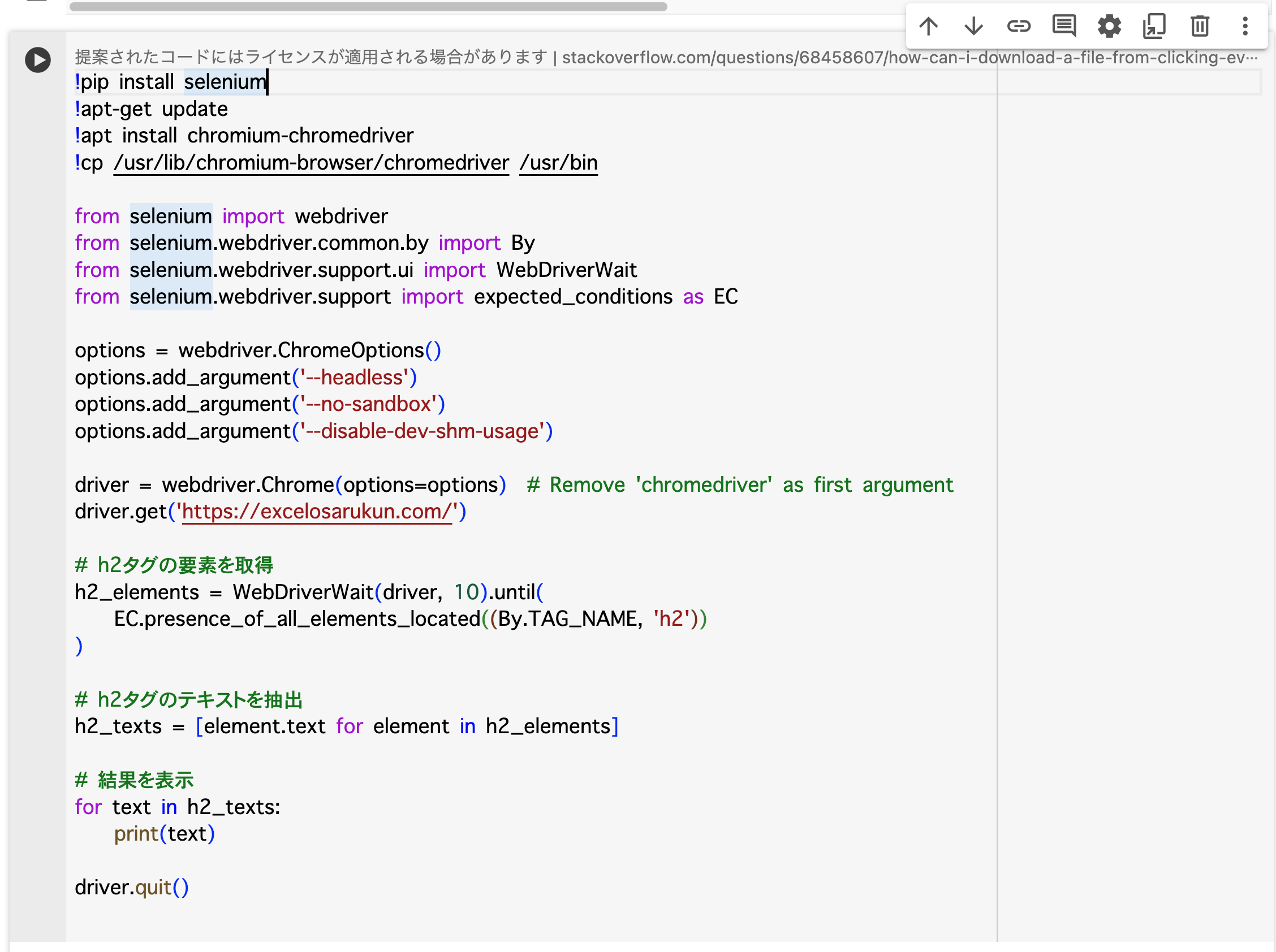

Google Colabの各種設定
- ツールの設定から様々な変更が可能です。
- 画面モードの切り替え
lightモード

darkモード
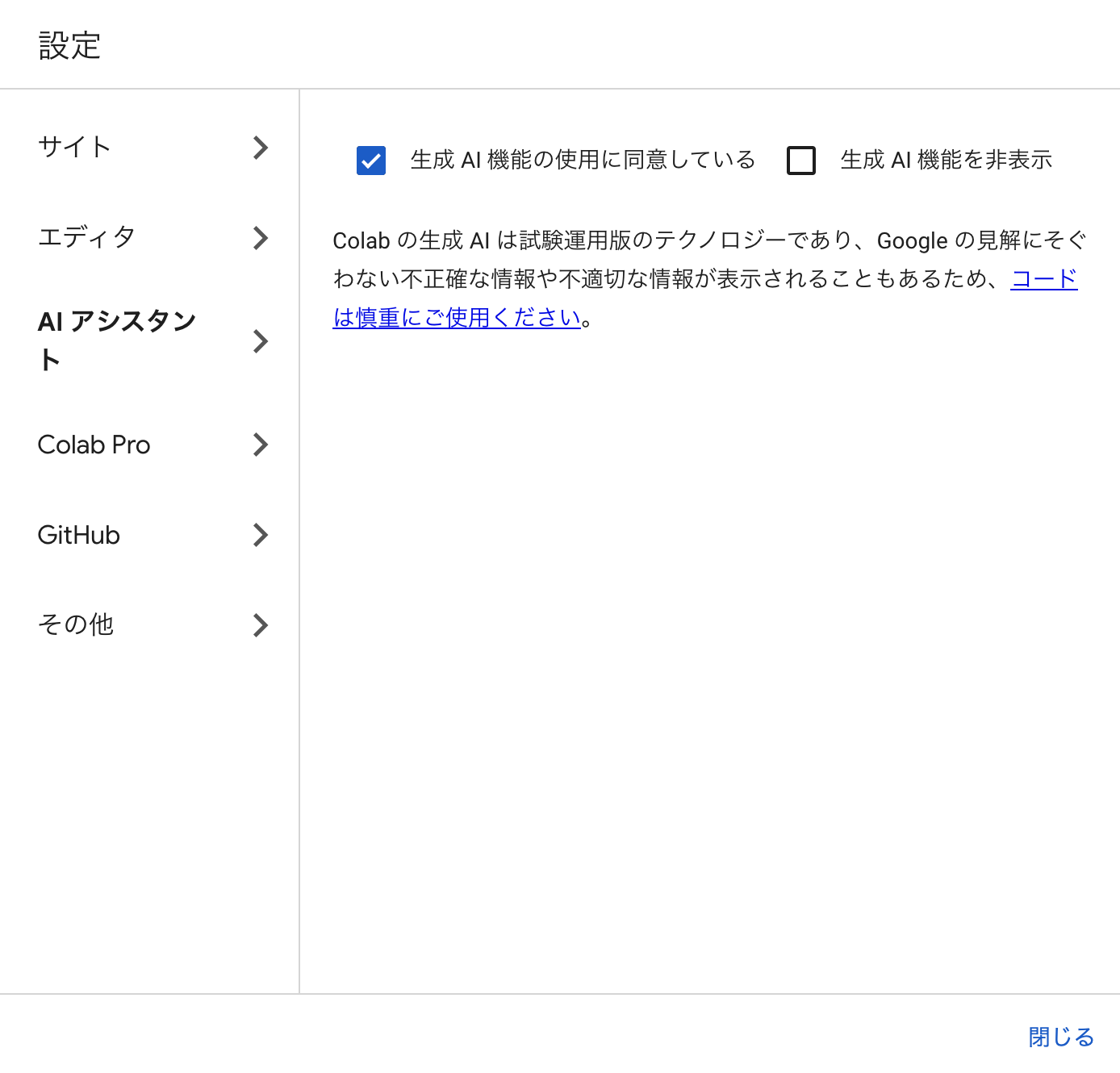
- 生成AI機能の使用
- GitHubアカウントとの連携
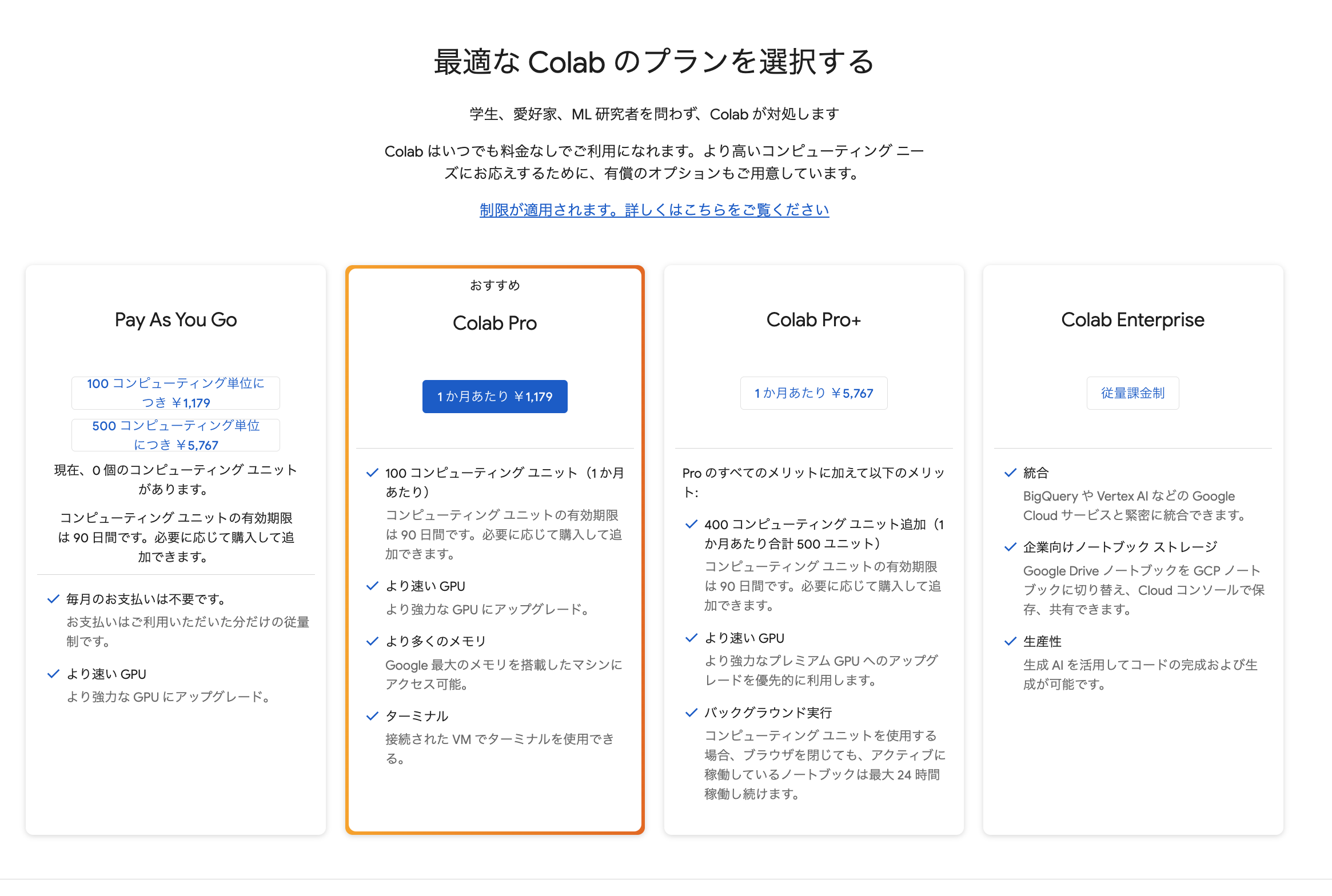
- Colabのプランの変更
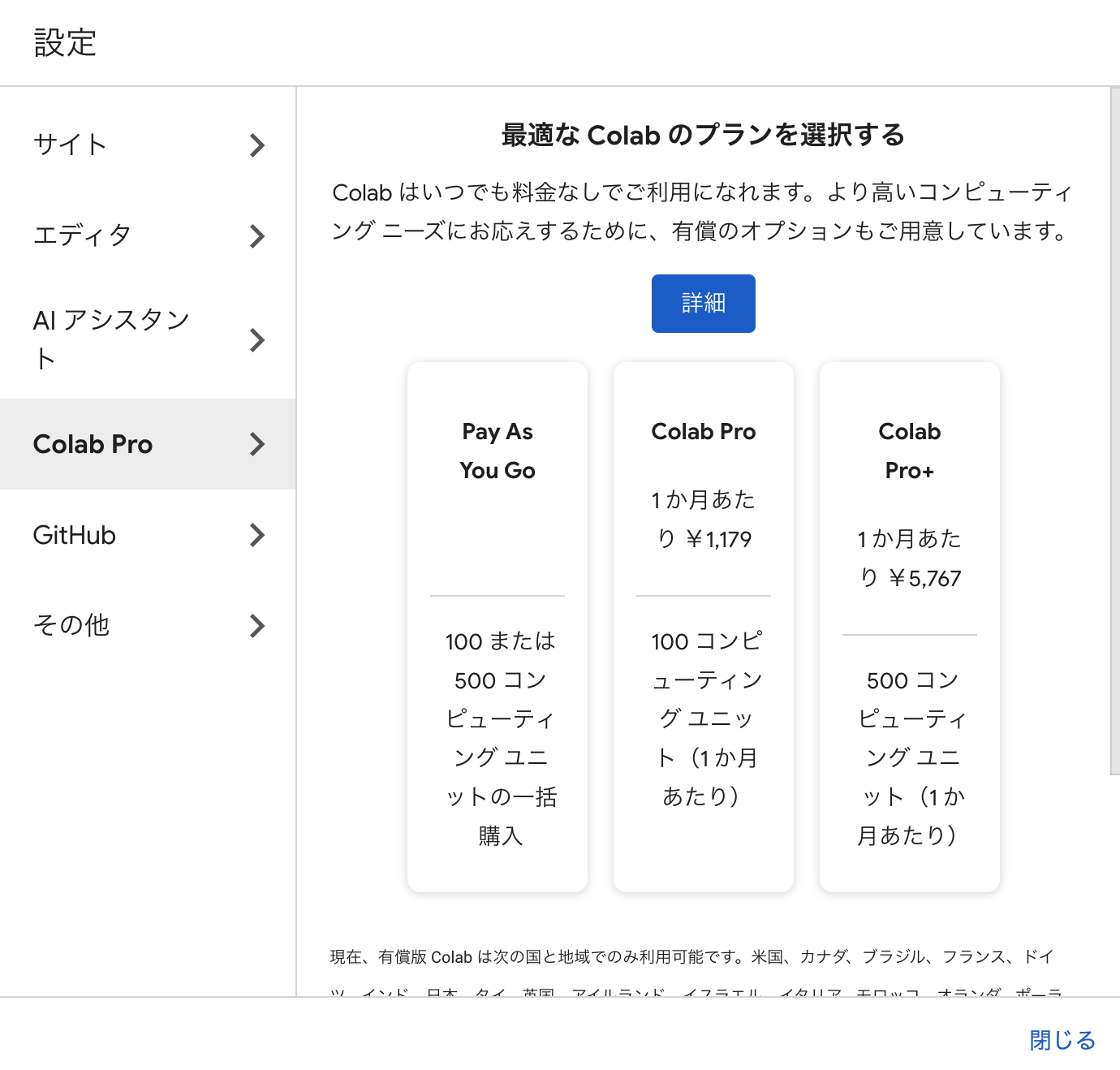
※詳細ページでそれぞれのプランを確認できます。
- Colabの注目すべき機能の一つが、GPUやTPUなどの高性能計算リソースへのアクセスです。特に計算負荷の高い機械学習のタスクにおいて重要で、Colabでは基本は無料で利用できます。
- 有料プランへ変更することで、より速いGPUやより多くのメモリも利用可能です。
- その他お遊び要素もあります😊
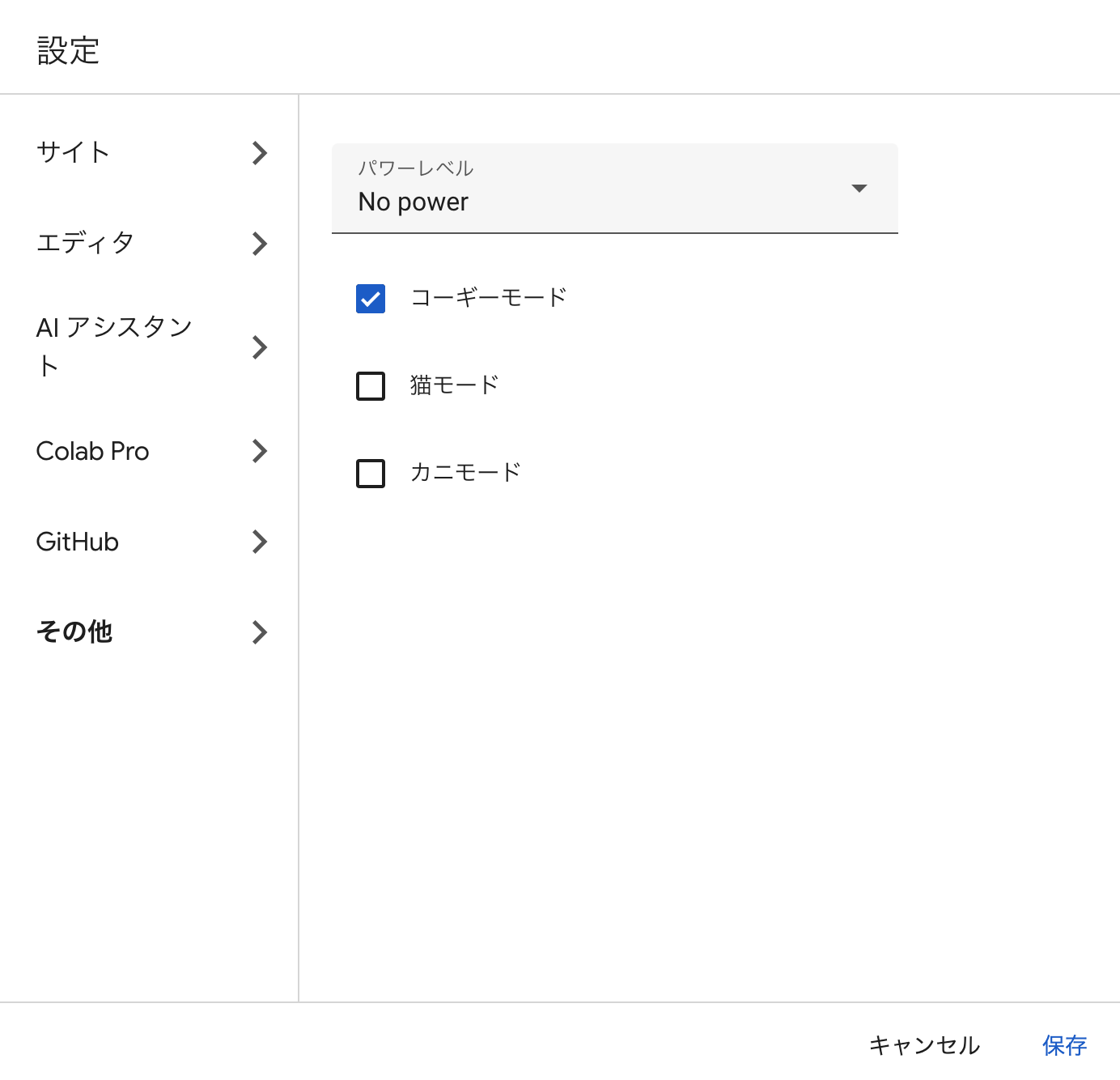
コーギーモード
猫モード
カニモード
Some power
Many power
入力するたびに火花が飛びます!
ここまでGoogle Colabで環境構築し、コードを実行する方法、そして、便利な各種設定について見てきました。
Google ColabはPython初心者の方にも配慮されており非常に使い勝手の良い開発環境です。

次のセクションでは、Google Colabのもう一つの大きな魅力であるGPUとTPUのリソースの活用例を見ていきましょう。
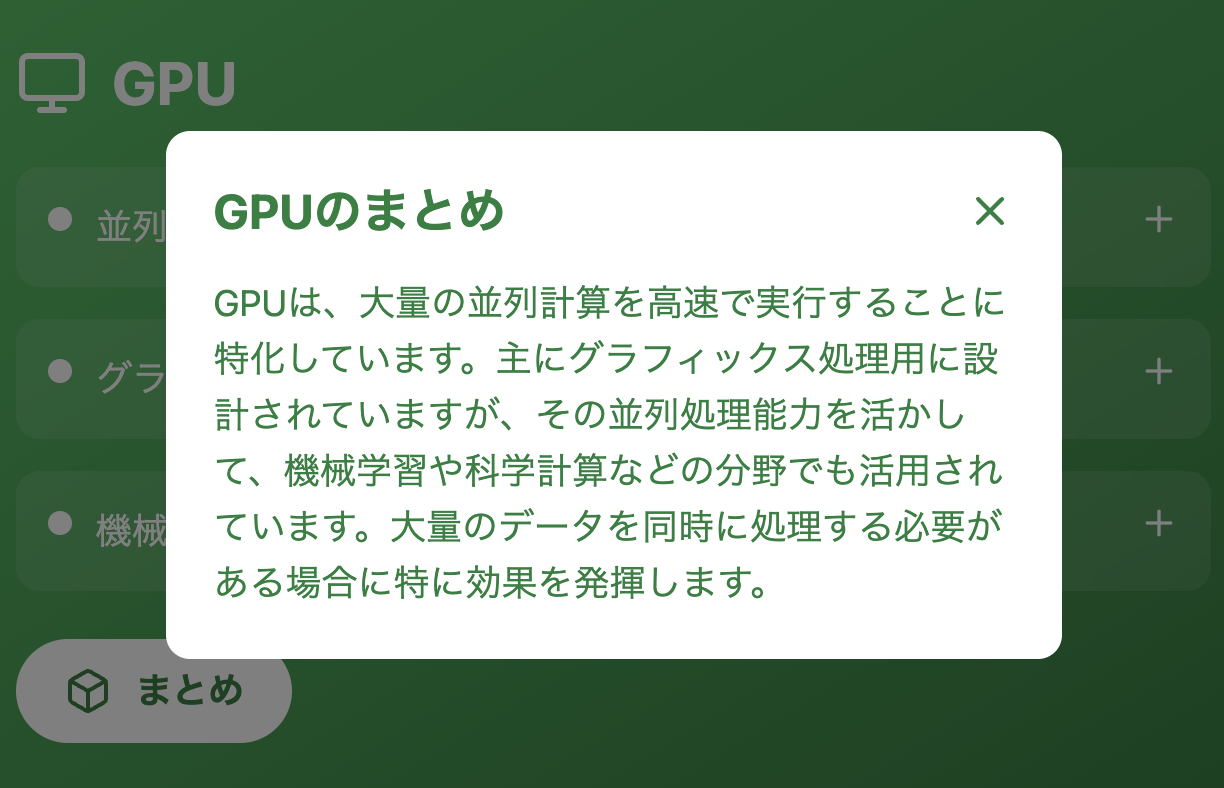
4️⃣ GPUとTPUのリソースの活用
Google Colabを利用することで、高度な計算も気軽に実行できます。
GPUやTPUを活用することで、通常のパソコンでは時間がかかるような計算も、迅速かつ効率的に行うことが可能になります。
CPUとGPUの違い
機械学習では行列演算を使うことが多いのでGPUが適しています。
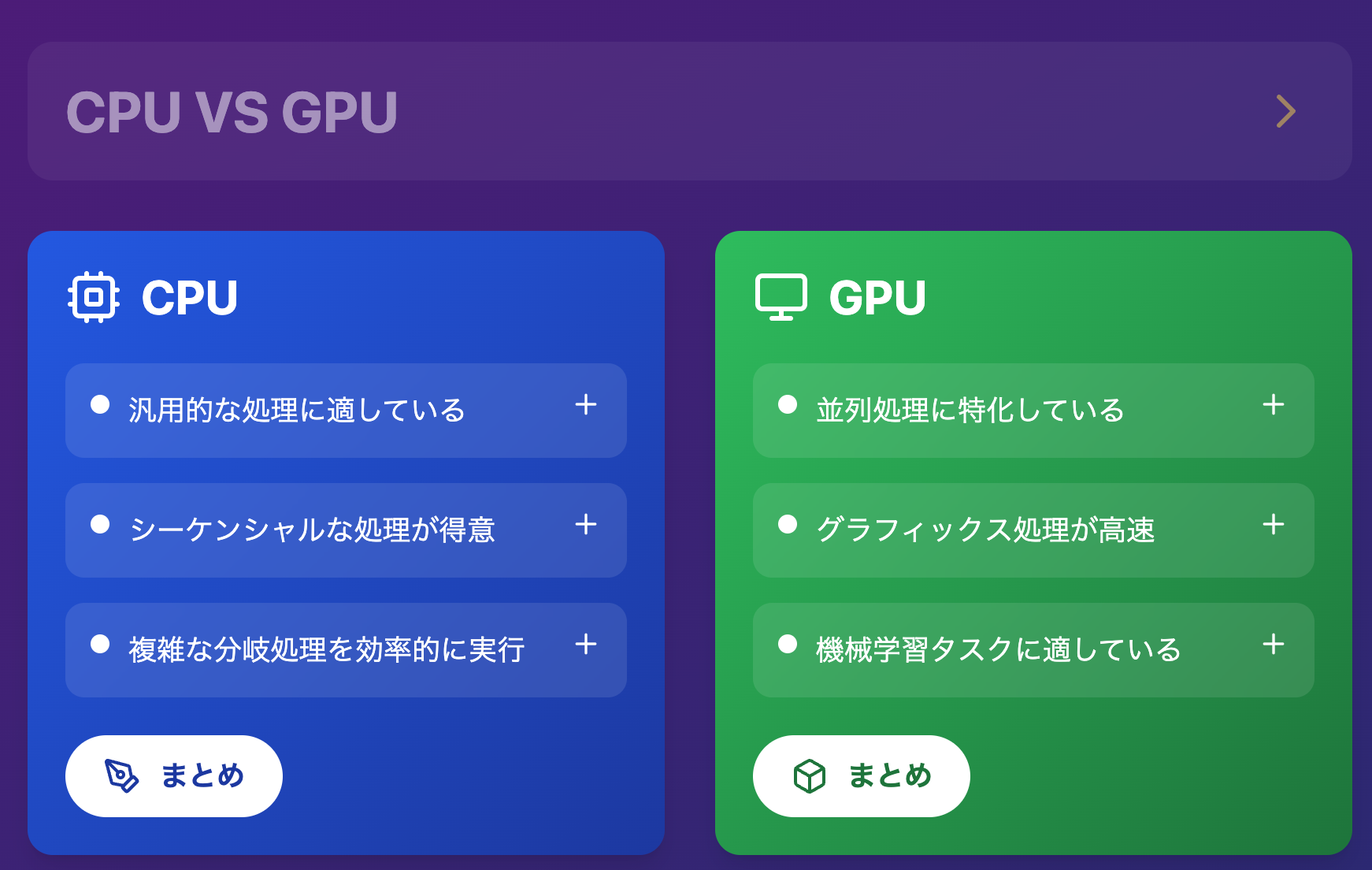
CPU
汎用性が高く、様々な処理を柔軟にこなすことが出来ます。

GPU
大量のデータを同時に処理する必要がある場合に効果を発揮します。
CPUとGPUを例えるなら…
CPU:スポーツカー

- スポーツカーには一度に沢山の人は乗れません、すわなち処理速度は早いですが複数の処理を同時に行うのは苦手です。
- コンピュータにおける通常の処理ではCPUを使うことが多いです。
GPU:バス

- バスには複数の人が乗ることができます。一つ一つのコアの処理速度はCPUより遅いですが複数の処理を同時に行えます。
- 何千、何万という同じような処理を行う場合はGPUの出番です。
GPUとTPUの違い
GPU(Graphics Processing Unit)とTPU(Tensor Processing Unit)の違いを表にまとめました。
| 項目 | GPU | TPU |
|---|---|---|
| 開発者 | NVIDIA、AMDなどの半導体メーカー | |
| 主な用途 | ゲーム、グラフィックス処理、機械学習、科学計算 | 機械学習、特にディープラーニングモデルの推論 |
| アーキテクチャ | マルチコアプロセッサ、並列処理に優れる | 行列計算に特化したアーキテクチャ |
| パフォーマンス | 高い並列計算性能(特に浮動小数点演算) | 高速な行列演算、特に深層学習モデル での効率が高い |
| メモリ | 大容量のGDDRメモリを搭載 | 高帯域幅メモリ(HBM)を使用 |
| 主なフレームワーク | CUDA、OpenCL、TensorFlow、PyTorch | TensorFlow |
| エネルギー効率 | 高性能だが、消費電力も高い | 機械学習モデルの推論タスクにおいて高効率 |
| 柔軟性 | 汎用性が高く、幅広い計算タスクに対応 | 機械学習、特にディープラーニングに特化 |
| コスト | 一般的に高価 | 特定の用途に最適化されており、利用に はコストがかかるが、Google Cloudでの 利用が可能 |
- GPUは先ほど説明した通り、複数の処理を同時に行う際に適しており、特に並列処理に優れています。
- TPUはGoogleが機械学習、特にディープラーニングの推論作業を高速化するために特別に設計したプロセッサのことです。TPUは主にTensorFlow向けに最適化されており、特定のディープラーニングタスクに非常に効率的です。(ただし、用途が限定されるため、GPUほど汎用性はありません。)
Google ColabでGPUとTPUを使用するには?
- GPUやTPUはランタイムのタイプを変更を選択
画面右上にあるRAM・ディスク横の🔽から変更が可能です。
- ランタイムのタイプの一覧表
プログラミング言語はPython3とRから選択できます。
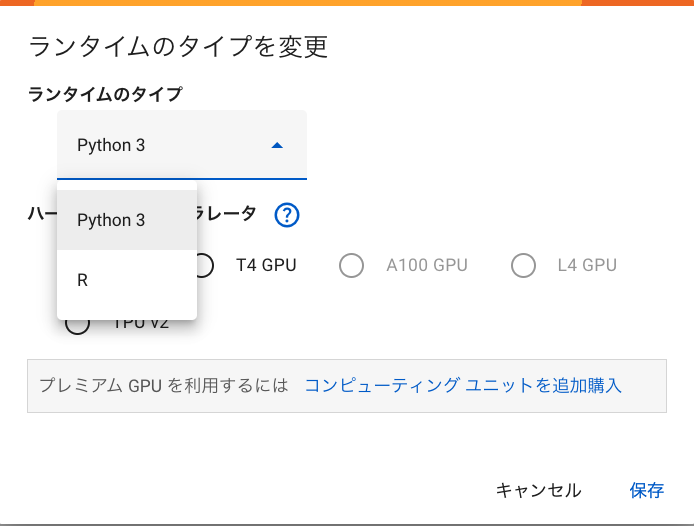
ランタイムのタイプ 説明 主な用途 Python 3 最新のPython 3.xシリーズを使用した
ランタイム環境。Pythonは汎用的な
プログラミング言語であり、データ
分析、機械学習、Web開発など広範な
用途に使用されます。データサイエンス、機械学習、
Webアプリケーション開発R Rは統計計算とグラフィックスに特化した
プログラミング言語です。特にデータ
分析や可視化に強みがあります。統計分析、データ可視化、
データサイエンス - ハードウェア アクセラレータから選択します。
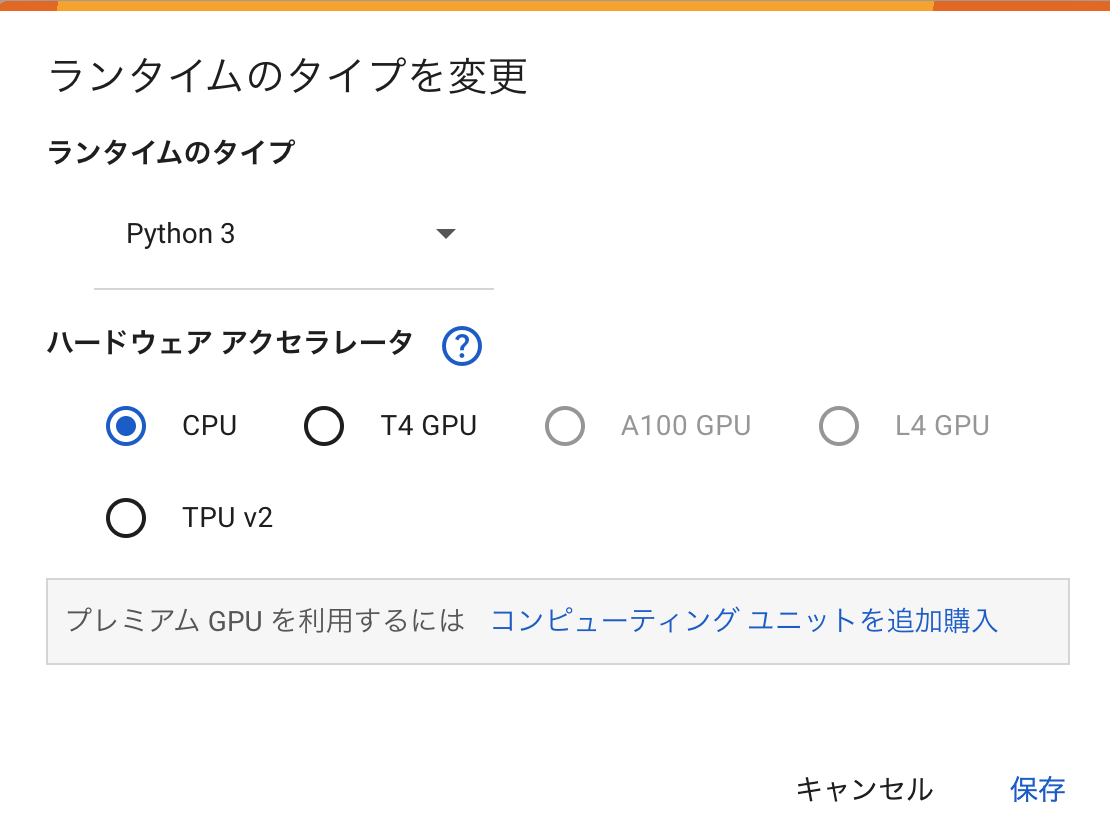
ハードウェア
アクセラレータ説明 主な用途 CPU 一般的なコンピュータのプロセッサーで、
すべてのタスクを実行できますが、特に
特定の処理に最適化されていません。基本的な計算、一般的なタスク T4 GPU NVIDIAのTuringアーキテクチャに基づく
GPUで、AI/機械学習やグラフィックス
処理に優れています。機械学習、推論、データセンター A100 GPU NVIDIAのAmpereアーキテクチャに基づく
高性能GPUで、深層学習やAIのトレーニン
グに最適化されています。深層学習トレーニング、AIモデリング L4 GPU NVIDIAの次世代GPUで、特に低レイテン
シーの推論やビデオ処理に焦点を当てて
います。ビデオ処理、低レイテンシー推論 TPU v2 Googleが開発した特定用途向け集積回路
(ASIC)で、機械学習モデルのトレーニ
ングと推論に特化しています。機械学習、特にTensorFlowモデル
CPU・GPU・TPUの処理速度の比較
- 今回の処理速度比較に用いるコードは、TensorFlowとKerasを用いて、MNISTデータセットを使ったシンプルなニューラルネットワークモデルを構築し、トレーニングするものです。
- トレーニングにかかった時間を測定します。
コードの内容とその処理については以下をご覧ください。
1. データセットのロード
- MNISTデータセット: 手書きの数字(0から9)の画像データセットで、訓練用に60,000枚、テスト用に10,000枚の画像が含まれています。画像は28x28ピクセルのグレースケールです。


- 前処理: 画像データを0から1の範囲に正規化しています。これは、各ピクセルの値を255で割ることで実現しています。
2. モデルの定義
- KerasのSequential APIを使用してモデルを構築しています。以下のレイヤーで構成されています。
- Flattenレイヤー: 28x28ピクセルの画像を一列に並べて入力データをフラット化します。
- Denseレイヤー: 512個のニューロンを持ち、活性化関数にReLUを使用しています。これは全結合層で、入力データを次の層に渡します。
- Dropoutレイヤー: 0.2の割合でランダムにニューロンを無効化します。これは過学習を防ぐための正則化手法です。
- 出力層(Denseレイヤー): 10個のニューロンを持ち、活性化関数にSoftmaxを使用しています。これは、各クラス(数字0から9)の確率を出力します。
3. モデルのコンパイル
- オプティマイザ: Adamオプティマイザを使用しています。これは、学習率の調整を自動化するアルゴリズムです。
- 損失関数:
sparse_categorical_crossentropyを使用しています。これは、ラベルが整数値である場合に適した損失関数です。 - 評価指標: 正解率(accuracy)を評価指標として設定しています。
4. モデルのトレーニング
- fitメソッドを使用してモデルをトレーニングしています。エポック数は5で、訓練データとテストデータを用いてモデルの学習と評価を行います。
5. ハードウェアごとの実行
- CPU、GPU、TPUそれぞれの環境でモデルをトレーニングし、処理時間を計測しています。これにより、各ハードウェアの性能を比較することができます。
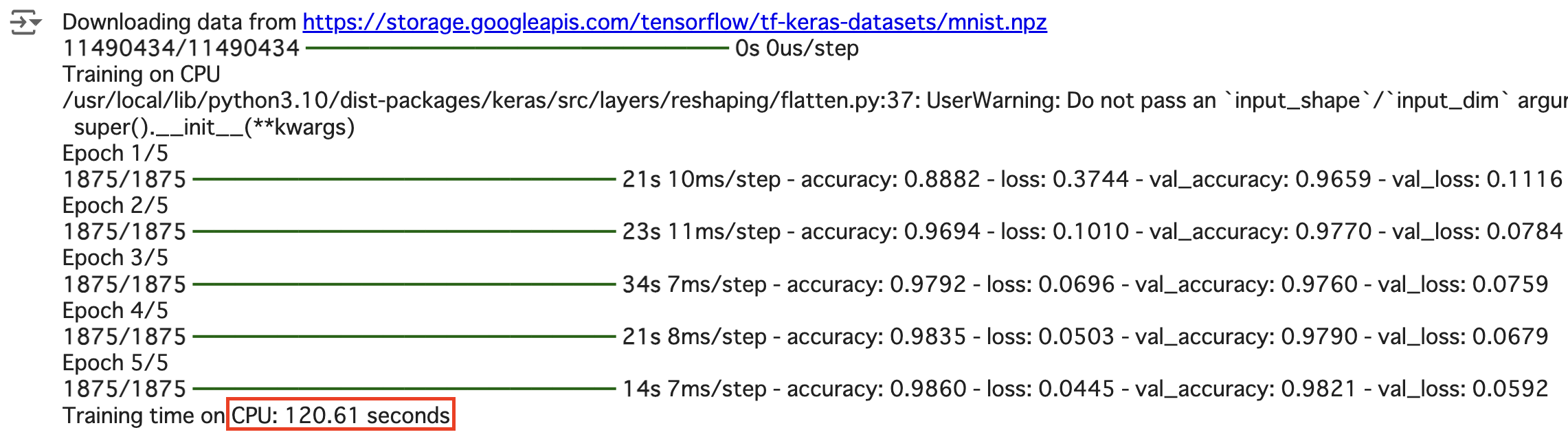
CPU
- CPU: 120.61 seconds
import tensorflow as tf
from tensorflow import keras
import time
# データセットのロード
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# モデルの定義
def create_model():
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# CPUでのトレーニング
print("Training on CPU")
cpu_strategy = tf.distribute.get_strategy()
with cpu_strategy.scope():
model = create_model()
start_time = time.time()
model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
end_time = time.time()
print(f"Training time on CPU: {end_time - start_time:.2f} seconds")
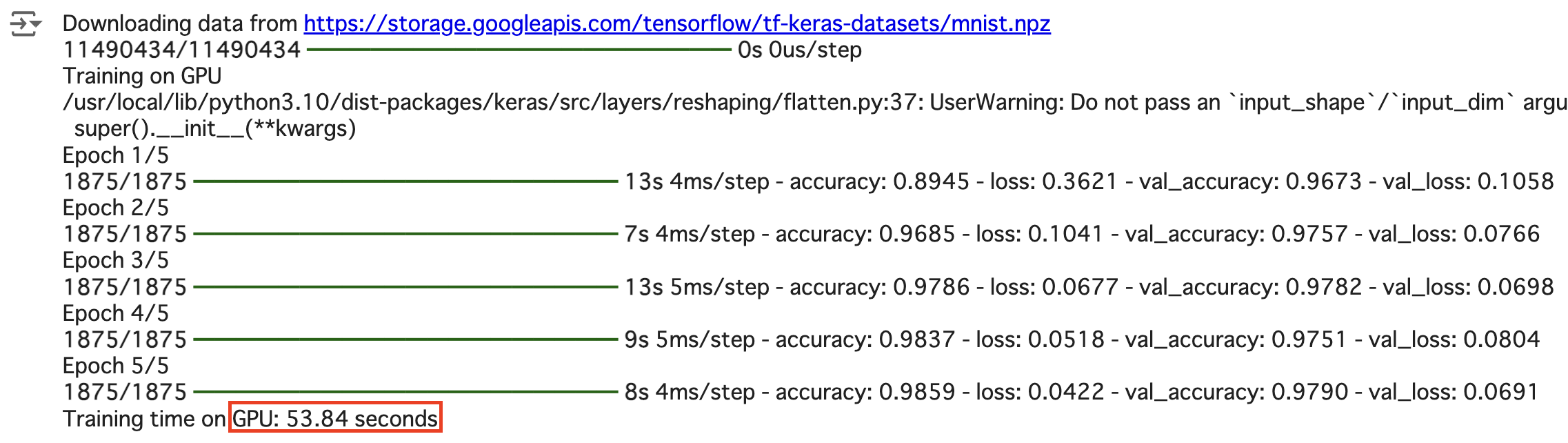
GPU
- GPU: 53.84 seconds
import tensorflow as tf
from tensorflow import keras
import time
# データセットのロード
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# モデルの定義
def create_model():
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# GPUでのトレーニング
if tf.config.list_physical_devices('GPU'):
print("Training on GPU")
gpu_strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0")
with gpu_strategy.scope():
model = create_model()
start_time = time.time()
model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
end_time = time.time()
print(f"Training time on GPU: {end_time - start_time:.2f} seconds")
else:
print("No GPU found.")
TPU
- TPU: 69.99 seconds

import tensorflow as tf
from tensorflow import keras
import time
# データセットのロード
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# モデルの定義
def create_model():
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# TPUでのトレーニング
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
tpu_strategy = tf.distribute.TPUStrategy(tpu)
print("Training on TPU")
with tpu_strategy.scope():
model = create_model()
start_time = time.time()
model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
end_time = time.time()
print(f"Training time on TPU: {end_time - start_time:.2f} seconds")
except ValueError:
print("No TPU found.")
実行結果
| ハードウェアアクセラレーター | トレーニング時間(秒) | 考察 |
|---|---|---|
| CPU | 120.61 | CPUは一般的な計算処理に向いており、並列処理能力はGPUや TPUに比べて劣ります。そのため、ディープラーニングのような 大規模な計算が必要なタスクでは、トレーニング時間が長くなる 傾向があります。 |
| GPU(T4 GPU) | 53.84 | GPUは多数のコアを持ち、並列処理に優れているため、ディープ ラーニングのトレーニングに非常に適しています。今回の結果で も、CPUに比べて約半分の時間でトレーニングを完了しており、 GPUの効率性が示されています。 |
| TPU(TPU v2) | 69.99 | TPUはGoogleがディープラーニング専用に設計したハードウェア です。特に大規模なモデルやデータセットに対して効果を発揮し ます。今回の結果では、GPUよりもやや遅い結果となっています が、これはモデルの規模やデータセットのサイズが比較的小さい ためと考えられます。TPUは大規模なトレーニングでその真価を 発揮します。 |
総合的な評価
- 小規模なタスクでは、GPUが最も効率的であることが示されました。これは、GPUが持つ並列処理能力が、今回のような比較的シンプルなモデルのトレーニングに最適であるためです。
- 大規模なタスクや大規模データセットに対しては、TPUがより効果的である可能性があります。TPUは、特にGoogleのクラウド環境での大規模なディープラーニングタスクに最適化されています。
- CPUは、ディープラーニングのトレーニングにはあまり向いていないことが確認できましたが、手軽に利用できるため、軽量なタスクや開発段階でのテストには適しています。
この結果を基に、使用するハードウェアを選択する際には、モデルの規模やデータセットのサイズ、トレーニング時間の要件を考慮することが重要です。

Google Colabではモデルのトレーニングのようなハードウェアのスペックを必要とする重たい処理に適した、GPU・TPUを無料で提供してもらえるため、機械学習において使わない手はないと考えます。
5️⃣ Google Colabからの卒業
これまでGoogle Colabの環境構築や利用方法、その特徴について見てきました。
Google Colabは大変有用な環境なのですが、私がメインの開発環境としなかった理由は大きく2つありました。
- Google Colab利用におけるインターネット接続の問題
- Google ColabとVSCodeの操作性比較
詳しく見ていきます。

Google Colab利用におけるインターネット接続の問題
- Google Colabはブラウザ上で動作するため当然インターネット接続が必須となっています。
- 外出先などでコーディングする際にネット環境がなかったり、ネットが不安定であると実行に時間を要するという問題がありました。
- Colabはデータをクラウド上にアップして利用するため、データのプライバシーに注意が必要です。特に機密性の高いデータを扱う場合には、適切なセキュリティ対策が必要となりました。
- また、Chromeの更新やPCの更新がかかるとエラーによってうまく動作しないことがありました。(数日で解消されるのがほとんどでしたが…)
- さらに無料プランでは長時間の使用に制限があり、ランタイムの接続が解除されてしまうという問題もありました。

 🔬Colab ではノートブックはどのくらいの時間動作しますか?
🔬Colab ではノートブックはどのくらいの時間動作しますか?- Colab では、インタラクティブ コンピューティングが優先されます。アイドル状態の場合、ランタイムはタイムアウトします。
- 料金がかからないバージョンの Colab の場合、ノートブックは可用性と使用パターンに応じて最長で 12 時間実行できます。Colab Pro、Pro+、従量課金制では、コンピューティング ユニットの残量に応じてコンピューティングの可用性が高くなります。
- ノートブックは通常、可用性と使用パターンに応じて最長で 12 時間実行できます。Pro、Pro+、従量課金制プランでは、利用可能なコンピューティング ユニットを使い切るとバックエンドが終了する可能性があります。
- Colab Pro+ では、十分なコンピューティング ユニットがあれば、最長 24 時間連続でコードを実行できます。アイドル タイムアウトは、コードの実行が終了した場合にのみ適用されます。
- GCP Marketplace で専用の VM を購入すると、ランタイムの制限とアイドル タイムアウトを完全に緩和できます。
Google ColabとVSCodeの操作性比較
前回ご紹介させていただいたVSCodeでは拡張機能によりCSVやExcel、PDFをエディター上で開くことができたり、充実した補完機能で入力をサポートしてくれました。
それに比べるとGoogle Colabのエディターの機能は今ひとつな印象がありました。
🔻前回の記事はこちらから
📄![]() "Pythonの環境構築を振り返ります:第1回 - カレールウとAnaconda!?”
"Pythonの環境構築を振り返ります:第1回 - カレールウとAnaconda!?”
ただし、この点は私が使用していた頃から大きく改善されてきており、生成AIの導入によりサジェスト機能やコード生成、Geminiに直接質問できるなど非常に使い勝手が良くなっております!
私もこの記事を書くに際し、久しぶりにGoogle Colabを触りあまりの快適さに驚いています笑
その他、クラウド環境でファイルを操作するということで以下のような問題もありました。
データの保存:
セッションが終了すると、ローカルのファイルシステムに保存されたデータが失われます。データの永続的な保存には、Google Driveや外部ストレージを使用する必要がありますが、それも手動で設定しなければなりません。
ファイルアップロードの制限:
大きなファイルをアップロードする際に時間がかかることがあり、特にアップロードの途中でエラーが発生すると再試行が必要です。Googleドライブの保存容量も無料プランの場合15GB上限という制約もあり注意が必要です。
Google Colabは、Pythonの入門段階や機械学習において、素晴らしい環境だと思います。
特に初学者にとって、環境構築の手間を取り去って、直接学習に集中できる環境を提供してくれます。
一方で本セクションの理由から、若干の使いづらさもあり、現在私はGoogle Colabを積極的に使わなくなりました。

6️⃣ おわりに
最新の状況を踏まえて書きたいことをとにかく書いていたら、予想以上に長くなってしまいました😅
今回はGoogle Colab編ということでこの辺りで締めさせていただきます。
最近では、GPUやメモリを大量に必要とするStable Diffusionなどの画像生成のためにGoogle Colabを利用されるケースもあると聞きます。
ぜひ本記事を参考にしてGoogle Colabの環境構築、操作方法の基本の理解を深めていただけましたら幸いです。

次回は、Dockerを使った環境構築に焦点を当てます。
Dockerは、プロジェクトのテスト環境、本番環境を容易に再現でき、チームでの開発において一貫性を保つことができるツールです。
皆さんのPython学習が、より豊かで効果的なものになるよう、引き続き情報を共有していきますので、どうぞお楽しみに!
この記事が良かったと思っていただけた方は、コメントといいね👍お待ちしています。